

1)kube-scheduler的工作原理如下:
- 监听API Server: kube-scheduler会监听API Server上的Pod对象,以获取需要被调度的Pod信息。它会通过API Server提供的REST API接口获取Pod的信息,例如Pod的标签、资源需求等信息。
- 筛选可用节点: kube-scheduler会根据Pod的资源需求和约束条件(例如Pod需要的特定节点标签)筛选出可用的Node节点。它会从所有注册到集群中的Node节点中选择符合条件的节点。
- 计算分值: kube-scheduler会为每个可用的节点计算一个分值,以决定哪个节点是最合适的。分值的计算方式可以通过调度算法来指定,例如默认的算法是将节点资源利用率和距离Pod的网络延迟等因素纳入考虑。
- 选择节点: kube-scheduler会选择分值最高的节点作为最终的调度目标,并将Pod绑定到该节点上。如果有多个节点得分相等,kube-scheduler会随机选择一个节点。
- 更新API Server: kube-scheduler会更新API Server上的Pod对象,将选定的Node节点信息写入Pod对象的spec字段中,然后通知Kubelet将Pod绑定到该节点上并启动容器。
2)Kube-scheduler调度器内部流转过程
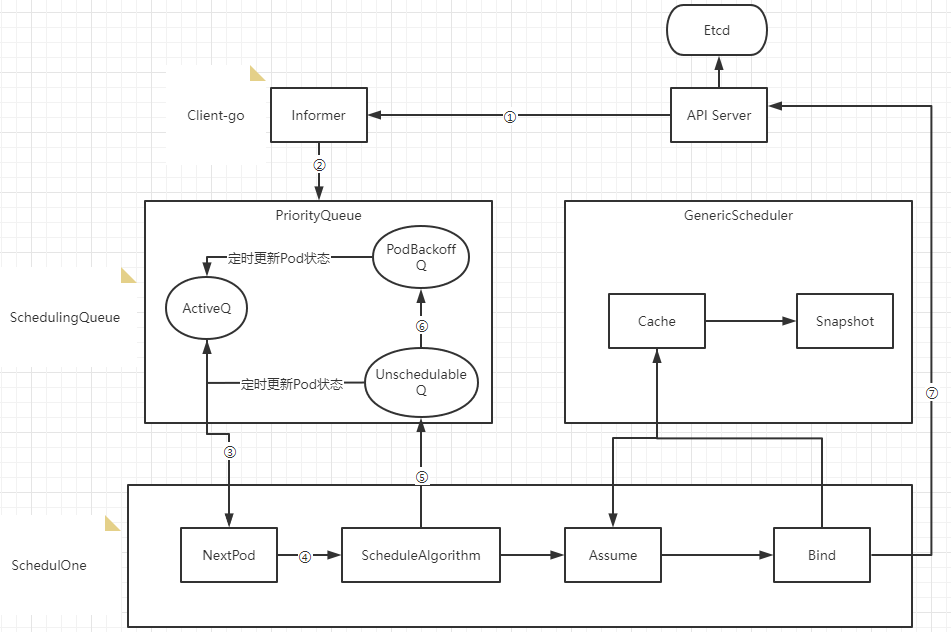
- ① Scheduler通过注册client-go的informer handler方法监听api-server的pod和node变更事件,获取pod和node信息缓存到Informer中
- ② 通过Informer的handler将事件更新到ActiveQ(ActiveQ、UnschedulableQ、PodBackoffQ为三个Scheduling队列,ActiveQ是一个维护着Pod优先级的堆结构,调度器在调度循环中每次从堆中取出优先级最高的Pod进行调度)
- ③ 调度循环通过NextPod方法从ActiveQ中取出待调度队列
- ④ 使用调度算法针对Node和Pod进行匹配和打分确定调度目标节点
- ⑤ 如果调度器出错或失败,会调用shed.Error将Pod写入UnschedulableQ里
- ⑥ 当不可调度时间超过backoff的时间,Pod会由Unschedulable转换到Podbackoff,也就是说Pod信息会写入到PodbackoffQ里
- ⑦ Client-go向Api Server发送一个bind请求,实现异步绑定
调度器在执行绑定操作的时候是一个异步过程,调度器会先在缓存中创建一个和原来Pod一样的Assume Pod对象用模拟完成节点的绑定,如将Assume Pod的Nodename设置成绑定节点名称,同时通过异步执行绑定指令操作。在Pod和Node绑定之前,Scheduler需要确保Volume已经完成绑定操作,确认完所有绑定前准备工作,Scheduler会向Api Server 发送一个Bind 对象,对应节点的Kubelet将待绑定的Pod在节点运行起来。
3)为节点计算分值
节点分值计算是通过调度器算法实现的,而不是固定的。默认情况下,kube-scheduler采用的是DefaultPreemption算法,其计算分值的方式包括以下几个方面:
- 节点的资源利用率 kube-scheduler会考虑每个节点的CPU和内存资源利用率,将其纳入节点分值的计算中。资源利用率越低的节点得分越高。
- 节点上的Pod数目 kube-scheduler会考虑每个节点上已经存在的Pod数目,将其纳入节点分值的计算中。如果节点上已经有大量的Pod,新的Pod可能会导致资源竞争和拥堵,因此节点得分会相应降低。
- Pod与节点的亲和性和互斥性 kube-scheduler会考虑Pod与节点的亲和性和互斥性,将其纳入节点分值的计算中。如果Pod与节点存在亲和性,例如Pod需要特定的节点标签或节点与Pod在同一区域,节点得分会相应提高。如果Pod与节点存在互斥性,例如Pod不能与其他特定的Pod共存于同一节点,节点得分会相应降低。
- 节点之间的网络延迟 kube-scheduler会考虑节点之间的网络延迟,将其纳入节点分值的计算中。如果节点之间的网络延迟较低,节点得分会相应提高。
- Pod的优先级 kube-scheduler会考虑Pod的优先级,将其纳入节点分值的计算中。如果Pod具有高优先级,例如是关键业务的部分,节点得分会相应提高。
这些因素的相对权重可以通过kube-scheduler的命令行参数或者调度器配置文件进行调整。需要注意的是,kube-scheduler的算法是可扩展的,可以根据需要编写自定义的调度算法来计算节点分值。
4)调度策略
- 默认调度策略(DefaultPreemption): 默认调度策略是kube-scheduler的默认策略,其基本原则是为Pod选择一个未满足需求的最小代价节点。如果无法找到这样的节点,就会考虑使用预选,即将一些已经调度的Pod驱逐出去来为新的Pod腾出空间。
- 带优先级的调度策略(Priority): 带优先级的调度策略基于Pod的优先级对节点进行排序,优先选择优先级高的Pod。该策略可以通过设置Pod的PriorityClass来实现。
- 节点亲和性调度策略(NodeAffinity): 节点亲和性调度策略基于节点标签或其他条件,选择与Pod需要的条件相匹配的节点。这可以通过在Pod定义中使用NodeAffinity配置实现。
- Pod 亲和性调度策略(PodAffinity): Pod 亲和性调度策略根据Pod的标签和其他条件,选择与Pod相似的其他Pod所在的节点。这可以通过在Pod定义中使用PodAffinity配置实现。
- Pod 互斥性调度策略(PodAntiAffinity): Pod 互斥性调度策略选择与Pod不相似的其他Pod所在的节点,以避免同一节点上运行相似的Pod。这可以通过在Pod定义中使用PodAntiAffinity配置实现。
- 资源限制调度策略(ResourceLimits): 资源限制调度策略选择可用资源最多的节点,以满足Pod的资源需求。这可以通过在Pod定义中使用ResourceLimits配置实现。