1、示例1:
将如下配置增加到alertmanager_config.yaml里
inhibit_rules:
- source_match: ## 来源匹配器,这里表示当发现alertname标签为NodeDown,并且告警级别为critical时的告警通知发出,则会对target_matchers中匹配的通知进行抑制。
alertname: NodeDown
severity: Critical
target_match: ## 目标匹配器,这里表示对告警级别为critical的告警进行抑制
severity: Critical
equal:
- node ## 表示,来源通知和抑制目标通知需要具有相同的node标签
说明:当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别severity=Critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根据抑制规则的定义,如果有新的告警级别为severity=Critical,并且告警中标签node的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。
2、示例2:
将如下配置增加到alertmanager_config.yaml里
inhibit_rules:
- source_match:
alertname: NodeMemoryUsage
severity: Critical
target_match:
severity: Normal
equal:
- instance
说明:告警规则名字为NodeMemroyUsage,并且告警级别severity为Critical的告警被触发时,则告警级别为Normal,并且告警中标签instance的值与NodeMemoryUsage相同的告警会被抑制,不再发送通知。
3、实战
(1)定义告警规则
正常情况
$ vi prometheus_config.yaml
groups:
- name: hardware
rules:
- alert: systemLoad
expr: node_load1 > 4
for: 1m
labels:
severity: Critical
team: cpu
annotations:
summary: "{{ $labels.instance }} 负载为 {{ $value }} 比较高 "
description: "主机1分钟负载超过4"
value: "{{ $value }}"
- alert: cpuUsage
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 1m
labels:
severity: Critical
team: cpu
annotations:
summary: "{{$labels.instance}} CPU使用率为{{ $value }} 太高"
description: "{{$labels.instance }} CPU使用大于80%"
value: "{{ $value }}%"
- alert: MemUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 85
for: 1m
labels:
severity: Critical
team: mem
annotations:
summary: "{{$labels.instance}} 内存使用率 {{ $value }}% 过高!"
description: "{{$labels.instance }} 内存使用大于85%"
value: "{{ $value }}%"
演示情况
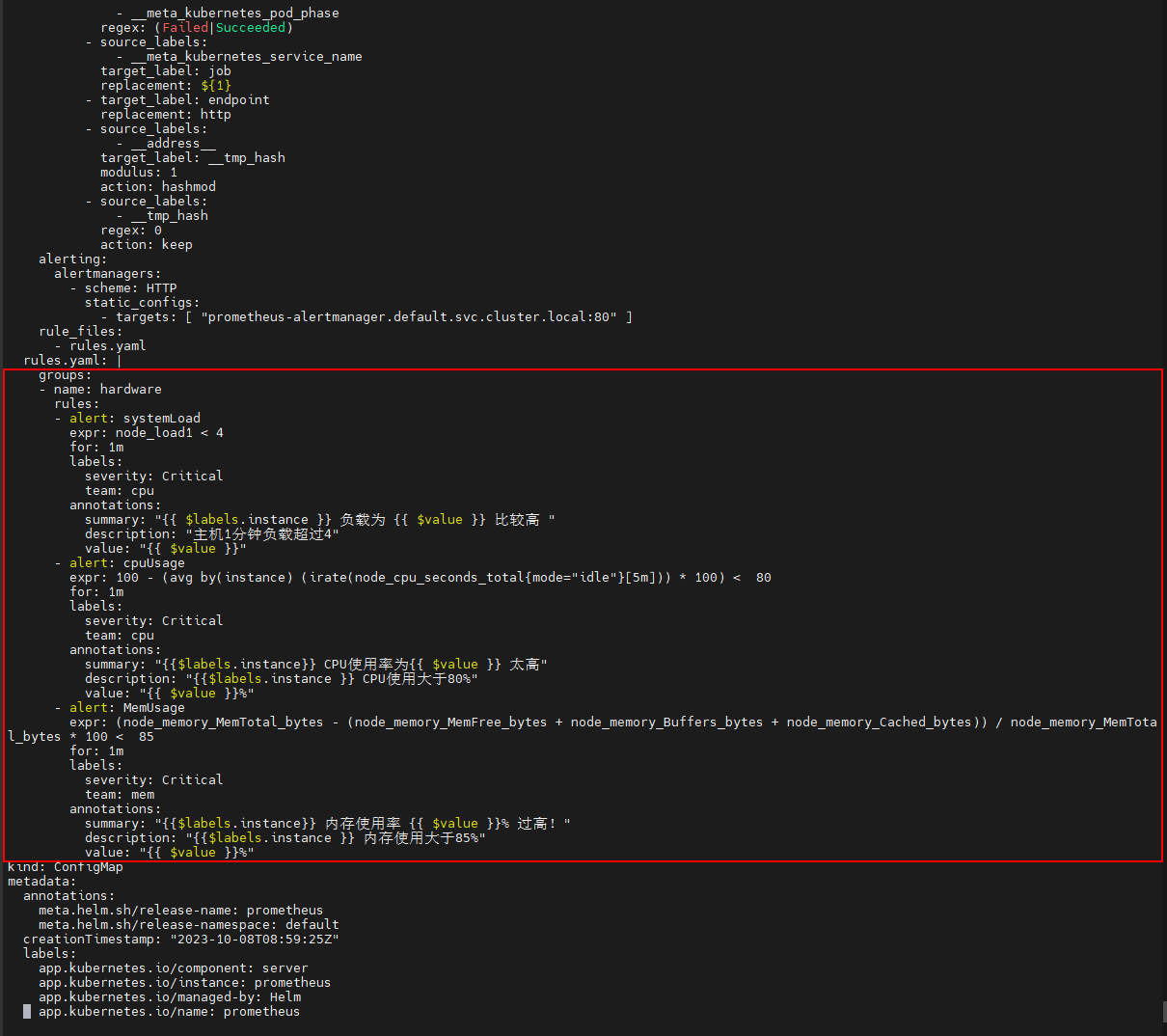
$ vi prometheus_config.yaml
groups:
- name: hardware
rules:
- alert: systemLoad
expr: node_load1 < 4
for: 1m
labels:
severity: Critical
team: cpu
annotations:
summary: "{{ $labels.instance }} 负载为 {{ $value }} 比较高 "
description: "主机1分钟负载超过4"
value: "{{ $value }}"
- alert: cpuUsage
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) < 80
for: 1m
labels:
severity: Critical
team: cpu
annotations:
summary: "{{$labels.instance}} CPU使用率为{{ $value }} 太高"
description: "{{$labels.instance }} CPU使用大于80%"
value: "{{ $value }}%"
- alert: MemUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 < 85
for: 1m
labels:
severity: Critical
team: mem
annotations:
summary: "{{$labels.instance}} 内存使用率 {{ $value }}% 过高!"
description: "{{$labels.instance }} 内存使用大于85%"
value: "{{ $value }}%"
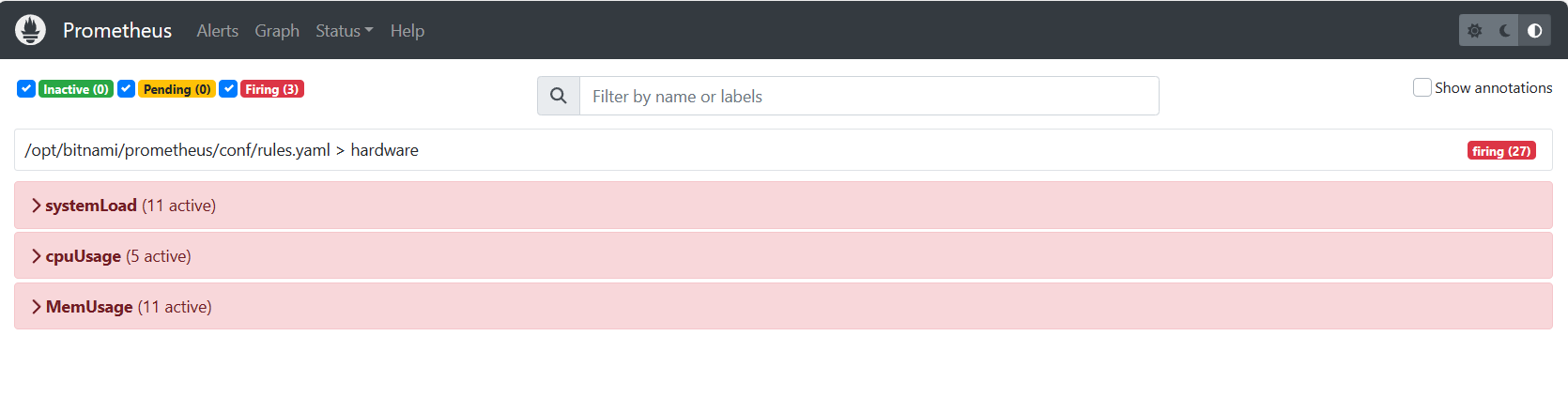
(2)重新配置prometheus-server及重启prometheus-server
$ kubectl delete cm prometheus-server ; kubectl apply -f prometheus_config.yaml
$ kubectl get po |grep 'prometheus-server'|awk '{print $1}' |xargs -i kubectl delete po {}
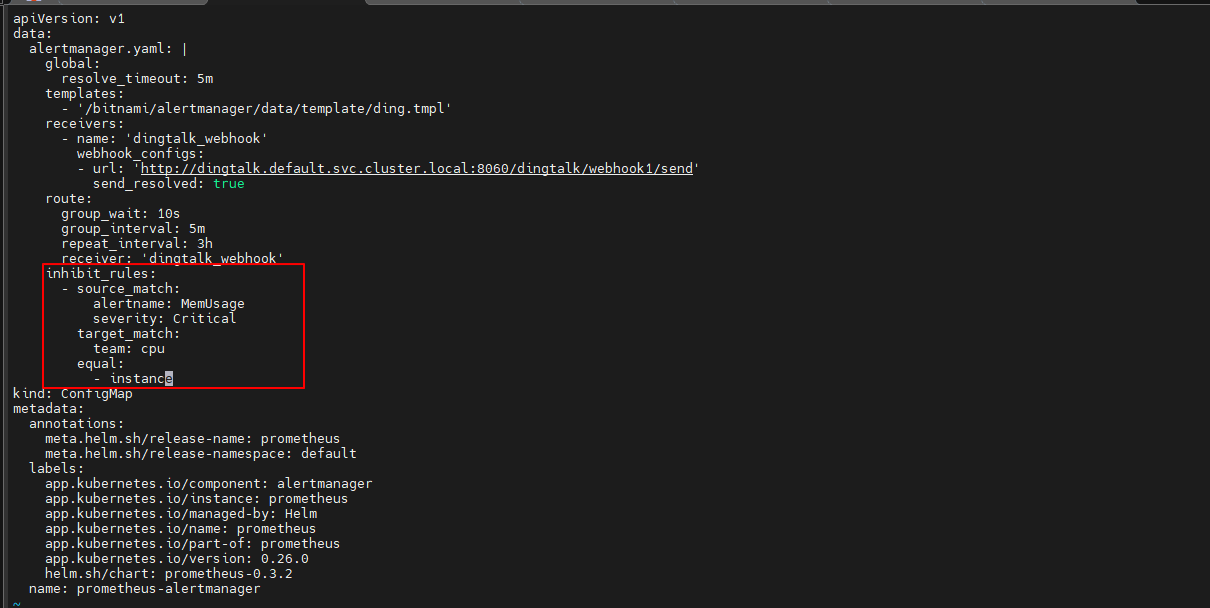
(3)定义抑制规则,在route下面添加如下内容
$ vi alertmanager_config.yaml
...
...
inhibit_rules:
- source_match:
alertname: MemUsage
severity: Critical
target_match:
team: cpu
equal:
- instance
(4)重新配置prometheus-server及重启prometheus-server
$ kubectl delete cm prometheus-alertmanager; kubectl apply -f alertmanager_config.yaml
$ kubectl get po |grep 'prometheus-alertmanager'|awk '{print $1}' |xargs -i kubectl delete po {}
4、在192.168.1.35上模拟CPU使用偏高,需要执行两次
$ cat /dev/zero > /dev/null &
5、打开浏览器输入http://192.168.1.31:31093访问Prometheus,到Prometheus页面下查看告警