

一、前言¶
在日常的工作中,我们可能会遇到当请求后端服务,响应过慢的时候,为了不产生积压请求,不拖垮其他服务,这个时候大家一般会怎么解决呢?
那有小伙伴可能会说到,代码中增加超时的逻辑对吧?
今天咱们通过 Istio 的主动注入故障,返回超时信息来优化请求成功率,提升系统容错性能。
主动注入故障可以减少等待时消耗的资源,避免请求积压,避免级联错误问题。超时也可以设置在代码中,一旦编译运行则无法修改,而 Istio 则可通过灵活配置及时生效。
另外还有istio还有重试机制,重试的意思是在网络环境不稳定的情况下,如网络波动、丢包等偶发网络不可达的现象,为了解决这种偶发问题,重试则是很好的解决方法。
下面我们来看下在 Istio 中,如何通过超时和重试来实现弹性和故障注入,以提高应用程序的可靠性和容错性。
三个核心概念:
-
超时(Timeout):超时机制用于定义请求在未收到响应时的等待时间。我们可以为服务配置超时 策略,例如设置最大等待时间或指定特定的超时时间。如果请求的响应时间超过了定义的超时时间,Istio 将终止该请求并返回适当的错误响应。
-
重试(Retry):重试机制可在请求失败时自动尝试重新发送请求。咱们可以配置重试策略,例如设置最大重试次数、重试间隔和重试条件。当请求失败时,Istio 会根据配置进行自动重试,以增加请求的成功率和可靠性。
-
故障注入(Fault Injection):故障注入允许模拟各种故障情况,以测试应用程序的容错能力。Istio 提供了故障注入功能,可以注入延迟和错误来模拟不同的故障场景。您可以指定要注入的故障类 型、延迟时间、错误率等。通过故障注入,大家可以验证系统在面对不可避免的错误和故障时的表现。
二、弹性(超时&重试)¶
Istio 提供了些功能,可以在服务遇到某些偶发性的故障或某些特殊状况(例如:接近负载上限)而短时间无法正常运行时,可以提供保持可接受服务水准的能力;
这些功能不是为了避免服务故障,而是尝试在没有停机或数据丢失的前提下面对服务故障的状况,目标是在服务发生故障时可以恢复到正常的状态。
因此 Istio 中提供了 timeout & retry 的机制,可以用来将这两个机制套用在 Virtual Service 上。
2.1 超时(timeout)¶
下面是一个为路由设置超时的例子:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-service
spec:
hosts:
- customers.example.com
http:
- route:
- destination:
host: customers.default.svc.cluster.local
port:
number: 8080
timeout: 5s
2.2 重试(retry)¶
除了超时之外,我们还可以配置更细化的重试策略。我们可以 控制一个给定请求的重试次数,每次尝试的超时时间,以及我们想要重试的具体条件。
例如,我们可以只在上游服务器返回 5xx 响应代码时重试请求,或者只在网关错误(HTTP 502、503 或 504)时重试,或者甚至在请求头中指定可重试的状态代码。重试和超时都发生在客户端。当 Envoy 重 试一个失败的请求时,最初失败并导致重试的端点就不再包含在负载均衡池中了。
假设 Kubernetes 服务有 3 个端点(Pod),其中一个失败了,并出现了可重试的错误代码。当 Envoy 重试请求时,它不会再向原来的端点重新发送请求。相反,它将把请求发送到两个没有失败的端点中的 一个。
下面是一个例子,说明如何为一个特定的目的地设置重试策略。
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-service
spec:
hosts:
- customers.example.com
http:
- route:
- destination:
host: customers.default.svc.cluster.local
port:
number: 8080
retries:
attempts: 10
perTryTimeout: 2s
retryOn: connect-failure,reset
上述重试策略将尝试重试任何 连接超时( connect-failure )或服务器完全不响应( reset )的失败请求。
我们将每次尝试的超时时间设置为 2 秒,尝试的次数设置为 10 次。注意,如果同时设置重试和超时,超时值将是请求等待的最长时间。
如果我们在上面的例子中指定了 10 秒的超时,那么即使重试策略中还剩下一些尝试,我们也只能最多等待 10 秒。
关于重试策略的更多细节,请参阅x-envoy-retry-on 文档。
三、故障注入¶
在微服务的架构中,服务之间互相发送请求是频繁发生的行为,而我们无法保证上游服务 100% 都没问 题,也许有时候会有偶发性的故障,甚至一段时间无法提供服务。为了提升服务应对上游服务(upstream service)故障时的能力,我们可以在上游服务中设定一些 故障注入规则 来模拟对上游服务进行请求时发 生故障时的情况;若是在上游服务故障的情况下,服务都可以正常运行,那表示服务不会因为上游服务的问题导致自身故障,进而提升服务的稳定性。
在 Istio 中提供了两种故障注入,分别是 delay & abort 以下分别进行说明。
3.1 delay¶
Istio 的延迟故障注入是一种用于模拟服务之间通信中可能出现的延迟问题的机制。它允许开发人员在测试和调试过程中有目的地引入延迟,以验证系统在面对实际延迟情况时的行为。
延迟故障注入的主要目的是评估系统的弹性和容错性。通过在请求的不同阶段引入带有随机或指定时间 延迟的响应,可以模拟真实环境中可能发生的网络延迟、服务调用延迟或其他操作延迟的情况。
通过使用 Istio 中的延迟故障注入功能,可以进行以下测试:
- 容错性评估:模拟外部服务的响应速度下降的情况,以确保系统能够适应潜在的延迟并继续正常工 作。
- 失败处理:验证服务是否正确处理因延迟而导致的超时或其他错误条件,并采取适当的处理措施, 例如重试、降级或回退策略。
- 性能优化:通过模拟延迟,可以更好地了解系统在高延迟环境下的性能特征,并识别和解决潜在的 性能瓶颈。
总结:延迟故障注入是进行系统可靠性和容错性测试的重要工具,可以帮助开发人员更好地了解和优化 系统在不同条件下的行为。它能够提供对系统鲁棒性和性能的有价值的洞察,并支持构建更稳定和可靠 的分布式应用程序。
延迟故障注入的例子:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: customers-service
spec:
hosts:
- customers.example.com
http:
- route:
- destination:
host: customers.default.svc.cluster.local
fault:
delay:
fixedDelay: 5s
percentage:
value: 50
在路由规则中,我们添加了一个名为 "fault" 的字段,用于配置故障注入。在这个例子中,我们设置了以下延迟故障参数:
- fixedDelay: 5s :指定延迟的时间为 5 秒。
- percentage: value: 50 :指定注入故障的百分比为 50%。
这样,当客户端发送请求到 customers-service 上,有 50% 的概率会遇到 5 秒钟的延迟。
3.2 abort¶
Istio 的中止故障注入是一种用于模拟服务之间通信中可能发生异常情况的机制。它允许开发人员在测试和调试过程中有目的地引入错误,以验证系统在面对异常情况时的行为。
中止故障注入的主要目的是评估系统的容错性和恢复能力。通过在请求的不同阶段引入错误,例如返回特定的 HTTP 错误码、终止连接或返回无效的响应,可以模拟真实环境中可能出现的故障情况。
通过使用 Istio 中的中止故障注入功能,可以进行以下测试:
- 容错性评估:验证系统是否能够正确处理由于外部服务故障而导致的错误条件,例如超时、连接中断或无效响应。
- 异常处理:验证服务是否能够适当地处理异常情况,并采取适当的补救措施,例如进行重试、回退或错误处理。
- 故障恢复:评估系统在遇到错误后的恢复能力,包括重新连接、重建状态或执行其他必要的操作。
总结:中止故障注入是进行系统容错性和可靠性测试的重要工具,可以帮助开发人员更好地了解和优化 系统在异常情况下的行为。它能够提供对系统鲁棒性和可恢复性的有价值的洞察,并支持构建更健壮和可靠的分布式应用程序。
中断故障注入的例子:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: customers-service
spec:
hosts:
- customers.example.com
http:
- route:
- destination:
host: customers.default.svc.cluster.local
fault:
abort:
httpStatus: 500
percentage:
value: 10
在路由规则中,我们添加了一个名为 "fault" 的字段,用于配置故障注入。在这个例子中,我们设置了以下中断故障参数:
- httpStatus: 500 :指定返回的 HTTP 状态码为 500。
- percentage: value: 10 :指定注入故障的百分比为 10%。
这样,当客户端发送请求到 customers-service 上,有 10% 的概率会遇到返回 500 的错误状态码, 中断请求。
四、实战:观察错误注入¶
4.1 在 Grafana、Zipkin 和 Kiali 中观察故障注入和延迟情况¶
在这个实验中,我们将部署 Web 前端和 Customer V1 服务。然后,我们将在 Zipkin、Kiali 和 Grafana 中注入故障和延迟,并观察它们。

先针对 default 命名空间进行流量注入:
[root@master01 istioyaml]# kubectl label ns default istio-injection=enabled
[root@master01 istioyaml]# kubectl get ns -l istio-injection
NAME STATUS AGE
default Active 272d
microservice Active 17h
然后部署 Gateway:
#网关暴露80端口
[root@master01 istioyaml]# vim ingressgateway.yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- '*'
[root@master01 istioyaml]# kubectl apply -f ingressgateway.yaml
#网关创建成功
[root@master01 istioyaml]# kubectl get gateway.networking.istio -o wide
NAME AGE
gateway 13s
接下来,我们将部署 Web Frontend、Service 和 VirtualService。
[root@master01 istioyaml]# vim web-frontend-3.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-frontend
labels:
app: web-frontend
spec:
replicas: 1
selector:
matchLabels:
app: web-frontend
template:
metadata:
labels:
app: web-frontend
version: v1
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/github_images1024/web-frontend:1.0.0
imagePullPolicy: Always
name: web
ports:
- containerPort: 8080
env:
- name: CUSTOMER_SERVICE_URL
value: 'http://customers.default.svc.cluster.local'
---
kind: Service
apiVersion: v1
metadata:
name: web-frontend
labels:
app: web-frontend
spec:
selector:
app: web-frontend
ports:
- port: 80
name: http
targetPort: 8080
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: web-frontend
spec:
hosts:
- '*'
gateways:
- gateway
http:
- route:
- destination:
host: web-frontend.default.svc.cluster.local
port:
number: 80
将上述 YAML 保存为 web-frontend-3.yaml ,并使用 kubectl apply -f web-frontend-3.yaml 创建资源。
[root@master01 istioyaml]# kaf web-frontend-3.yaml
#验证
[root@master01 istioyaml]# kg -f web-frontend-3.yaml
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/web-frontend 1/1 1 1 23s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/web-frontend ClusterIP 192.168.175.157 <none> 80/TCP 23s
NAME GATEWAYS HOSTS AGE
virtualservice.networking.istio.io/web-frontend ["gateway"] ["*"] 23s
最后,我们将部署 Customers v1 和相应的资源。
[root@master01 istioyaml]# vim customers-delay.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: customers-v1
labels:
app: customers
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: customers
version: v1
template:
metadata:
labels:
app: customers
version: v1
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/github_images1024/customers:1.0.0
imagePullPolicy: Always
name: svc
ports:
- containerPort: 3000
---
kind: Service
apiVersion: v1
metadata:
name: customers
labels:
app: customers
spec:
selector:
app: customers
ports:
- port: 80
name: http
targetPort: 3000
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: customers
spec:
host: customers.default.svc.cluster.local
subsets:
- name: v1
labels:
version: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: customers
spec:
hosts:
- 'customers.default.svc.cluster.local'
http:
- route:
- destination:
host: customers.default.svc.cluster.local
port:
number: 80
subset: v1
fault:
delay:
percent: 50
fixedDelay: 5s
将上述 YAML 保存为 customers-delay.yaml ,并使用 kubectl apply -f customers-delay.yaml更新 VirtualService
[root@master01 istioyaml]# kaf customers-delay.yaml
如上,当前端流量发送请求到 customers-service 上,有 50% 的概率会遇到 5 秒钟的延迟。
验证:
[root@master01 istioyaml]# kubectl get dr,vs,gw
NAME HOST AGE
destinationrule.networking.istio.io/customers customers.default.svc.cluster.local 21s
NAME GATEWAYS HOSTS AGE
virtualservice.networking.istio.io/customers ["customers.default.svc.cluster.local"] 21s
virtualservice.networking.istio.io/web-frontend ["gateway"] ["*"] 86s
NAME AGE
gateway.networking.istio.io/gateway 2m42s
为了产生一些流量,让我们打开一个单独的终端窗口,开始向 GATEWAY_URL 发出无穷的循环请求。
$ while true; do curl http://10.0.0.12/; done
我们应该开始注意到一些请求的时间比平时长。让我们打开 Grafana 并观察这些延迟。
http://grafana-istio.zhang-qing.com/
当 Grafana 打开时,点击主页和 Istio Service Dashboard。在仪表板上,确保在服务下拉菜单中选择customers.default.svc.cluster.local 。
如果你展开 Client Workload 面板,你会发现客户端请求持续时间图上的持续时间增加了,如下图所示。

让我们看看这个延迟在 Zipkin 中是如何显示的。用 http://zipkin-istio.zhang-qing.com/zipkin/ 打开Zipkin。
在主屏幕上,选择 serviceName=web-frontend.default和minDurationminDuration=5s,点击搜索按钮,找到 trace。
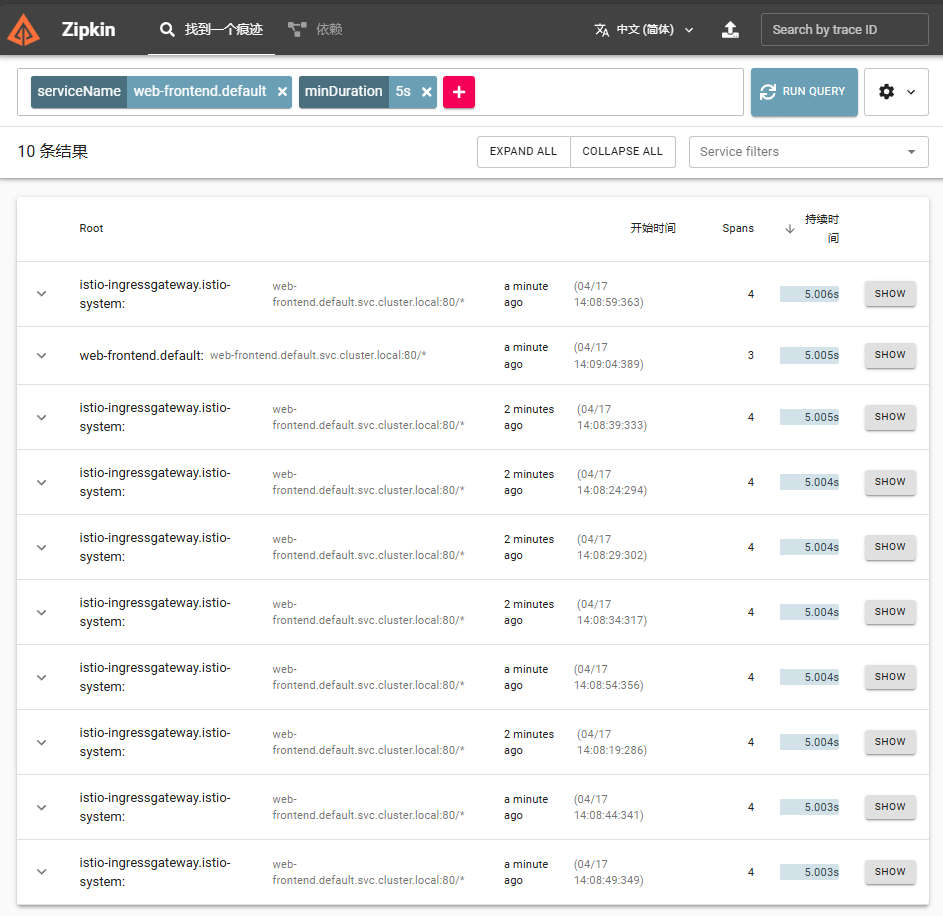
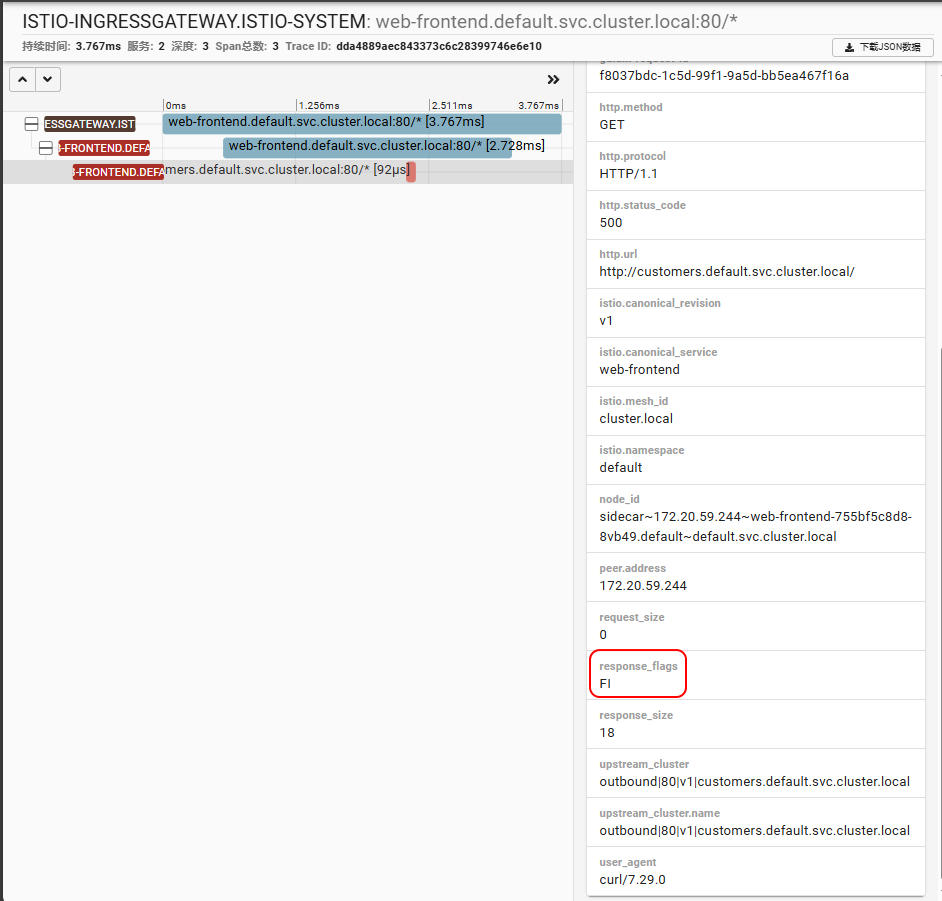
点击其中一个 trace,打开详细信息页面。在详情页上,我们会发现持续时间是 5 秒。
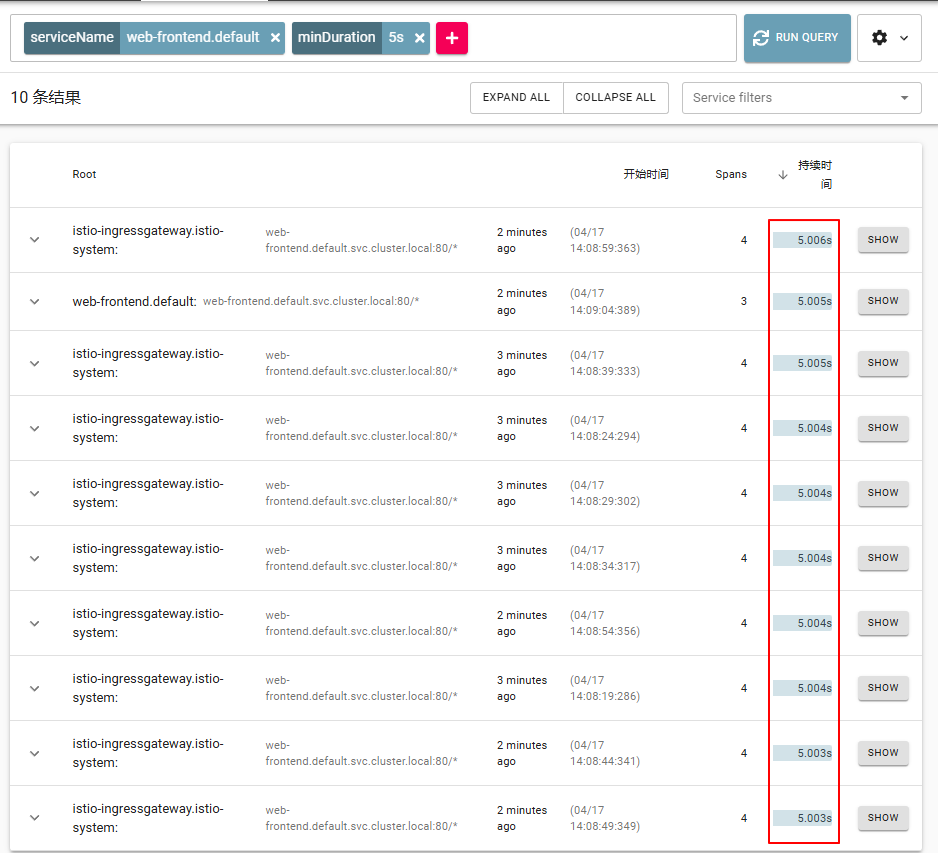
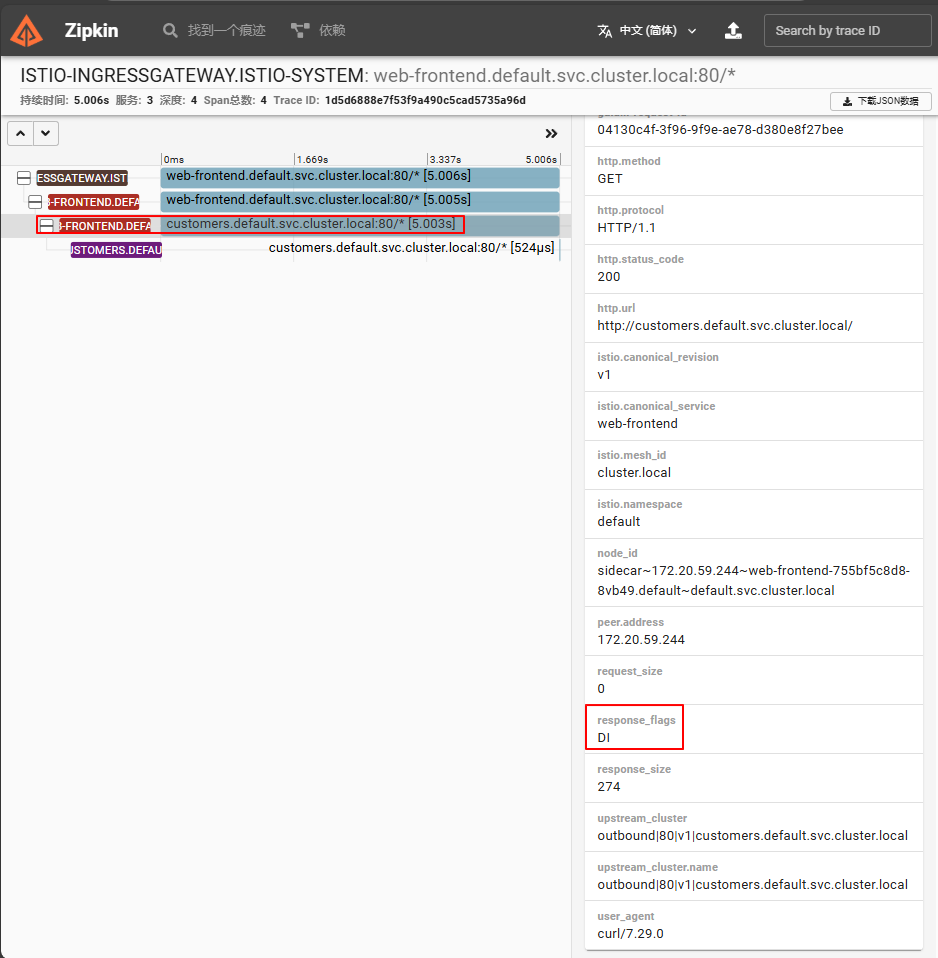
单个 trace 有 4 个 span——点击 3 个跨度,代表从 web-frontend 到客户服务的请求。
你会注意到在细节中, response_flags 标签设置为 DI 。"DI" 代表 "延迟注入",表示该请求被延迟了。
让我们再次更新 VirtualService,这一次,我们将注入一个故障,对 50% 的请求返回 HTTP 500。
[root@master01 istioyaml]# vim customers-fault.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: customers
spec:
hosts:
- 'customers.default.svc.cluster.local'
http:
- route:
- destination:
host: customers.default.svc.cluster.local
port:
number: 80
subset: v1
fault:
abort:
httpStatus: 500
percentage:
value: 50
将上述 YAML 保存为 customers-fault.yaml ,然后用 kubectl apply -f customers-fault.yaml更新 VirtualService。
[root@master01 istioyaml]# kaf customers-fault.yaml
就像前面一样,我们将开始注意到来自请求循环的失败。我们会注意到客户端的成功率在下降,并且在 按来源和响应代码划分的传入请求图上 500 响应在增加,如图所示:
[root@master01 istioyaml]# while true; do curl http://10.0.0.12/ -i |grep status ; done
整体错误率占比约为50%左右;

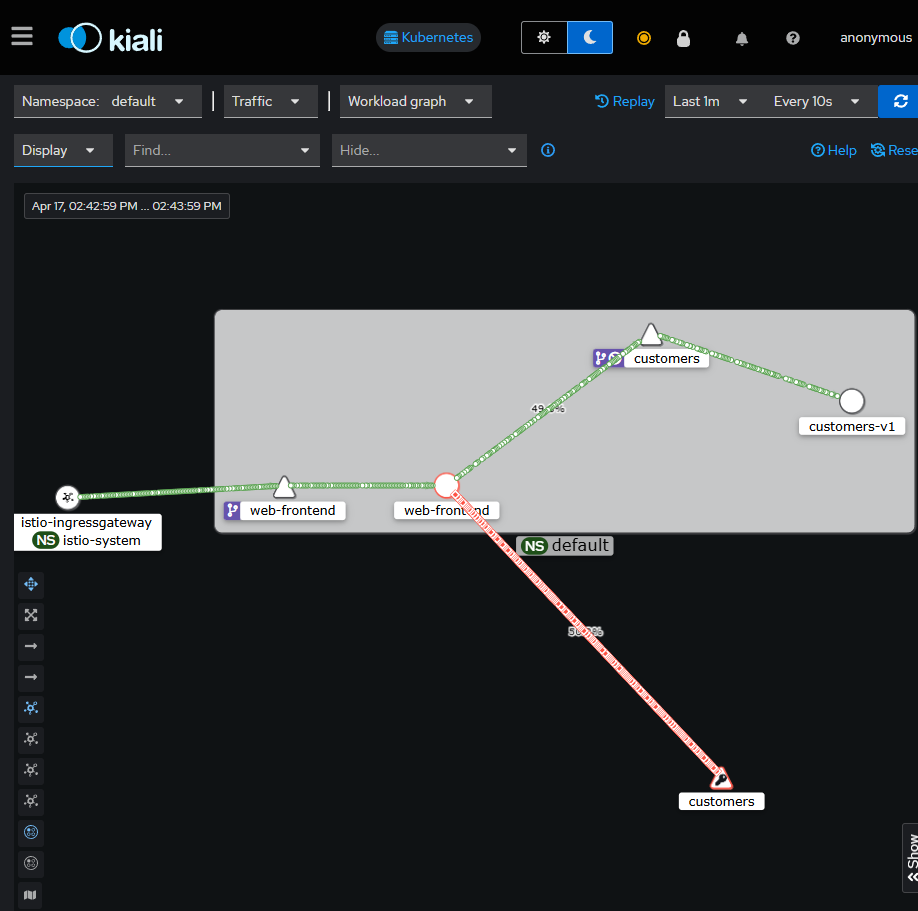
用 http://kiali-istio.zhang-qing.com/打开kiali,点击【Graph】,Namespace选择default,再选择Workload graph进行观察,观察到一条链路正常,一条链路异常
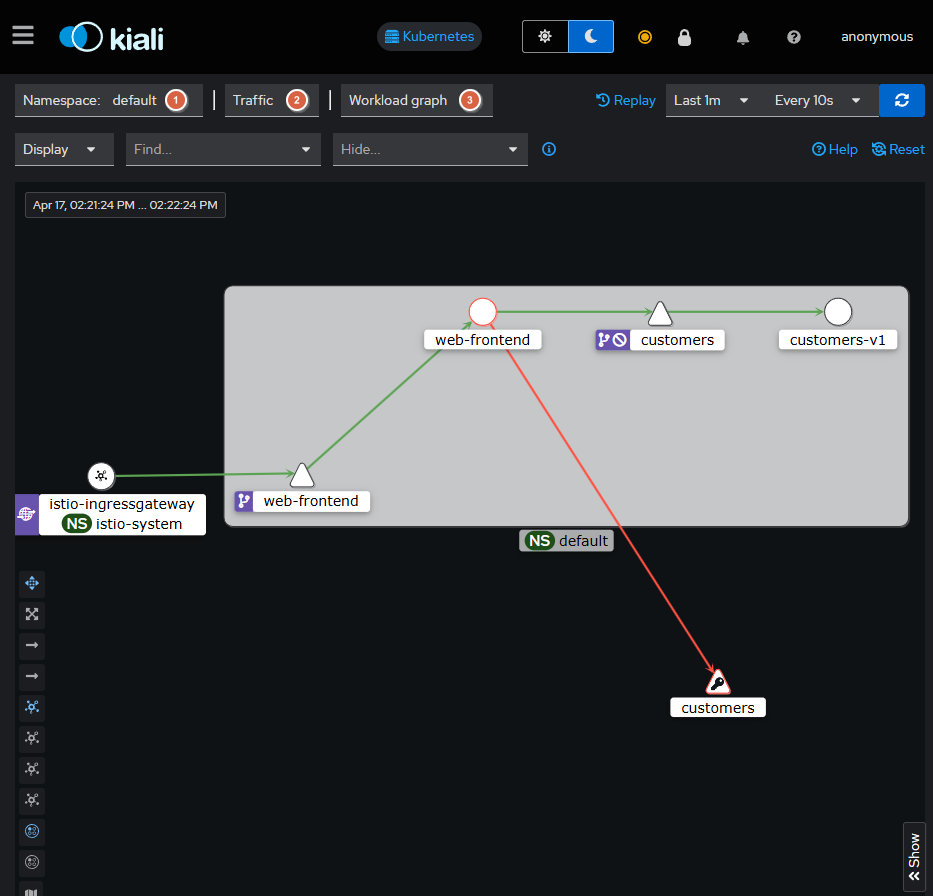
说明:
- 如果想展示传输成功率,需要依次点击【Display】-【Traffic Distribution】
- 如果想展示传输走向,需要依次点击【Display】-【Traffic Animation 】
展示效果图:
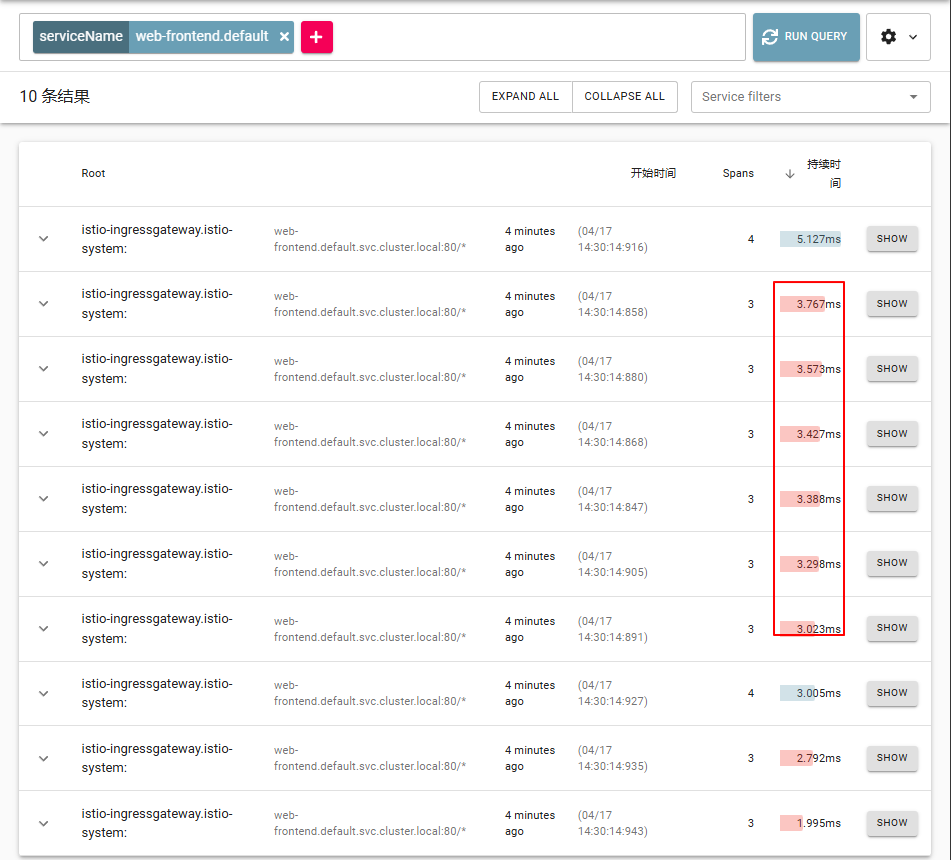
在 Zipkin 中也有类似的情况,用 http://zipkin-istio.zhang-qing.com/zipkin/ 打开Zipkin。如果我们再次输入serviceName=web-frontend.default搜索 trace(我们可以删除最小持续时间),我们会发现有错误的 trace 会以红色显示,如下图所示。
让我们也打开 Kiali ,通过点击 Graph 项查看服务图。你会注意到 web-frontend 服务有一个红色的边框,如下图所示。

如果我们点击 web-frontend 服务,看看右边的侧边栏,你会发现 HTTP 请求的细节。图中显示了成功 和失败的百分比,这两个数字都在 50% 左右,这与我们在 VirtualService 中设置的百分比值相一致。
4.2 清理¶
删除 Deployment、Service、VirtualService、DestinationRule 和 Gateway。
kubectl delete deploy web-frontend customers-v1
kubectl delete svc customers web-frontend
kubectl delete vs.networking.istio customers web-frontend
kubectl delete gateway.networking.istio gateway
五、总结¶
Istio是一个用于管理、连接和保护微服务的开源平台,它提供了多种功能来增强和保障微服务架构的稳 定性和可靠性。其中,超时、重试、延迟(delay)和中止(abort)是四种常用的故障注入手段。下面是对这些功能的总结:
- 超时(Timeout):超时是指在规定的时间内,如果服务没有及时响应,则认为该请求已经失败。 通过设置超时时间,可以验证系统对于处理响应超时的情况的能力。Istio允许您配置请求的超时时间,并在超时时返回适当的错误响应。
- 重试(Retry):重试是一种机制,用于在服务不可用或请求失败的情况下,重新发送请求。通过配 置重试策略,可以让系统在第一次请求失败后自动进行重试操作。Istio允许您定义重试次数、重试 间隔和重试条件等参数,以确保请求能够成功完成。
- 延迟(Delay):延迟是指在请求流程中故意引入一定的延迟时间。通过延迟故障注入,可以模拟网络延迟、服务处理慢或其他潜在问题。这有助于测试系统在延迟情况下的性能、稳定性和容错能力。
- 中止(Abort):中止是一种故障注入手段,用于模拟服务在请求处理过程中突然中止的情况。通 过中止故障注入,可以验证系统对于服务中止、异常状态码或其他错误情况的处理能力。这有助于测试系统的容错机制和错误处理策略。
总结:超时、重试、延迟和中止是Istio提供的重要故障注入功能。它们可以帮助测试和验证微服务架构 的稳定性、可靠性、容错能力以及错误处理能力。合理使用这些功能可以发现潜在问题,并优化系统的性能和可用性。