

一、Kafka部署¶
1.1 Kafka单点部署¶
1、下载kafka_2.13-3.2.1.tgz
下载地址:https://archive.apache.org/dist/kafka/3.2.1/kafka_2.13-3.2.1.tgz
2、在elk121节点上
| [root@elk121 ~]# tar xf kafka_2.13-3.2.1.tgz -C /es/softwares/ |
|---|
3、在elk121节点上创建符号连接
| [root@elk121 ~]# cd /es/softwares/ && ln -svf kafka_2.13-3.2.1 kafka |
|---|
4、在elk121节点上配置环境变量
说明:在部署完成zk的基础上进行添加
[root@elk121 softwares]# vim /etc/profile.d/kafka.sh
#!/bin/bash
export ZK_HOME=/es/softwares/zk
export PATH=$PATH:$ZK_HOME/bin
export KAFKA_HOME=/es/softwares/kafka
export PATH=$PATH:$KAFKA_HOME/bin
环境变量生效
| [root@elk121 softwares]# source /etc/profile.d/kafka.sh |
|---|
5、在elk121节点上修改配置文件
修改第24行内容
[root@elk121 ~]# vim /es/softwares/kafka/config/server.properties
…
…
broker.id=121
修改第62行内容
[root@elk121 ~]# vim /es/softwares/kafka/config/server.properties
…
…
log.dirs=/es/logs/kafka
修改第125行内容
[root@elk121 ~]# vim /es/softwares/kafka/config/server.properties
…
…
zookeeper.connect=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
修改完成后的内容如下:
[root@elk121 ~]# egrep -v "^$|^#" /es/softwares/kafka/config/server.properties
broker.id=121
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/es/logs/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
6、在elk121节点上启动kafka单点
[root@elk121 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk121 ~]# jps | grep Kafka
10313 Kafka
如果停止,执行以下命令即可
| [root@elk121 ~]# kafka-server-stop.sh |
|---|
补充说明:
如果出现以下问题

删除/tmp/kafka-logs/*文件即可
| [root@elk121 ~]# rm- rf /tmp/kafka-logs/* |
|---|
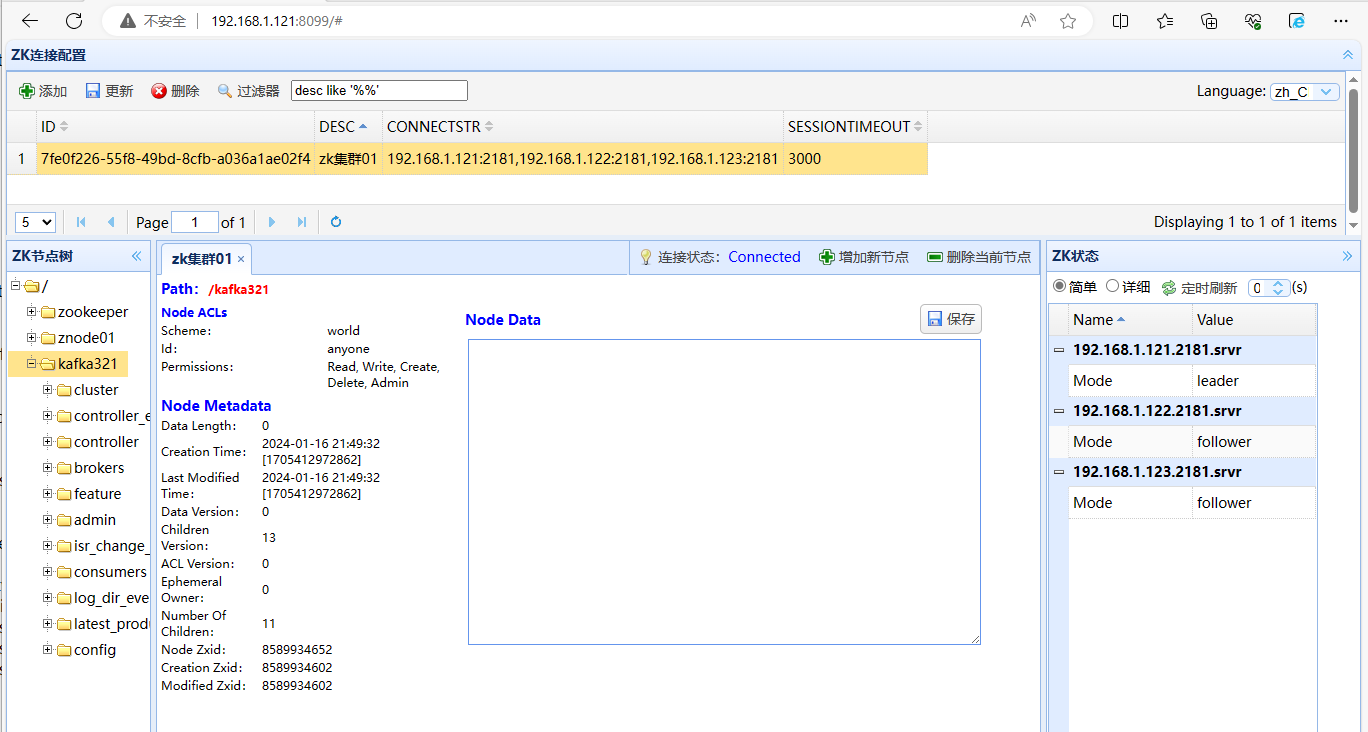
7、打开浏览器输入http://192.168.1.121:8099/进行访问,进行结果查看
1.2 Kafka集群部署¶
说明:这里Kafka集群部署是基于上面单点部署进行的
1、在elk121节点上停止kafka单点服务
| [root@elk121 ~]# kafka-server-stop.sh |
|---|
2、在elk121节点上修改配置文件
修改第24行内容
[root@elk121 ~]# vim /es/softwares/kafka/config/server.properties
…
…
broker.id=121
修改第62行内容
[root@elk121 ~]# vim /es/softwares/kafka/config/server.properties
…
…
log.dirs=/es/logs/kafka
修改第125行内容
[root@elk121 ~]# vim /es/softwares/kafka/config/server.properties
…
…
zookeeper.connect=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
修改完成后的内容如下:
[root@elk121 ~]# egrep -v "^$|^#" /es/softwares/kafka/config/server.properties
broker.id=121
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/es/logs/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
3、在elk121节点上同步kafka软件包相关文件
[root@elk121 ~]# data_rsync.sh /es/softwares/kafka
[root@elk121 ~]# data_rsync.sh /es/softwares/kafka_2.13-3.2.1/
[root@elk121 ~]# data_rsync.sh /etc/profile.d/kafka.sh
4、在elk122节点和elk123节点上修改配置文件
(1) 在elk122节点上修改配置文件
修改第24行内容
[root@elk122 ~]# vim /es/softwares/kafka/config/server.properties
…
…
broker.id=122
修改完成后,内容如下:
[root@elk122 ~]# egrep -v "^$|^#" /es/softwares/kafka/config/server.properties
broker.id=122
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/es/logs/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
(2) 在elk123节点上修改配置文件
[root@elk123 ~]# vim /es/softwares/kafka/config/server.properties
…
…
broker.id=123
修改完成后,内容如下:
[root@elk123 ~]# egrep -v "^$|^#" /es/softwares/kafka/config/server.properties
broker.id=123
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/es/logs/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0 group.initial.rebalance.delay.ms=0
5、所有节点启动kafka环境
[root@elk121 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk122 ~]# source /etc/profile.d/kafka.sh
[root@elk122 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
[root@elk123 ~]# source /etc/profile.d/kafka.sh
[root@elk123 ~]# kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
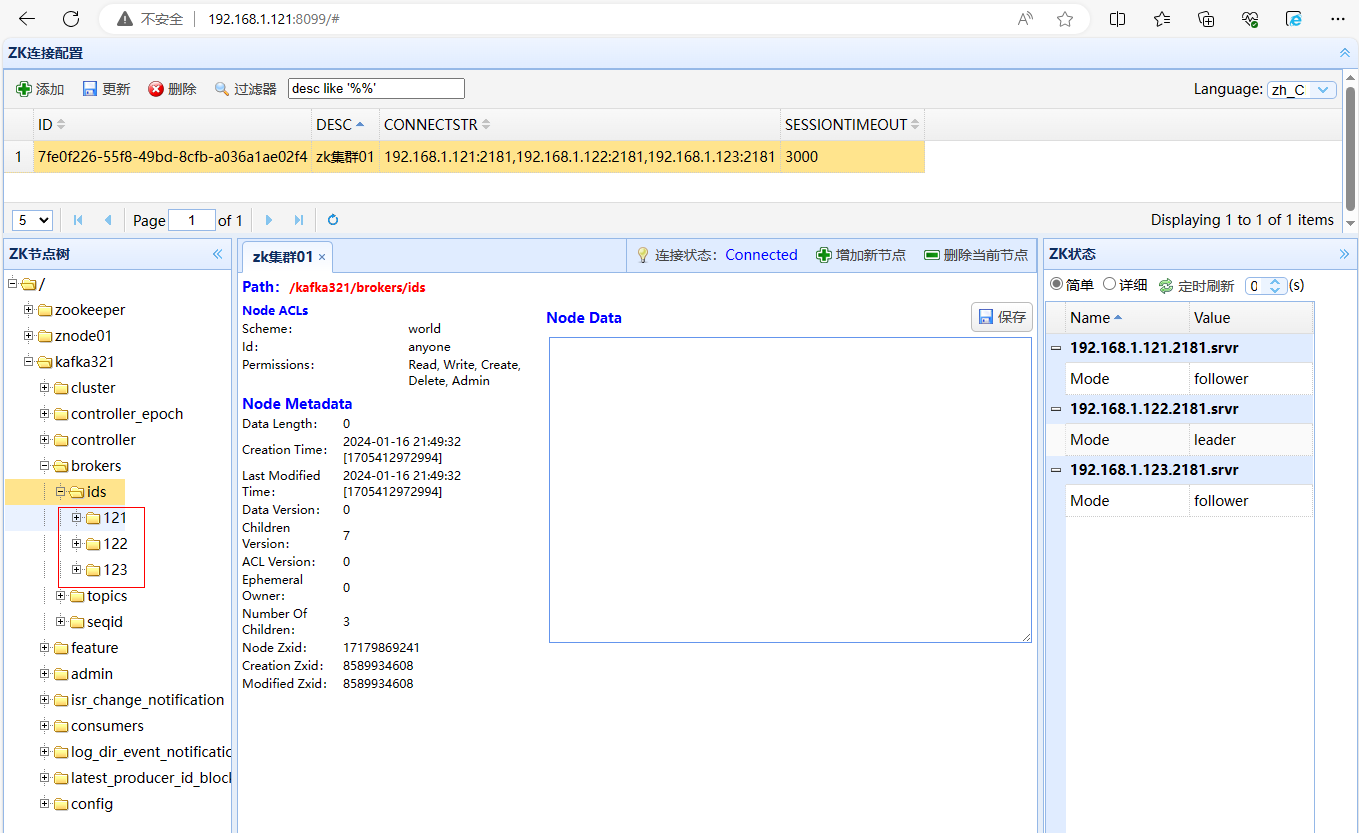
6、在elk121节点上查看zookeeper的源数据
[root@elk121 ~]# zkCli.sh -server 192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181
[zk: 192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181(CONNECTED) 1] ls /kafka321/brokers/ids
[121, 122, 123]
当然,你也可以打开浏览器输入http://192.168.1.121:8099/进行访问
7、编写kafka集群管理脚本
[root@elk121 ~]# vim /usr/local/sbin/kafkaManager.sh
#!/bin/bash
# Kafka 安装目录
KAFKA_HOME=/es/softwares/kafka
# 定义地址的前三段
IP_PREFIX="192.168.1"
#判断用户是否传参
if [ $# -ne 1 ];then
echo "无效参数,用法为: $0 {start|stop|restart}"
exit 1
fi
#获取用户输入的命令
cmd=$1
#定义函数功能
function kafkaManger(){
case $cmd in
start)
echo "启动服务"
remoteExecution start
;;
stop)
echo "停止服务"
remoteExecution stop
;;
restart)
echo "重启服务"
remoteExecution stop
remoteExecution start
;;
*)
echo "无效参数,用法为: $0 {start|stop|restart}"
;;
esac
}
#定义执行的命令
function remoteExecution() {
for ((i = 121; i <= 123; i++)); do
tput setaf 2
echo ========== ${IP_PREFIX}.${i} kafka-server-$1.sh ================
tput setaf 9
if [ "$1" == "start" ]; then
# 启动时使用 -daemon 参数
ssh ${IP_PREFIX}.${i} "source /etc/profile.d/kafka.sh; kafka-server-$1.sh -daemon $KAFKA_HOME/config/server.properties 2>/dev/null"
elif [ "$1" == "stop" ]; then
# 停止时不使用 -daemon 参数
ssh ${IP_PREFIX}.${i} "source /etc/profile.d/kafka.sh; kafka-server-$1.sh 2>/dev/null"
else
echo "Invalid command: $1"
exit 1
fi
done
}
#调用函数
kafkaManger
脚本赋权
| [root@elk121 ~]# chmod +x /usr/local/sbin/kafkaManager.sh |
|---|
二、Kafka基本架构¶
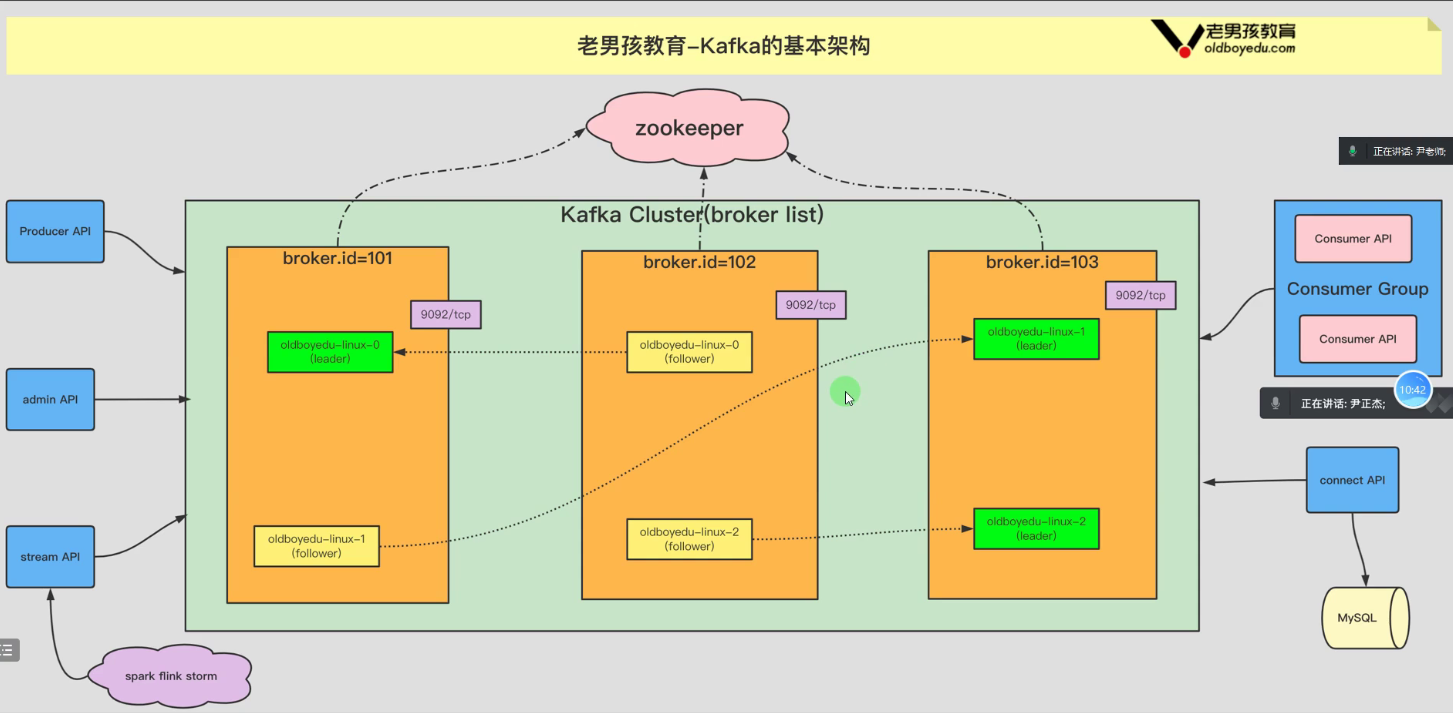
说明:默认每间隔30秒对比一下所有的LEO和leader是否相同,若相同则认为数据同步
若不同则认为数据不同步,直接踢出ISR列表。并加入OSR列表。当OSR的副本再下一次检测时发现LEO相等,再重新加入SR即可。
注意事项:
- 同一个消费者组的消费者不能同时消费同一个分区数
三、Kafka常用术语¶
kafka cluster(broker list): kafka集群
kafka Server (broker): 指的是kafka集群的某个节点
Producer: 生产者,即往kafka集群写入数据的角色。
Consumer: 消费者,即从kafka集群中读取数据的角色。一个消费者隶属于一个消费者组。
Concumer Group: 消费者组,里面有一个或多个消费者。
Topic: 主题,是一个逻辑概念,用于区分业务,一个主题最少要有1个分区和一个副本。
Partition: 分区,分区可以暂时理解为分区编号。
replica: 副本,副本是实际存储数据的地方,分为两种角色,即leader和follower。
-
leader: 负责读写。
-
follower: 负责从leader节点同步数据,无法对集群外部提供任何服务。当leader无法访问时,follower会接管leader的角色。
-
AR: 所有的副本,包含leader和follower副本。
-
ISR: 表示和leader同步的所有副本集合。
-
OSR: 表示和leader不同步的所有副本即可。
zookeeper集群: kafka 0.9之前的版本维护消费者组的offset,之后kafka内部的topic进行维护。协调kafka的leader选举,控制器协调者选举等....
consumer API: 即消费者,指的是从boker拉取数据的角色。每个消费者均隶属于一个消费者组(consumer Group),一个消费者组内可以有多个消费者。
producer API: 即生产者,指的是往broker写入数据的角色。
-
admin API: 集群管理的相关API,包括topic,parititon,replica等管理。
-
stream API: 数据流处理等API,提供给Spark,Flink,Storm分布式计算框架提供数据流管道。
-
connect API: 连接数据库相关的API,例如将MySQL导入到kafka。
常见问题:
Q1: 分区和副本有啥区别?
分区可以暂时理解为分区编号,它包含该分区编号的所有副本,和磁盘的分区没关系。
副本是实际存储数据的地方,
Q2: offset存储在kafka集群,客户端在kafka集群任意一个节点如何获取偏移量。
通过内部的消费者组的偏移量读取即可。("__consumer_ offsets")
四、kafka实战¶
4.1 topic管理实战¶
一个topic是生产者(producer)和消费者(consumer)进行逻辑的通信单元。底层存储数据的是对应一个或多个分区(partition)副本(replica)。
1、创建topic
(1) 创建一个名为" test01",分区数为3,副本数量为2的topic
| [root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --create --partitions 3 --replication-factor 2 --topic test01 |
|---|
(2) 创建一个名为" test02",分区数为3,副本数量为1的topic
| [root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --create --partitions 3 --replication-factor 1 --topic test02 |
|---|
2、查看topic(没有默认为空)
(1) 查看topic列表
修改名为test01的topic的分区数为5
[root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --list
test01
test02
(2) 查看某个topic的详细信息
[root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --describe --topic test01
Topic: test01 TopicId: kYIdjgBUSy-y0AthKUHKuw PartitionCount: 5 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: test01 Partition: 0 Leader: 122 Replicas: 122,121 Isr: 122,121
Topic: test01 Partition: 1 Leader: 121 Replicas: 121,123 Isr: 121,123
Topic: test01 Partition: 2 Leader: 123 Replicas: 123,122 Isr: 123,122
Topic: test01 Partition: 3 Leader: 122 Replicas: 122,123 Isr: 122,123
Topic: test01 Partition: 4 Leader: 123 Replicas: 123,121 Isr: 123,121
(3) 查看所有的topic详细信息
[root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --describe
Topic: test01 TopicId: kYIdjgBUSy-y0AthKUHKuw PartitionCount: 5 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: test01 Partition: 0 Leader: 122 Replicas: 122,121 Isr: 122,121
Topic: test01 Partition: 1 Leader: 121 Replicas: 121,123 Isr: 121,123
Topic: test01 Partition: 2 Leader: 123 Replicas: 123,122 Isr: 123,122
Topic: test01 Partition: 3 Leader: 122 Replicas: 122,123 Isr: 122,123
Topic: test01 Partition: 4 Leader: 123 Replicas: 123,121 Isr: 123,121
Topic: test02 TopicId: PV_77tnWRwycyfrIYE8pmQ PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test02 Partition: 0 Leader: 121 Replicas: 121 Isr: 121
Topic: test02 Partition: 1 Leader: 123 Replicas: 123 Isr: 123
Topic: test02 Partition: 2 Leader: 122 Replicas: 122 Isr: 122
3、修改topic(分区数量可以调大,但不可以调小!)
(1)修改分区数
修改名为test01的topic的分区数为5
| [root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --alter --topic test01 --partitions 5 |
|---|
验证查看
[root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --describe --topic test01
Topic: test01 TopicId: kYIdjgBUSy-y0AthKUHKuw PartitionCount: 5 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: test01 Partition: 0 Leader: 122 Replicas: 122,121 Isr: 122,121
Topic: test01 Partition: 1 Leader: 121 Replicas: 121,123 Isr: 121,123
Topic: test01 Partition: 2 Leader: 123 Replicas: 123,122 Isr: 123,122
Topic: test01 Partition: 3 Leader: 122 Replicas: 122,123 Isr: 122,123
Topic: test01 Partition: 4 Leader: 123 Replicas: 123,121 Isr: 123,121
(2)修改副本数,修改名为test02的topic的副本数为2
修改前查看test02的副本数为1
[root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --describe
Topic: test02 TopicId: PV_77tnWRwycyfrIYE8pmQ PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test02 Partition: 0 Leader: 121 Replicas: 121 Isr: 121
Topic: test02 Partition: 1 Leader: 123 Replicas: 123 Isr: 123
Topic: test02 Partition: 2 Leader: 122 Replicas: 122 Isr: 122
编写分配脚本
[root@elk121 ~]# vim addReplicas.json
{"topics":
[{"topic":"test02"}],
"version": 1
}
执行分配计划,用于生成json格式的文件
[root@elk121 ~]# kafka-reassign-partitions.sh --bootstrap-server 192.168.1.121:9092,192.168.1.1222 --topics-to-move-json-file addReplicas.json --broker-list "121,122,123" –generate
#这是当前的分区情况
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test02","partition":0,"replicas":[121],"log_dirs":["any"]},{tion":1,"replicas":[123],"log_dirs":["any"]},{"topic":"test02","partition":2,"replicas":[122],"lo
#这是推荐分区计划
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"test02","partition":0,"replicas":[121],"log_dirs":["any"]},{tion":1,"replicas":[122],"log_dirs":["any"]},{"topic":"test02","partition":2,"replicas":[123],"l
将 Proposed partition reassignment configuration的配置copy保存到一个文件中 topic-reassignment.json并对它进行相应的修改(主要修改副本数为2)
[root@elk121 ~]# vim addReplicas.json
{"topics":
[{"topic":"test02"}],
"version": 1
}
[root@elk121 ~]# cat topic-reassignment.json
{
"version": 1,
"partitions": [
{
"topic": "test02",
"partition": 0,
"replicas": [122, 123],
"log_dirs": ["/es/logs/kafka", "/es/logs/kafka"]
},
{
"topic": "test02",
"partition": 1,
"replicas": [121, 122],
"log_dirs": ["/es/logs/kafka", "/es/logs/kafka"]
},
{
"topic": "test02",
"partition": 2,
"replicas": [121, 123],
"log_dirs": ["/es/logs/kafka", "/es/logs/kafka"]
}
]
}
在进行下面操作之前,需要检查三台kafka的配置文件中的参数是否和上面的json文件保持一致(这里以elk123节点为例)
[root@elk123 ~]# vim /es/softwares/kafka/config/server.properties
…
…
broker.id=123
log.dirs=/es/logs/kafka
…
…
使用 kafka-reassign-partitions.sh 工具执行重新分配
[root@elk121 ~]# kafka-reassign-partitions.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --reassignment-json-file topic-reassignment.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test02","partition":0,"replicas":[121],"log_dirs":["any"]},{"topic":"test02","partition":1,"replicas":[123],"log_dirs":["any"]},{"topic":"test02","partition":2,"replicas":[122],"log_dirs":["any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for test02-0,test02-1,test02-2
Successfully started log directory moves for: test02-1-121,test02-2-121,test02-0-122,test02-1-122,test02-0-123,test02-2-123
使用以下命令验证重新分配的进度
[root@elk121 ~]# kafka-reassign-partitions.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --reassignment-json-file topic-reassignment.json --verify
Status of partition reassignment:
Reassignment of partition test02-0 is complete.
Reassignment of partition test02-1 is complete.
Reassignment of partition test02-2 is complete.
Reassignment of replica test02-1-121 completed successfully.
Reassignment of replica test02-2-121 completed successfully.
Reassignment of replica test02-0-122 completed successfully.
Reassignment of replica test02-1-122 completed successfully.
Reassignment of replica test02-0-123 completed successfully.
Reassignment of replica test02-2-123 completed successfully.
Clearing broker-level throttles on brokers 121,122,123
Clearing topic-level throttles on topic test02
分配完成后,再次查看topic详细信息
[root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --describe --topic test02
Topic: test02 TopicId: PV_77tnWRwycyfrIYE8pmQ PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: test02 Partition: 0 Leader: 122 Replicas: 122,123 Isr: 122,123
Topic: test02 Partition: 1 Leader: 121 Replicas: 121,122 Isr: 121,122
Topic: test02 Partition: 2 Leader: 121 Replicas: 121,123 Isr: 121,123
4、刪除topic
删除名为 test01的topic
| [root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --delete --topic test01 |
|---|
验证查看
[root@elk121 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --list
test02
4.2 topic生产者和消费者实战¶
说明:验证kafka集群正常,可以在生产者进行输入,在消费观察输出,如果一致则代表集群运行正常
1、在elk121节点上创建生产者,并输入1111
[root@elk121 ~]# kafka-console-producer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test02
>1111
2、在elk123节点上创建消费者进行查看
| [root@elk123 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test02 --from-beginning |
|---|
说明:如果不加--from-beginning参数代表只会从最新的位置开始读取
4.3 消费者组实战案例¶
温馨提示:
(1)同一个消费者组(consumer group)的消费者(consumer)不能同时去同一个分区(parititon)读取数据,避免数据重复消费;
(2)当一个topicl的分区数量增大时,消费者组的各个消费者将重新分配(rebalance),即重新分配待消费分区的所属权;
(3)当同一个消费者组的消费者数量发生变化时,也会触发rebalance,即重新分配待消费分区的所属权;
1、在elk123节点上创建名为test03的topic
| [root@elk123 ~]# kafka-topics.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --create --partitions 3 --replication-factor 2 --topic test03 |
|---|
2、在elk122节点上启动生产者
[root@elk122 ~]# kafka-console-producer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test03
>
3、在elk121节点和elk123节点启动消费者加入同一个消费者组
(1)在elk123节点上修改配置文件
修改第22行内容
[root@elk123 ~]# vim /es/softwares/kafka/config/consumer.properties
…
…
group.id=group-id01
…
…
修改后的文件内容为
[root@elk123 ~]# egrep -v "^$|^#" /es/softwares/kafka/config/consumer.properties
bootstrap.servers=localhost:9092
group.id=group-id01
(2) 在elk123节点上启动消费者加入同一个消费者组(指定文件方式)
| [root@elk123 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test03 --consumer.config /es/softwares/kafka/config/consumer.properties --from-beginning |
|---|
(3) 在elk123节点上启动消费者加入同一个消费者组(指定group.id方式)
| [root@elk121 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test03 --consumer-property group.id=group-id01 --from-beginning |
|---|
(4) 在elk123节点上查看group
查看所有group
[root@elk123 ~]# kafka-consumer-groups.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --all-groups –list
group-id01
查看某个详细的group,观察到elk123主机的分片0和分片1为一组,而elk121主机的分片2为一组
[root@elk123 ~]# kafka-consumer-groups.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --describe --group group-id01
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
group-id01 test03 0 0 0 0 console-consumer-5bc3df32-082c-463c-a35d-d41a37e489c9 /192.168.1.123 console-consumer
group-id01 test03 1 0 0 0 console-consumer-5bc3df32-082c-463c-a35d-d41a37e489c9 /192.168.1.123 console-consumer
group-id01 test03 2 0 0 0 console-consumer-91f5392e-2011-489c-b86e-3cf81796699e /192.168.1.121 console-consumer
相关参数说明:
-
CURRENT-OFFSET:表示消费者组当前已经消费的消息偏移量。
-
LOG-END-OFFSET:表示该分区当前日志的最末尾的消息的偏移量。
-
LAG:表示当前分区的偏移量滞后(即未消费的消息数量),计算方式为 LOG-END-OFFSET - CURRENT-OFFSET。
4、在elk122节点(生产者)上写入数据
[root@elk122 ~]# kafka-console-producer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test03
>1111
>2222
>3333
5、在elk121节点和elk123节点观察消费者的详细信息
[root@elk123 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test03 --consumer.config /es/softwares/kafka/config/consumer.properties --from-beginning
2222
3333
[root@elk121 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic test03 --consumer-property group.id=group-id01 --from-beginning
1111
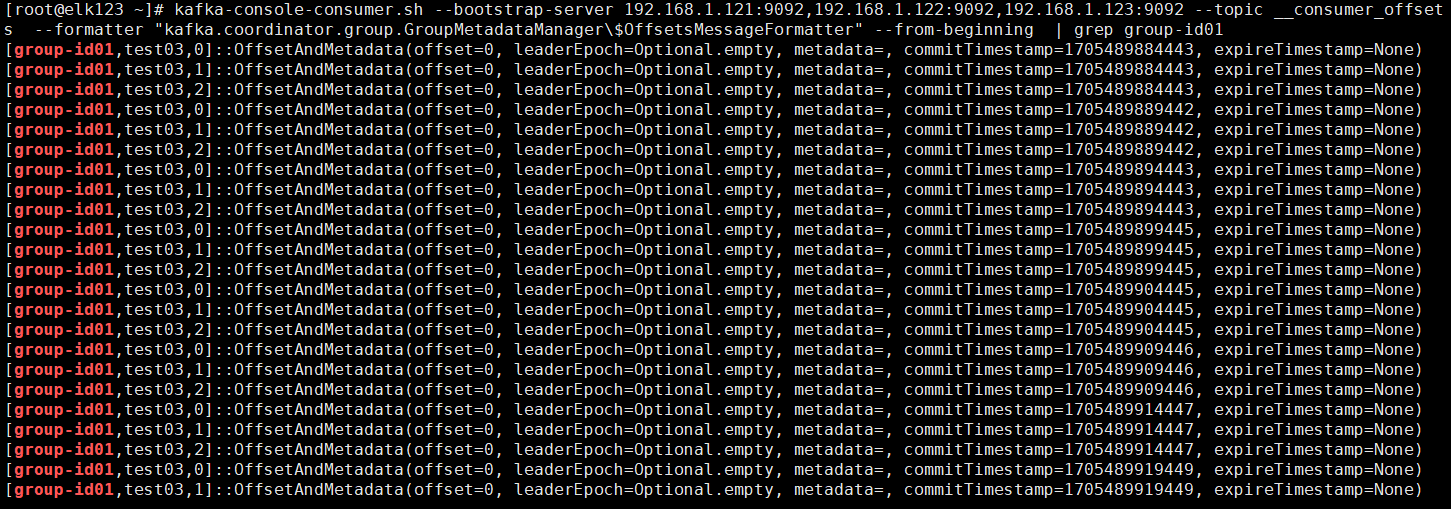
拓展:查看内置的"__consumer_offsets "的数据
| [root@elk123 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092 --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\OffsetsMessageFormatter" --from-beginning | grep group-id01 |
|---|
五、kafka优化¶
官方文档:https://kafka.apache.org/documentation/#configuration
5.1 JVM堆内存调优¶
生产环境中初始堆内存大小(-Xms)和允许的最大堆内存大小(-Xmx)一般设置为6G
1、在elk121节点上修改第28行到第32行内容
[root@elk121 ~]# vim `which kafka-server-start.sh ` +28
…
…
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-server -Xmx6G -Xms6G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="8888"
fi
…
…
相关参数说明:
-
-server: 表示以服务器模式运行 JVM。
-
-Xmx6G: 设置最大堆内存为 6GB。
-
-Xms6G: 设置初始堆内存为 6GB。
-
-XX:PermSize=128m: 设置永久代大小为 128MB。这个选项在 Java 8 及更早版本中有效,但在 Java 8 之后的版本中被 MetaSpace 替代。
-
-XX:+UseG1GC: 使用 G1 垃圾收集器。
-
-XX:MaxGCPauseMillis=200: 设置最大垃圾收集停顿时间为 200 毫秒。
-
-XX:ParallelGCThreads=8: 设置并行垃圾收集线程数量为 8。
-
-XX:ConcGCThreads=5: 设置并发垃圾收集线程数量为 5。
-
-XX:InitiatingHeapOccupancyPercent=70: 设置 G1 垃圾收集器开始执行混合收集的初始堆占用百分比为 70%。
修改后的内容如下
[root@elk121 ~]# egrep -v "^$|^#" `which kafka-server-start.sh `
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] server.properties [--override property=value]*"
exit 1
fi
base_dir=$(dirname $0)
if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"
fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-server -Xmx6G -Xms6G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="8888"
fi
EXTRA_ARGS=${EXTRA_ARGS-'-name kafkaServer -loggc'}
COMMAND=$1
case $COMMAND in
-daemon)
EXTRA_ARGS="-daemon "$EXTRA_ARGS
shift
;;
*)
;;
esac
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@"
2、在elk121节点上同步集群启动脚本
| [root@elk121 ~]# data_rsync.sh `which kafka-server-start.sh ` |
|---|
3、在所有节点上重启kafka集群
| [root@elk121 ~]# kafkaManager.sh restart |
|---|
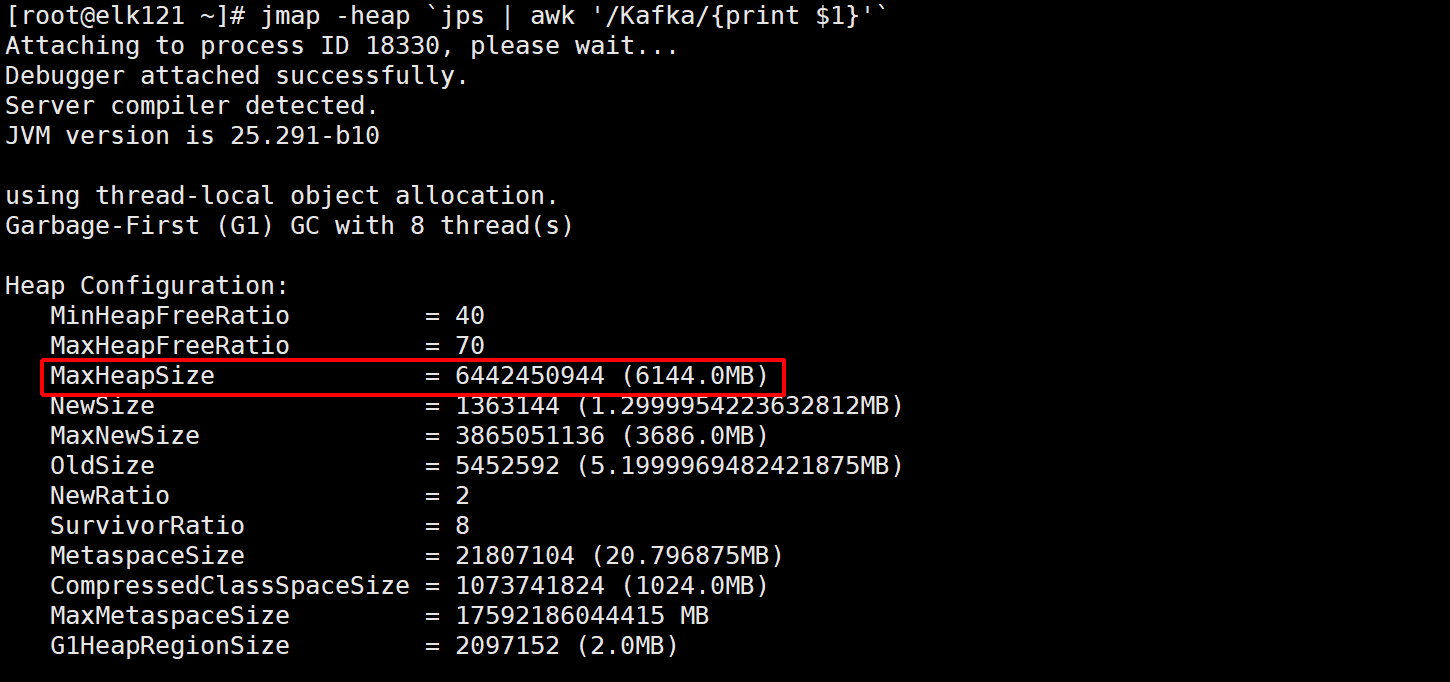
4、在所有节点上验证kafka集群的内存大小
[root@elk121 ~]# jmap -heap `jps | awk '/Kafka/{print $1}'`
[root@elk122 ~]# jmap -heap `jps | awk '/Kafka/{print $1}'`
[root@elk123 ~]# jmap -heap `jps | awk '/Kafka/{print $1}'`
5.2 broker调优¶
[root@elk121 ~]# vim /es/softwares/kafka/config/server.properties
############################# Server Basics #############################
#每一个broker在集群中的唯一表示,要求是整数。当该服务器的IP地址发生改变时,broker.id设有变化,则不会影响consumers的消息情况
broker.id=121
#这条命令其实并不执行别除动作,仅仅是在zookeeper.上标记该topic要被删除而已,同时也提醒用户一定要提前打开delete.topic.enable=true开关,否则删除动作不会执行的
delete.topic.enable=true
#是否允许自动创建topic,若是false,就需要通过命令创建topic
auto.create.topics.enable=true
############################# Socket Server Settings #############################
# The address the socket server listens on. If not configured, the host name will be equal to the value of
# java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#Socket服务器侦听的地址。如果没有配置,它将获得从Java.NET.InAddio.GETCANONICAL ITHAMEMENE()返回的值
#listeners=PLAINTEXT://192.168.1.121:9092
#broker server服务端口
port=9092
#broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置
host.name=192.168.1.121
#处理网格请求的最大线程数
num.network.threads=30
#处理磁盘I/0的线程数
num.io.threads=30
#套接字服务器使用的发送缓冲区〔SOYSNDBUF)
socket.send.buffer.bytes=5242880
#套接字服务器使用的接收缓冲区〔SOYRCVBUF)
socket.receive.buffer.bytes=5242880
#套接字服务器将接受的请求的最大大小(对OOM的保护)
socket.request.max.bytes=104857600
#I/O线程等待队列中的最大的请求数,超过这个数量,network线程就不会再接收一个新的请求。应该是一种自我保护机制。
queued.max.requests=1000
############################# Log Basics #############################
#日志存放目录,多个目录使用逗号分割,如果你有多块磁盘,建议配置成多个目录,从而达到I/O的效率的提升。
log.dirs=/kafka/logs1,/kafka/logs2,/kafka/logs3
#每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖
num.partitions=20
#默认副本数
default.replication.factor=2
#在启动时恢复日志和关闭时刷盘日志时每个数据目录的线程的数量,默认1
num.recovery.threads.per.data.dir=32
#服务器接受单个消息的最大大小,即消息体的最大大小,单位是字节,下面是100MB
message.max.bytes=104857600
#自动负载均衡,如果设为true,复制控制器会周期性的自动尝试,为所有的broker的每个partition-平衡leadership,为更优先(preferred)
auto.leader.rebalance.enable=true
############################# Log Flush Policy #############################
#在强制Fsync-一个pārtition的1og文件之前暂存的消息数量。调低这个值会更频繁的sync数据到磁盘,影响性能。通常建议人家使用
replication来确保持久性,而不是依靠单机上的fsync,但是这可以带来更多的可靠性,默认10000。
#log.flush.interval.messages=10000
#2次Fsync调用之间最大的时间间隔,单位为ms。即使1og.flush.interval.messages设有达到,只要这个时间至到了也需要调用fsync。默认
3000ms.
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
#日志保存时间(hours |minutes),默认为7天(168小时)。超过这个时间会根据po1icy处理数据。hours和minutes无论哪个先达到都会触发。
log.retention.hours=168
#日志数据存储的最大字节数。超过这个时间会根据policy处理数据。
#log.retention.bytes=1073741824
#控制日志segment文件的大小,超出该大小贝则追加到一个新的日志segment文件中〔-1表示没有限制)
log.segment.bytes=536870912
#当达到下面时间,会强制新建一个segment
#log.roll.hours=24*7
#日志片段文件的检查周期,查看它们是否达到了删除策路的设置(1og.retention.hours或log.retention.bytes)
log.retention.check.interval.ms=600000
#是否开启压缩
log.cleaner.enable=false
##日志清理策路选择有:delete和compact主要针对过期数据的处理,或是日志文件达到限制的额度,会被topic创建时的指定参数覆盖
log.cleanup.policy=delete
#日志压缩运行的线程数
log.cleaner.threads=2
#压缩的日志保留的最长时间
log.cleaner.delete.retention.ms=3600000
############################# Zookeeper #############################
#zookeeper集群的地址,可以是多个,多个之间用逗号分割,生产环境中,建议配置chroot目录
zookeeper.connect=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
#指定多久消费者更新offset到zookeeper中。注意offset.更新时基于time而不是每次获得的消息。一旦在更新zookeeper.发生异常并重启,将可能拿到已拿到过的消息,连接zk的超时时间
zookeeper.connection.timeout.ms=6000
#请求的最大大小为字节,请求的最大字节数。这也是对最大记录尺寸的有效覆盖。注意:serve具有自己对消息记录尺寸的覆盖,这些尺寸和这个设置不同。此项设置将会限制producer每次批量发送请求的数目,以防发出巨量的请求。
max.request.size=104857600
#每次fetch请求中,针对每次fetch消息的最大字节数。这些字节将会督导用于每个partition的内存中,因此,此设直将会控制consumer所使用的memory.大小。这个fetch请求尺寸必须至少和server允许的最大消息尺寸相等,否则,producer可能发送的消息尺寸大于consumer所能消耗的尺寸
fetch.message.max.bytes=104857600
#ZooKeeper集群中leader和fo11ower之间的同步时间,换句话说:一个ZK fo11ower能落后leader多久。
#zookeeper.sync.time.ms=2000
############################# Replica Basics #############################
replica.lag.time.max.ms=30000
#leader接收fo1lower的"fetch请求"的超时时间,默认是10秒。
#replica.lag.time.max.ms=30000
#如果re1icas落后太多,将会以为此partition re1icas已经失效。而一般情况下,因为网络延迟等原因,总会导致rep1icas中消息同步滞后。如果消息严重滞后,leader将认为此relicas网铭延迟较大或者消息吞吐能力有限。在broker数量较少,或者网格不足的环境中,建议提高此值.follower落后于leader的最大nessage数,这个参数是broker:全局的。设置太大了,影响真正“落后”follower的移除;设置的太小了,导致Follower的频繁进出。无法给定一个合适的rep1ica.lag,max,messages的值,因此不推荐使用,据说新版本的Kafka移除了这个参数。
# replica.lag.max.messages=4000 # 不推荐使用
#follower.与leader之间的socket超时时间
#replica.socket.timeout.ms=30000
#fo11owen每次fetch数据的最大尺寸
replica.fetch.max.bytes=104857600
#fo11ower的fetch请求超时重发时间
replica.fetch.wait.max.ms=2000
#fetch的最小数据尺寸
# replica.fetch.min.bytes=1 # 未指定,一般情况下不太需要调整
#是否允许控制器关闭broker,默认值为true,它会关闭所有在这个broker上的leader,并转移到其他broker,建议启用,增加集群稳定性。
controlled.shutdown.enable=false
#0.11.0.0版本开始unc1ean.1 eader.election.enable参数的默认值由原来的true改为false,可以关闭unc1ean1 eader election,也就是不在IsR(IN-Sync Replica)列表中的rep]ica,不会被提升为新的1 eader partition。kafka集群的持久化力大于可用性,如果IsR中没有其它的replica,会导致这个partition不能读写。
unclean.leader.election=false
#fo11ower中开启的Fetcher线程数,同步速度与系统负载均衡
num.replica.fetchers=5
#partition leader与replicas之间通讯时,socket的超时时间
# controller.socket.timeout.ms=30000 # 未指定
#partition leader与replicas数据同步时,消息的队列尺寸
# controller.message.queue.size=10 # 未指定
#指定将使用哪个版本的inter-broker协议。在所有经纪人升级到新饭本之后,这通常会受到冲击。升级时要设置
#inter.broker.protocol.version=0.10.1
#指定broker将用于将消息添动加到日志文件的消息格式版本。该值应该是有效的Apiversion.。一些例子是:0.8.2,0.9.0.0,0.10.0。通过设置特定的消息格式版本,用户保证磁盘上的所有现有消息都小于或等于指定的版本。不正确地设置这个值将导致使用旧版本的用户出错,因为他们将接收到他们不理解的格式的消息。
#log.message.format.version=0.10.1
注意:生产环境中请一定要弄清楚参数的含义,然后在配互,配置后重启集群时请不要批量重启,要滚动重启!
六、部署kafka-eagle监控¶
6.1 启动kafka的JXM端口¶
1、所有节点停止kafka
| [root@elk121 ~]# kafkaManager.sh stop |
|---|
2、在elk121节点上修改第28行到第32行内容
[root@elk121 ~]# vim `which kafka-server-start.sh ` +28
…
…
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-server -Xmx6G -Xms6G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="8888"
fi
…
…
相关参数说明:
-
-server: 表示以服务器模式运行 JVM。
-
-Xmx6G: 设置最大堆内存为 6GB。
-
-Xms6G: 设置初始堆内存为 6GB。
-
-XX:PermSize=128m: 设置永久代大小为 128MB。这个选项在 Java 8 及更早版本中有效,但在 Java 8 之后的版本中被 MetaSpace 替代。
-
-XX:+UseG1GC: 使用 G1 垃圾收集器。
-
-XX:MaxGCPauseMillis=200: 设置最大垃圾收集停顿时间为 200 毫秒。
-
-XX:ParallelGCThreads=8: 设置并行垃圾收集线程数量为 8。
-
-XX:ConcGCThreads=5: 设置并发垃圾收集线程数量为 5。
-
-XX:InitiatingHeapOccupancyPercent=70: 设置 G1 垃圾收集器开始执行混合收集的初始堆占用百分比为 70%。
修改后的内容如下
[root@elk121 ~]# egrep -v "^$|^#" `which kafka-server-start.sh `
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] server.properties [--override property=value]*"
exit 1
fi
base_dir=$(dirname $0)
if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"
fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-server -Xmx6G -Xms6G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="8888"
fi
EXTRA_ARGS=${EXTRA_ARGS-'-name kafkaServer -loggc'}
COMMAND=$1
case $COMMAND in
-daemon)
EXTRA_ARGS="-daemon "$EXTRA_ARGS
shift
;;
*)
;;
esac
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@"
3、在elk121节点上同步集群启动脚本
| [root@elk121 ~]# data_rsync.sh `which kafka-server-start.sh ` |
|---|
4、在所有节点上重启kafka集群
| [root@elk121 ~]# kafkaManager.sh restart |
|---|
6.2 启动zookeeper的JMX端口¶
1、所有节点修改配置文件,在末尾处添加如下内容
[root@elk121 ~]# vim /es/softwares/zk/conf/zoo.cfg
…
…
4lw.commands.whitelist=*
修改后内容如下:
[root@elk121 ~]# vim /es/softwares/zk/conf/zoo.cfg
# 定义最小单元的时间范围tick。
tickTime=2000
# 启动时最长等待tick数量。
initLimit=5
# 数据同步时最长等待的tick时间进行响应ACK
syncLimit=2
# 指定数据目录
dataDir=/es/data/zk
# 监听端口
clientPort=2181
# 开启四字命令允许所有的节点访问。
4lw.commands.whitelist=*
# server.ID=A:B:C[:D]
# ID:
# zk的唯一编号。
# A:
# zk的主机地址。
# B:
# leader的选举端口,是谁leader角色,就会监听该端口。
# C:
# 数据通信端口。
# D:
# 可选配置,指定角色。
server.121=192.168.1.121:2888:3888
server.122=192.168.1.122:2888:3888
server.123=192.168.1.123:2888:3888
#允许所有的 4 字母命令
4lw.commands.whitelist=*
在elk123节点上测试上面配置是否生效,如果输入ruok返回imok则代表配置生效
[root@elk123 ~]# telnet 192.168.1.121 2181
Trying 192.168.1.121...
Connected to 192.168.1.121.
Escape character is '^]'.
ruok
imokConnection closed by foreign host.
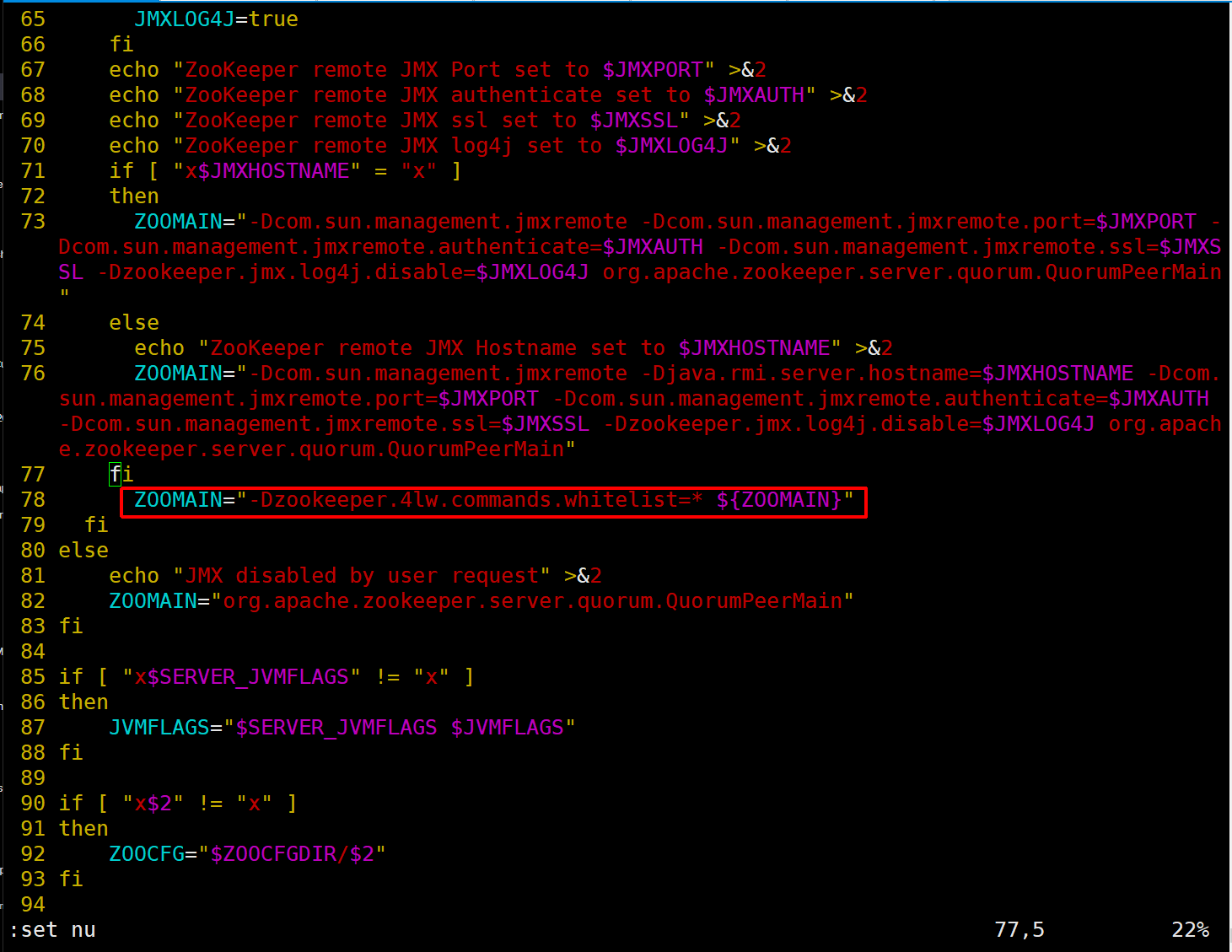
补充:如果修改上面的方式不生效,则需修改zkServer.sh脚本中77行之后ZOOMAIN的值即可
[root@elk121 ~]# vim /es/softwares/zk/bin/zkServer.sh +77
…
…
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
2、在elk121节点修改环境变量开启JMX,末尾处添加如下内容
[root@elk121 ~]# vim /es/softwares/zk/bin/zkEnv.sh
...
…
JMXLOCALONLY=false
JMXPORT=21812
JMXSSL=false
JMXLOG4J=false
3、在elk121节点同步脚本
[root@elk121 ~]# data_rsync.sh /es/softwares/zk/bin/zkEnv.sh
[root@elk121 ~]# data_rsync.sh /es/softwares/zk/bin/zkServer.sh
4、所有节点重启zk
| [root@elk121 ~]# zkManager.sh restart |
|---|
5、使用jconsole验证是否能连接JMX端口
(1)下载jdk-8u333-windows-x64.exe
(2)安装jdk-8u333-windows-x64.exe,直接点击【下一步】即可
(3)进入C:\Program Files\Java\jdk1.8.0_333\bin路径中,双击jconsole.exe文件后,在远程进程中,输入192.168.1.121:21812进行连接即可。能监控到数据即可
6.3 安装MySQL¶
1、在elk121节点上安装mariadb
| [root@elk121 ~]# yum -y install mariadb-server |
|---|
2、在elk121节点上配置mariadb的配置文件
在第10行处添加如下内容
[root@elk121 ~]# vim /etc/my.cnf
…
…
# 关闭MySQL的反向解析功能
skip-name-resolve=1
…
…
修改完成后的内容如下:
[root@elk121 ~]# egrep -v "^#|^$" /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
skip-name-resolve=1
[mysqld_safe]
log-error=/var/log/mariadb/mariadb.log
pid-file=/var/run/mariadb/mariadb.pid
!includedir /etc/my.cnf.d
3、在elk121节点上启动服务并设置开机自启动
| [root@elk121 ~]# systemctl enable mariadb --now |
|---|
4、在elk121节点上创建数据库kafka
[root@elk121 ~]# mysql
MariaDB [(none)]> CREATE DATABASE kafka DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
5、在elk121节点上创建授权用户
MariaDB [(none)]> CREATE USER admin IDENTIFIED BY '123456';
MariaDB [(none)]> GRANT ALL ON kafka.* TO admin;
MariaDB [(none)]> SHOW GRANTS FOR admin;
6、在elk121节点上测试用户
| [root@elk121 ~]# mysql -u admin -p123456 -h 192.168.1.121 |
|---|
6.4 部署kafka-eagle监控¶
1、下载kafka-eagle软件
下载地址:https://github.com/smartloli/kafka-eagle-bin/archive/refs/tags/v2.0.8.zip
2、在elk121节点上解压软件包
[root@elk121 ~]# unzip kafka-eagle-bin-2.0.8.zip
[root@elk121 ~]# tar xf efak-web-2.0.8-bin.tar.gz -C /es/softwares/
3、在elk121节点上修改配置文件
[root@elk121 ~]# vim /es/softwares/efak-web-2.0.8/conf/system-config.properties
efak.zk.cluster.alias=cluster1
cluster1.zk.list=192.168.1.121:2181,192.168.1.122:2181,192.168.1.123:2181/kafka321
cluster1.efak.broker.size=20
kafka.zk.limit.size=32
efak.webui.port=8048
cluster1.efak.offset.storage=kafka
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
efak.metrics.charts=true
efak.metrics.retain=15
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
efak.topic.token=keadmin
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://192.168.1.121:3306/kafka?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=admin
efak.password=123456
相关参数说明:

4、在elk121节点上配置环境变量
[root@elk121 ~]# cat >> /etc/profile.d/kafka.sh <<'EOF'
export KE_HOME=/es/softwares/efak-web-2.0.8
export PATH=$PATH:$KE_HOME/bin
EOF
重新生效环境变量
| [root@elk121 ~]# source /etc/profile.d/kafka.sh |
|---|
5、在elk121节点上启动服务
| [root@elk101.oldboyedu.com ~]# ke.sh start |
|---|
6、打开浏览器输入http://192.168.1.121:8048,账号:admin,密码:123456
7、基本使用
(1)后台修改用户密码
MariaDB [(none)]> use kafka;
MariaDB [kafka]> select * from ke_users;
+----+-------+----------+----------+-----------------+---------------+
| id | rtxno | username | password | email | realname |
+----+-------+----------+----------+-----------------+---------------+
| 1 | 1000 | admin | 123456 | admin@email.com | Administrator |
+----+-------+----------+----------+-----------------+---------------+
MariaDB [kafka]> update ke_users set password=123;
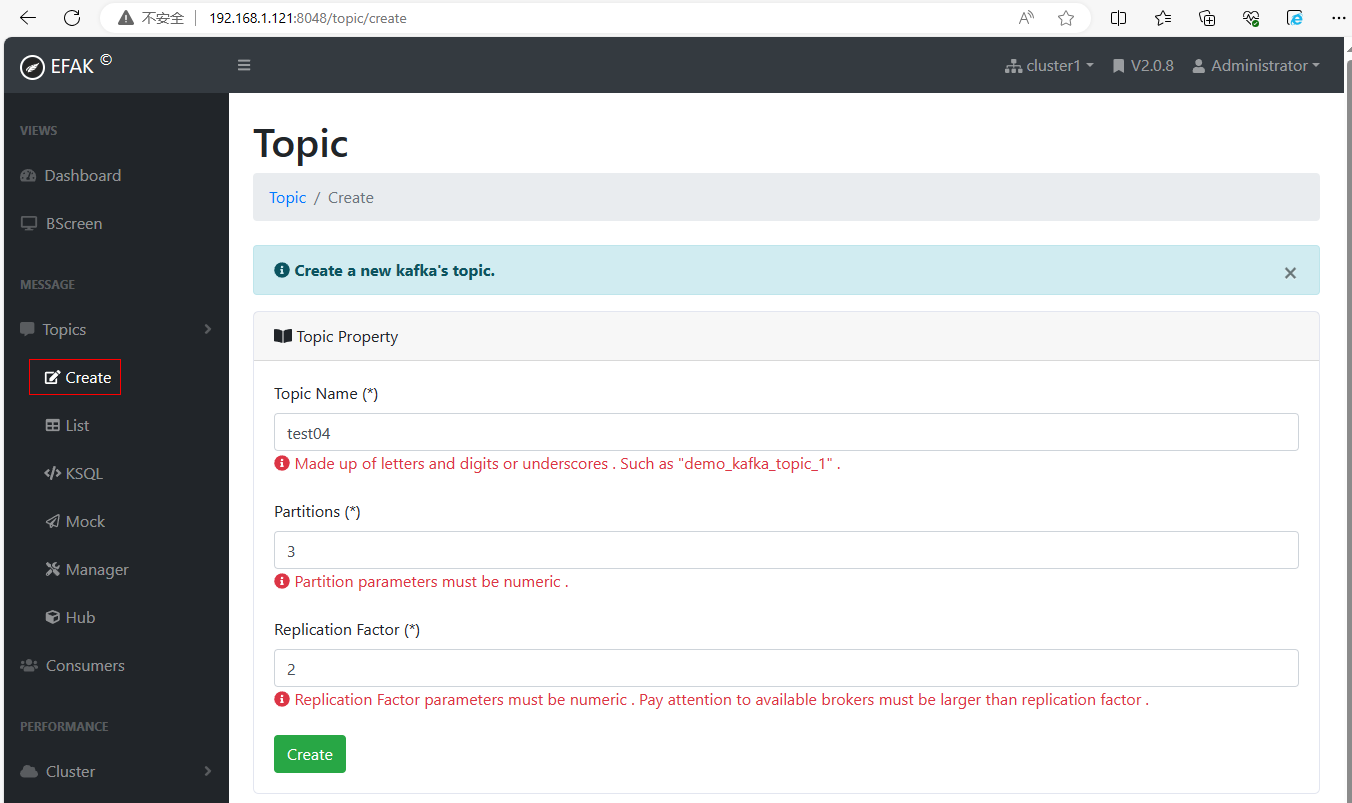
(2)创建名为test04的topic,分区号为3,副本数为2
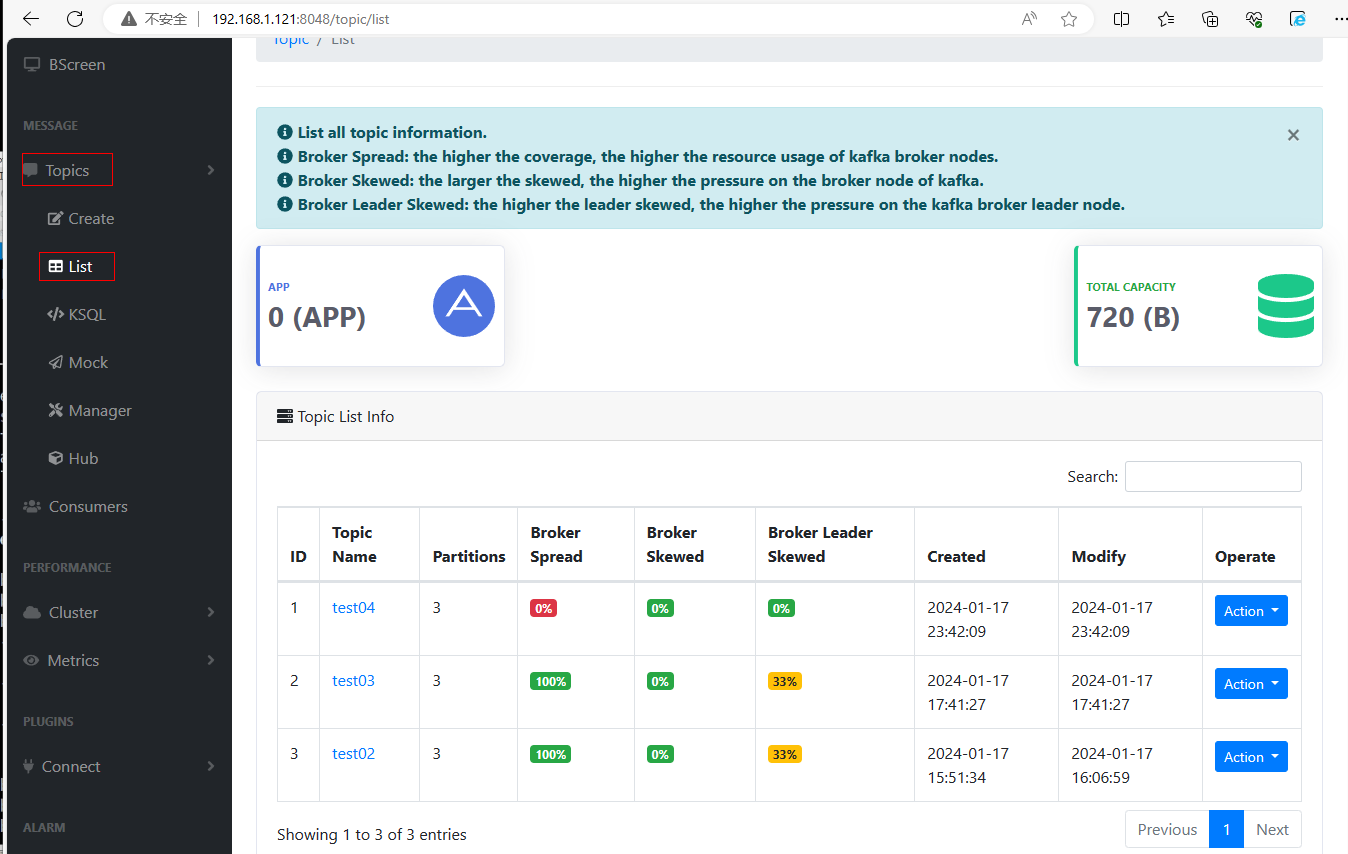
(3)查看topic
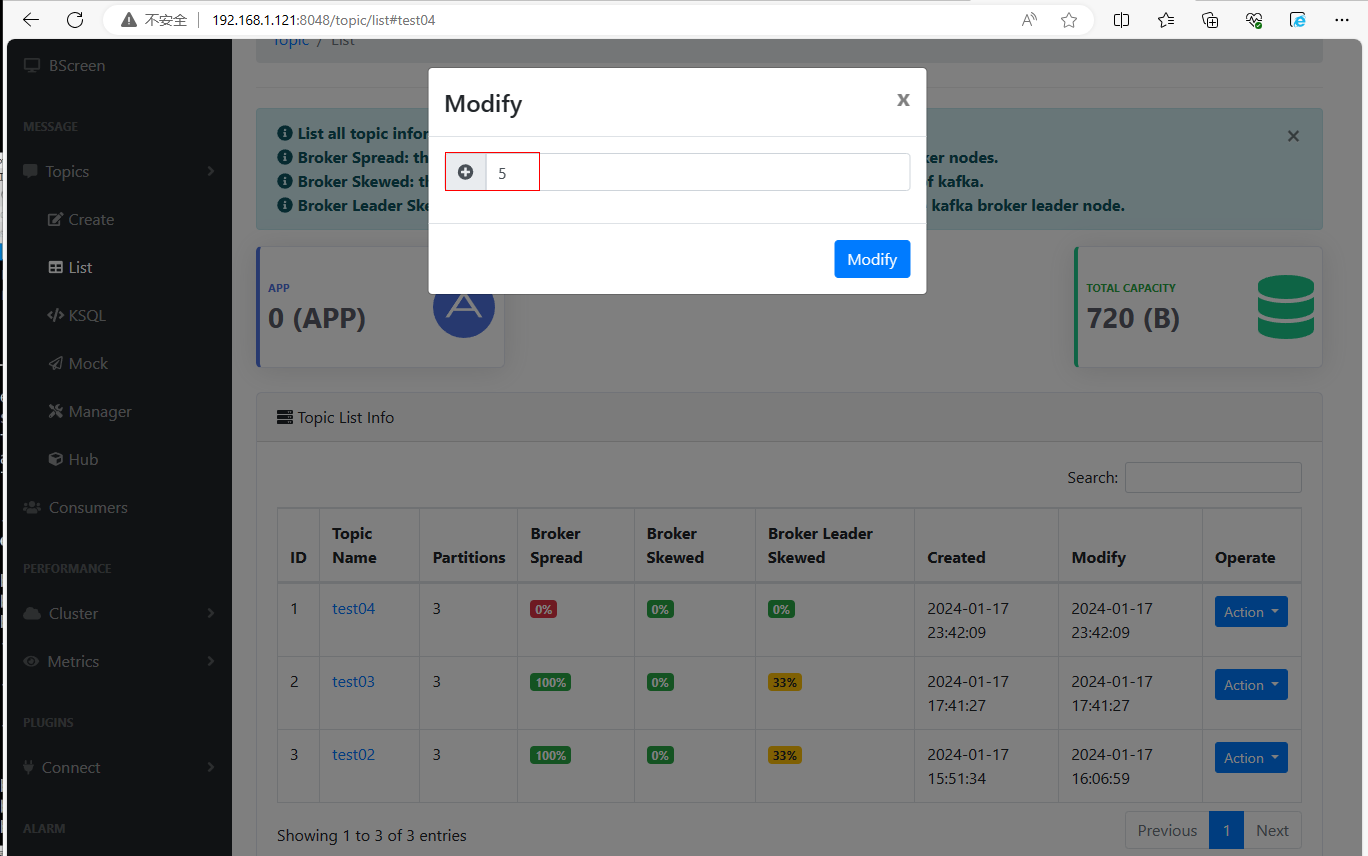
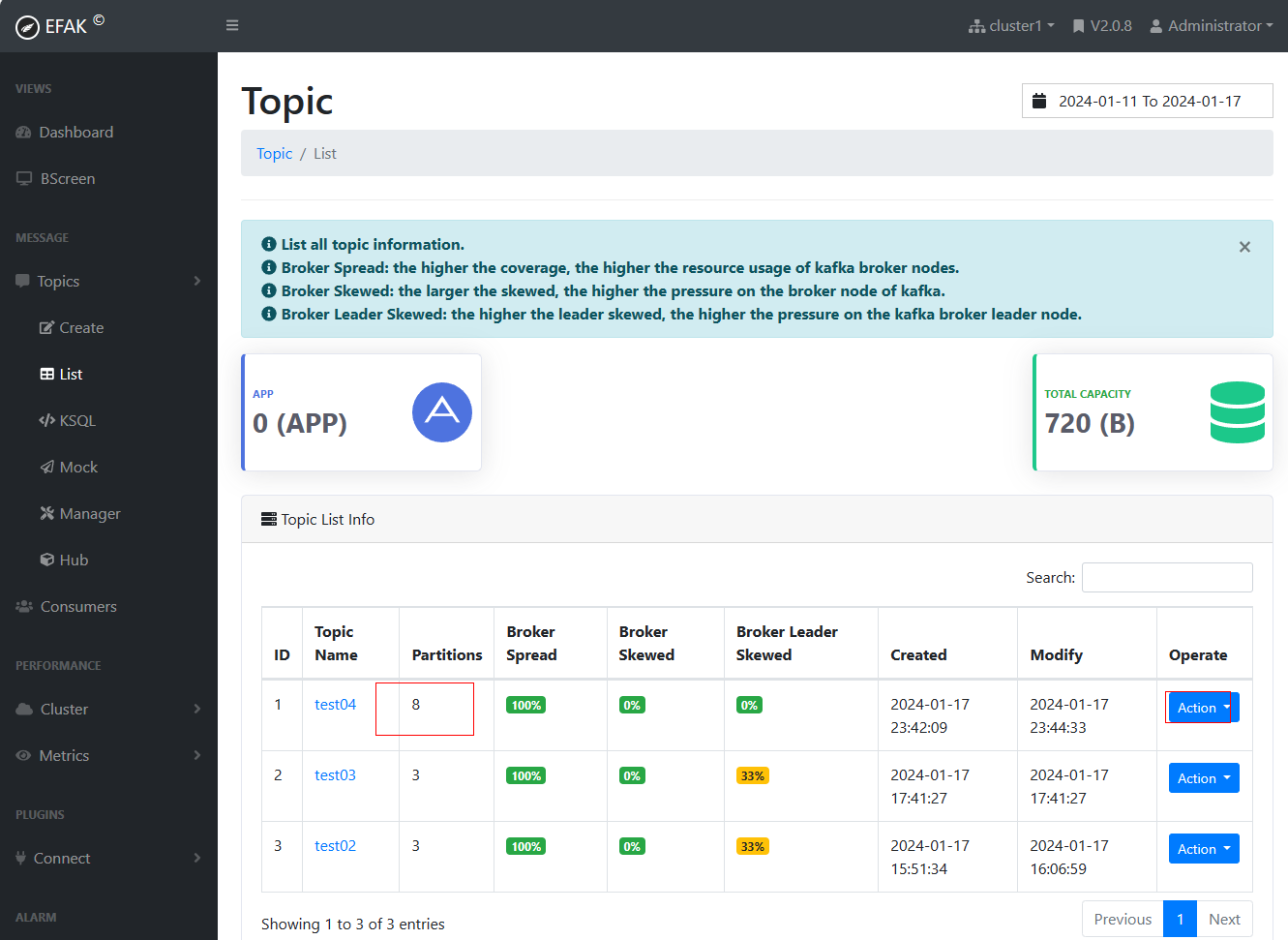
(4)修改topic
点击【Action】,输入要增加的分区数
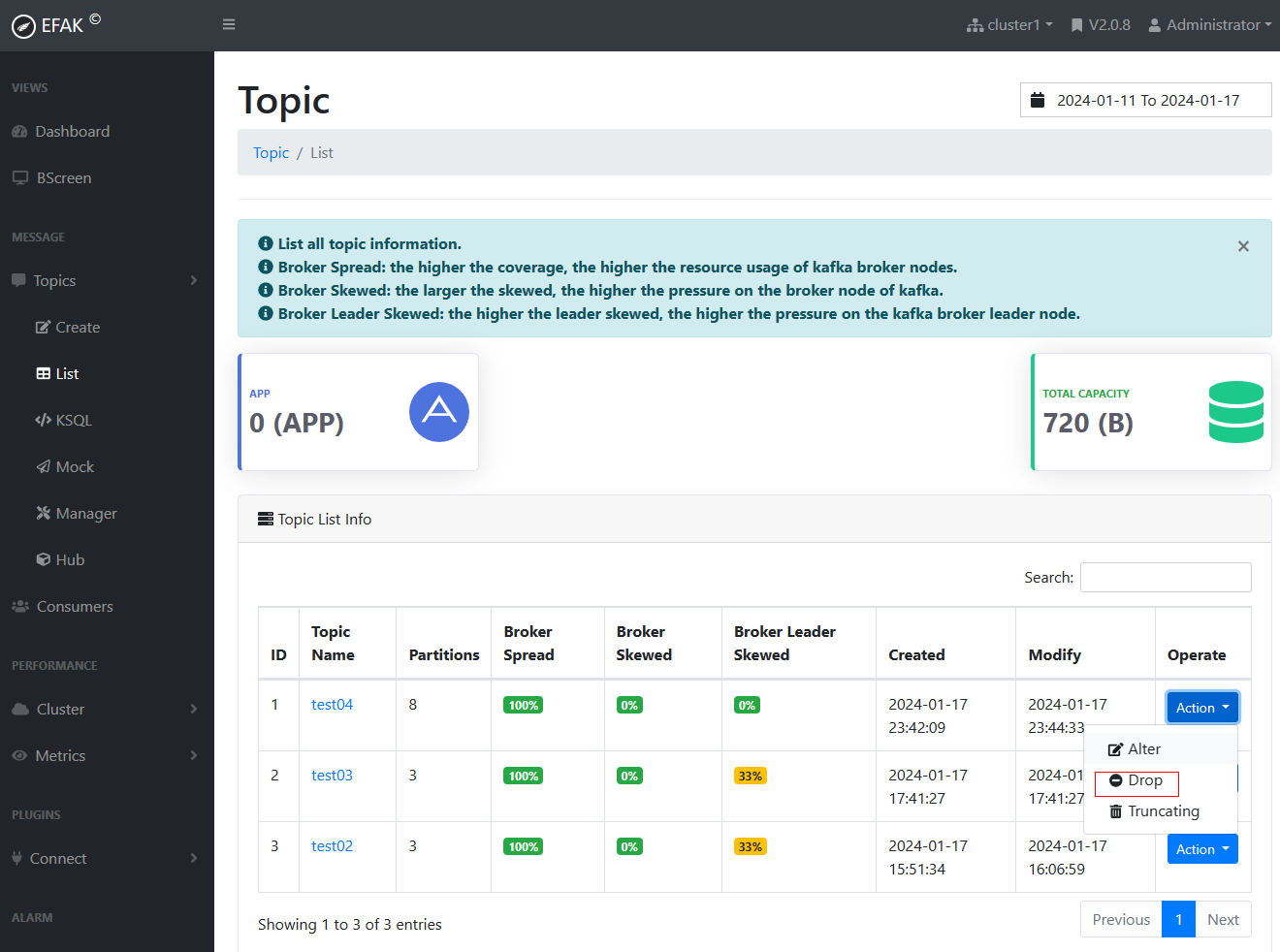
(5)删除topic
删除topic4,需要输入Token:keadmin
七、kafka集群压力测试¶
7.1 什么是压力测试¶
在软件工程中,压力测试是对系统不断施加压力的测试,是通过确定一个系统的瓶颈或者不能接收的性能点,来获得系统能提供的最大服务级别的测试。
简单来说,所调压力测试就是对一个东群的处理能力的上限敏一个评估。为将来集群扩容提供有效的依据。
7.2 为什么要进行压力测试¶
1、压力测试可以了解当前集群的处理能力上限;
2、当修改集群的配首参数后,压力测试可以协助运维人员去参考本次调优的效果;
3、压力测试的结果以后可以作为参考扩容集群的有效依据;
7.3 压力测试案例¶
1、创建测试目录并编写测试脚本
[root@elk121 ~]# install -d /tmp/kafka-test/
[root@elk121 ~]# vim kafka-test.sh
# 设置 Kafka 服务器的 IP 地址列表
KAFKA_SERVERS="192.168.1.121:9092,192.168.1.122:9092,192.168.1.123:9092"
# 创建 topic
kafka-topics.sh --bootstrap-server $KAFKA_SERVERS --topic kafka-test01 --replication-factor 1 --partitions 10 --create
# 启动消费者消费数据
nohup kafka-consumer-perf-test.sh --bootstrap-server $KAFKA_SERVERS --topic kafka-test01 --messages 100000000 &>/tmp/kafka-test/kafka-consumer.log &
# 启动生产者写入数据
nohup kafka-producer-perf-test.sh --num-records 100000000 --record-size 1000 --topic kafka-test01 --throughput 1000000 --producer-props bootstrap.servers="$KAFKA_SERVERS" &> /tmp/kafka-test/kafka-producer.log &
2、执行脚本
| [root@elk121 ~]# bash kafka-test.sh |
|---|
3、停止压测
| [root@elk121 ~]# jps | grep 'ConsumerPerformance\ProducerPerformance' | awk '{print \$1}' | xargs kill |
|---|