1、添加Prometheus告警规则
$ vi prometheus_config.yaml
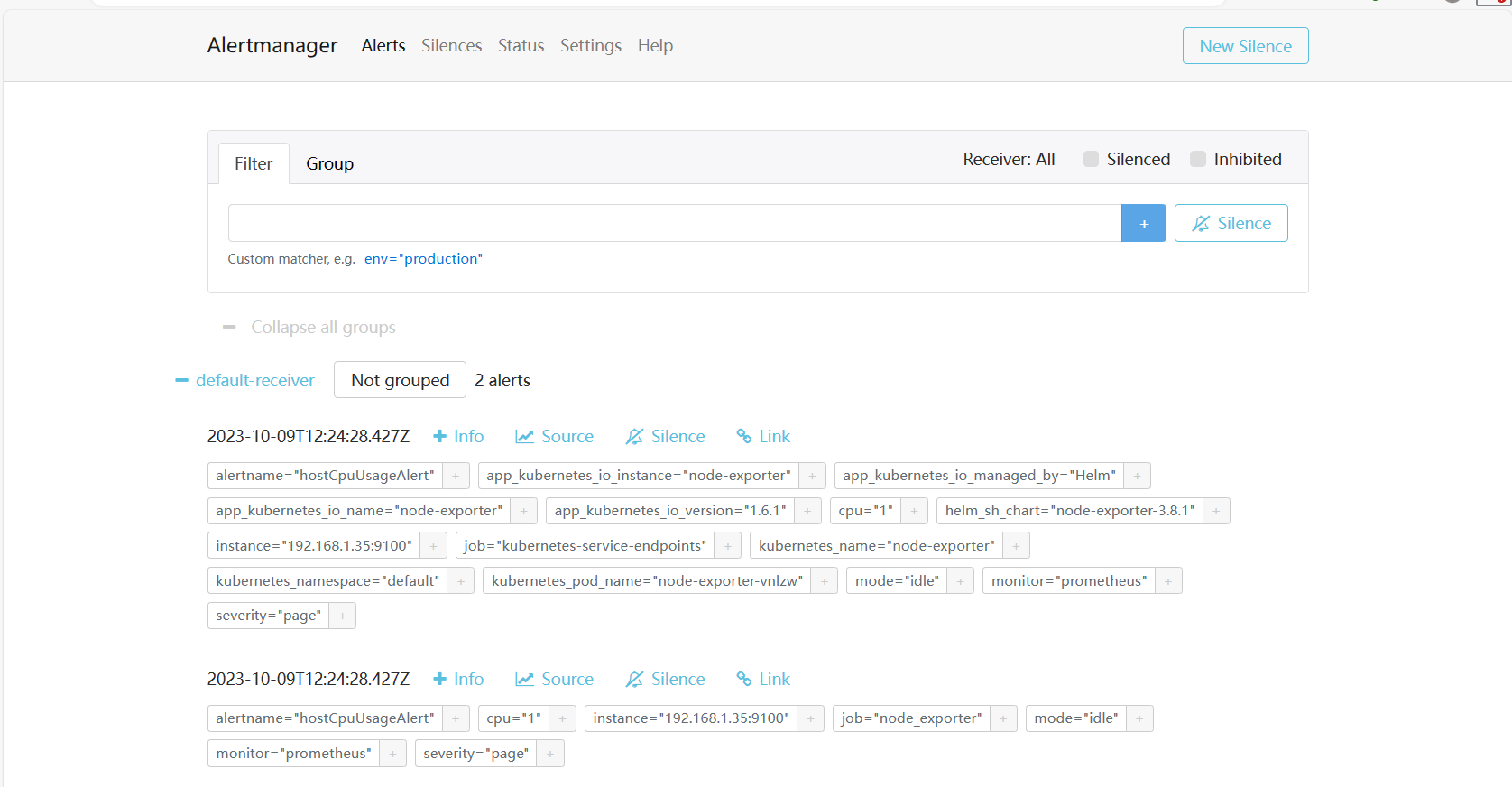
找到rules.yaml,将 rules.yaml: '{}' 改为以下内容
rules.yaml: |
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: 1 - rate(node_cpu_seconds_total{mode="idle"}[2m]) > 0.8
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
上面参数说明:
groups是一个规则组的列表,每个规则组包含一组相关的告警规则。name: hostStatsAlert指定了规则组的名称,这个组中包含了一组与主机统计相关的告警规则。rules是一个告警规则的列表,每个规则包含以下属性:alert:告警规则的名称,用于唯一标识该规则。expr:用于计算告警状态的表达式。这里的表达式使用 Prometheus 的查询语言来定义,在这个示例中,它们分别用于检测 CPU 使用率和内存使用率是否超过阈值。for:指定触发告警所需的连续时间条件。在这个示例中,如果表达式持续满足 1 分钟(1m)以上,才会触发告警。labels:为告警规则指定标签,用于标识告警的严重性等级。annotations:为告警规则添加注释,提供更多的信息,如告警摘要和描述。
2、重新apply
$ kubectl delete -f prometheus_config.yaml ; kubectl apply -f prometheus_config.yaml
3、重启prometheus服务
$ kubectl get po |grep prometheus-server |awk '{print $1}' |xargs -i kubectl delete po {}
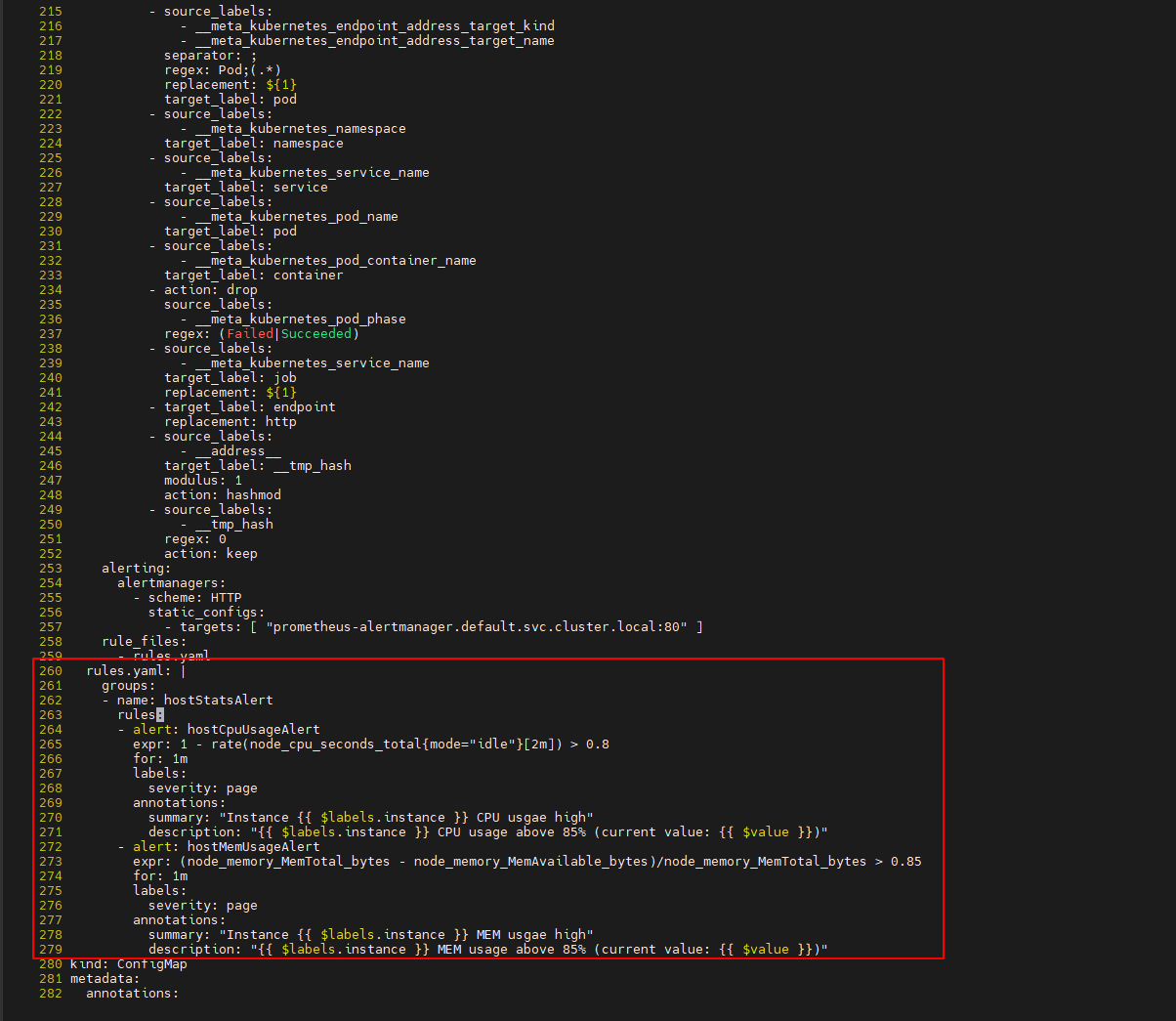
4、打开浏览器输入http://192.168.1.31:31093访问Prometheus,到Prometheus页面下查看rule已经生效
继续查看Alerts

一般Alerts这边包含三个状态
- Inactive : 规则还没有被触发
- Pending: 规则被触发了,在评估等待时间范围内,比如上面的1m
- Firing: 规则被触发了,超过了评估等待时间
5、测试规则
在192.168.1.35上模拟CPU使用偏高,需要执行两次
$ cat /dev/zero > /dev/null &
在192.168.1.35上查看CPU使用率
$ top -c
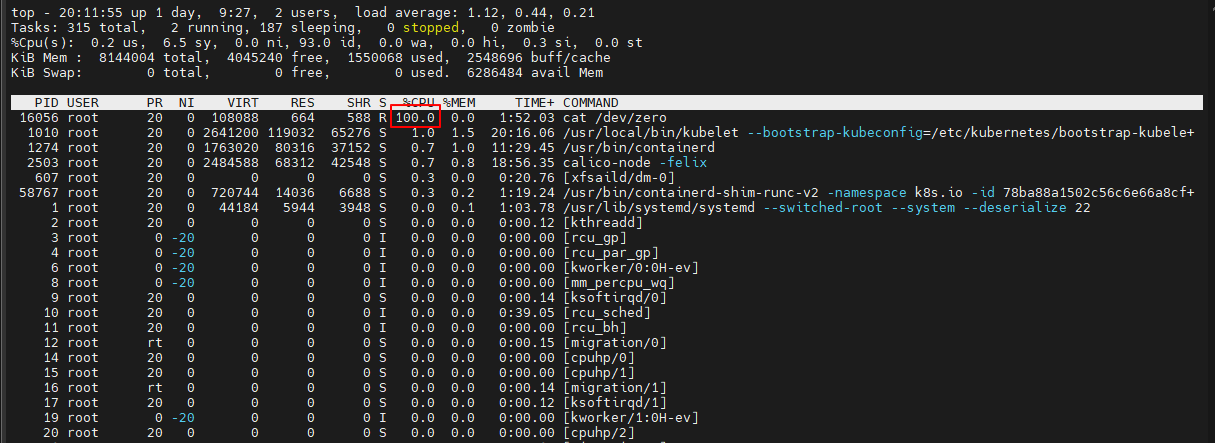
6、等待几分钟后,Prometheus alerts里,cpu那项先变黄色,再变红色

7、打开浏览器,输入http://192.168.1.31:32590访问Alertmanager,可以看到告警