

一、L7持续交付平台化¶
1.1 持续交付平台的设计¶
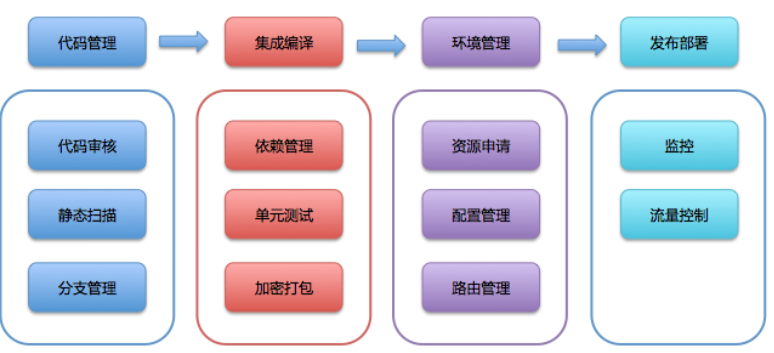
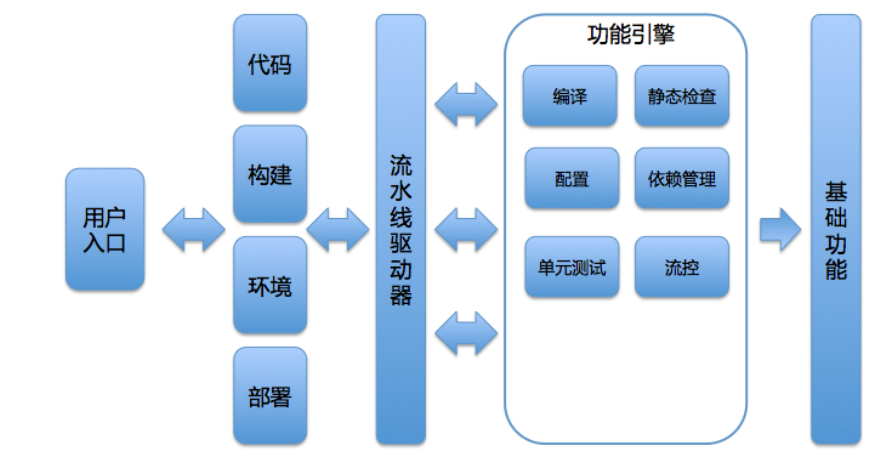
持续交付平台最终将完成这个端到端的过程,那么流水线的每一步都可以认为是一个模块。由此,整个平台的核心模块就是:代码管理、集成编译、环境管理、发布部署。
这四个模块是持续交付平台中最核心,最容易做到内聚和解耦的模块。每个核心模块的周围,又围绕着各种子模块,比如:
- 代码管理模块,往往会和代码审核、静态扫描和分支管理等模块相联系;
- 集成编译模块,也会与依赖管理、单元测试、加密打包等模块相生相随的;
- 环境管理模块,离不开配置管理、路由管理等模块;
- 发布部署模块,还需要监控模块和流控模块的支持。
1.2 持续交付中有哪些宝贵数据¶
1.2.1 常规系统指标数据列举¶
- 第一类指标,稳定性相关指标
作为基础服务,稳定性是我们的生命线。所以,对于所有的子系统,包括:代码管理平台、集成编译系统、环境管理系统、测试管理系统和发布系统,我们都会设立必要的稳定性指标,并进行数据监控。这些稳定性相关的数据指标,代表整个系统的可用度。
- 第二类指标,性能相关指标
与系统性能相关的指标,通常可以直接反应系统的处理能力,以及计算资源的使用情况。更重要的是,速度是我们对用户服务能力的直观体现。很多时候,系统的处理速度上去了,一些问题也就不再是问题了。
- push 和 fetch 代码的速度;
- 环境创建和销毁的速度;
- 产生仿真数据的速度;
- 平均编译速度及排队时长;
- 静态检查的速度;
- 自动化测试的耗时;
-
发布和回滚的速度。
-
第三类指标,持续交付能力成熟度指标
不同的子系统,我关注的指标也不同。
- 与代码管理子系统相关的指标包括:commit 的数量,code review 的拒绝率,并行开发的分支数量。 这里需要注意的是,并行开发的分支数量并不是越多越好,而是要以每个团队都保持一个稳定状态为优。
- 与环境管理子系统相关的指标包括:计算资源的使用率,环境的平均大小。 这里需要注意的是,我一直都很关注环境的平均大小这个数据。因为我们鼓励团队使用技术手段来避免产生巨型测试环境,从而达到提高利用率、降低成本的目的。而且,这个指标也可以从侧面反映一个团队利用技术解决问题的能力。
- 与集成编译子系统相关的指标包括:每日编译数量,编译检查的数据。 我们并不会强制要求编译检查出的不良数据要下降,因为它会受各类外部因素的影响,比如历史代码问题等等。但,我们必须保证它不会增长。这也是我们的团队在坚守质量关的体现。
- 与测试管理子系统相关的指标包括:单元测试的覆盖率,自动化测试的覆盖率。 这两个覆盖率代表了组织通过技术手段保证质量的能力,也是测试团队最常采用的数据指标。
- 与发布管理子系统相关的指标包括:周发布数量,回滚比率。
发布数量的增加,可以最直观地表现交付能力的提升;回滚比率,则代表了发布的质量。综合使用周发布数量和回滚比例这两个指标,就可以衡量整个团队的研发能力是否得到了提升。
二、L8实践案例¶
2.1 快速构建持续交付系统(一):需求分析¶
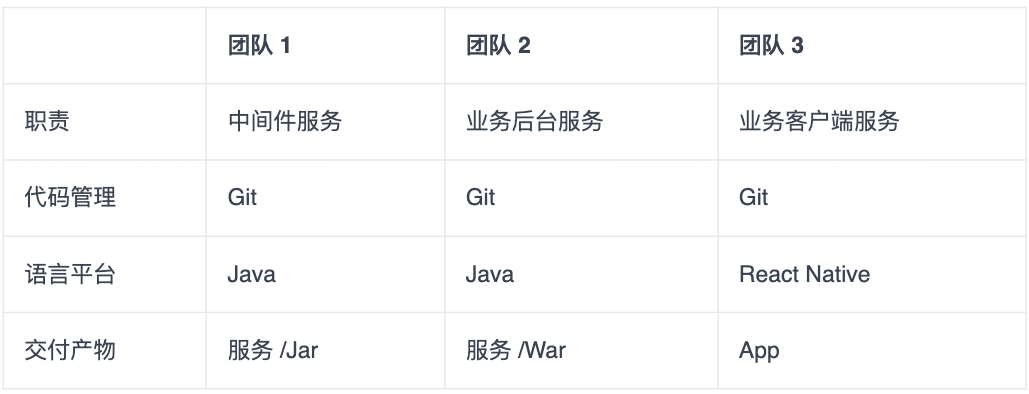
在这里,我们要模拟的这个系统,最终表现为移动 App 持续交付体系的形式,需要中间件、业务后台,以及业务客户端这 3 个团队交付产物的协作,才算是完整:
- 首先,用户通过团队 3 交付的移动 App 进行系统操作;
- 其次,移动 App 需要调用团队 2 提供的业务后台服务 War,获取数据和处理业务逻辑;
- 最后,后台服务 War 需要依赖团队 1 提供的业务中间件 Jar,完成底层操作,如配置读取、缓存处理等。
这三个团队的依赖关系和交付产物,也决定了他们要采用不同的交付方式:
- 团队 1,有两类交付方式:
- 第一类是,中间件服务的交付,使用传统的虚机部署,提供可部署的代码包;
- 第二类是,中间件组件的交付,使用 Jar 包发布,发布到组件仓库。
- 团队 2 的交付方式是,后台服务使用 Docker 交付,部署在 k8s 集群上。
- 团队 3 的交付方式是,标准的 iOS App 交付。
2.1.1 主体流水线的需求¶

整个过程可以大致描述为:代码合并到 master 后能够自动触发对应的集成编译,如编译通过则部署到对应的测试环境下,部署成功后驱动自动化测试,测试通过则分批部署到生产环境。
主体流水线发生的状态变更,都需要通过 E-mail 通知发起人。这里的发起人就是代码提交者和合并审核人。
2.1.2 代码与配置管理相关的需求¶
3 个模拟团队的代码分支策略均采用标准的 GitLab Flow 模型,要求是代码通过 code review 后才能合并入 master 分支;合并入 master 分支后,能够触发对应的集成编译。
同时,我们需要代码静态扫描服务,帮助我们更好地把控代码质量。这个服务的具体工作形式是:
这里需要注意的是,整个代码扫描过程是异步进行的,所以在没有得到扫描结果前,主体流水线将继续进行。
- 如果主体流水线已经执行完,而代码扫描还没结束,也就是还没有得到扫描结果的话,整条流水线需要停下来等待;
- 而如果在执行主体流水线的过程中,代码静态扫描的结果是不通过的话,那么就需要直接中断主体流水线的执行,此次交付宣告失败。
2.1.3 构建与集成相关的需求¶
- 首先,能够同时支持传统的部署包、Docker 镜像,以及移动 App 的编译和集成。
- 其次,所有构建产物及构建历史,都能被有效、永久地记录和存储。
- 再次,各构建产物有自己独立的版本体系,并与代码 commit ID 相关联。
- 最后,构建通道必须能够支持足够的并发量。
2.1.4 打包与发布相关的需求¶
整个发布体系,除了要考虑标准的 War 包和 Docke 镜像发布外,我们还要考虑 Jar 包组件的发布。因为团队 1 的 Jar 包对应有两类交付方式,所以对 Jar 包的发布,我们需要做一些特殊考虑:
- 测试环境可以使用 Snapshot 版本,但是生产环境则不允许;
- 即使测试通过,也不一定需要发布 Jar 包的每个版本到生产环境;
- Jar 包是发布到对应的组件仓库,发布形式与其他几类差别(比如,War 包、Docker 镜像等)较大。
2.1.5 自动化测试的需求¶
在这里,我们的自动化测试平台,选择的是 TestNG,这也是业界最为流行的自动化测试平台之一。
对于测试,系统需要注意的是,不要有一个测试任务失败就中断交付,最好是跑完所有测试任务,并收集结果。当然,我们可以通过 TestNG 平台,很容易做到这一点。
而模拟团队在持续交付主体流水线的需求下,对各个主要模块还有一些具体的需求:
- 代码与配置:需要 code review,以及静态代码扫描;
- 构建与集成:能同时支持 Jar、War、Docker,以及 App,版本管理可追溯,支持高并发;
- 打包与发布:同时支持 Jar、War、Docker、App 的发布,以及统一的部署标准;
- 自动化测试:通过 TestNG 驱动,实现全自动测试。
2.2 2快速构建持续交付系统(二):GitLab解决代码管理问题、¶
2.2.1 利用GitLab搭建代码管理平台¶
使用官方的 Docker 镜像或一键安装包 Omnibus 安装 GitLab。
接下来,我就以 Centos 7 虚拟机为例,描述一下整个 Omnibus GitLab 的安装过程,以及注意事项。
在安装前,你需要注意的是如果使用虚拟机进行安装测试,建议虚拟机的“最大内存”配置在 4 G 及以上,如果小于 2 G,GitLab 可能会无法正常启动。
2.2.2 安装GitLab¶
安装 SSH 等依赖,配置防火墙。
sudo yum install -y curl policycoreutils-python openssh-server
sudo systemctl enable sshd
sudo systemctl start sshd
sudo firewall-cmd --permanent --add-service=http
sudo systemctl reload firewalld
安装 Postfix 支持电子邮件的发送。
sudo yum install postfix
sudo systemctl enable postfix
sudo systemctl start postfix
从 rpm 源安装,并配置 GitLab 的访问域名,测试时可以将其配置为虚拟机的 IP(比如 192.168.0.101)。
curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ee/script.rpm.sh | sudo bash
sudo EXTERNAL_URL="http://192.168.0.101" yum install -y gitlab-ee
2.2.3 配置GitLab¶
安装完成之后,还要进行一些系统配置。对于 Omnibus GitLab 的配置,我们只需要重点关注两方面的内容:
- 使用命令行工具 gitlab-ctl,管理 Omnibus GitLab 的一些常用命令。 比如,你想排查 GitLab 的运行异常,可以执行 gitlab-ctl tail 查看日志。
- 配置文件
/etc/gitlab/gitlab.rb,包含所有 GitLab 的相关配置。邮件服务器、LDAP 账号验证,以及数据库缓存等配置,统一在这个配置文件中进行修改。 比如,你想要修改 GitLab 的外部域名时, 可以通过一条指令修改gitlab.rb文件:
external_url 'http://newhost.com'
然后,执行 gitlab-ctl reconfigure 重启配置 GitLab 即可。
关于 GitLab 更详细的配置,你可以参考官方文档。
2.2.4 GitLab的二次开发¶
对 GitLab 进行二次开发时,我们可以使用其官方开发环境 gdk( https://gitlab.com/gitlab-org/gitlab-development-kit)。
但,如果你是第一次进行 GitLab 二次开发的话,我还是建议你按照 https://docs.gitlab.com/ee/install/installation.html 进行一次基于源码的安装,这将有助于你更好地理解 GitLab 的整个架构。
为了后面更高效地解决二次开发的问题,我先和你介绍一下 GitLab 的几个主要模块:
- Unicorn,是一个 Web Server,用于支持 GitLab 的主体 Web 应用;
- Sidekiq,队列服务,需要 Redis 支持,用以支持 GitLab 的异步任务;
- GitLab Shell,Git SSH 的权限管理模块;
- Gitaly,Git RPC 服务,用于处理 GitLab 发出的 git 操作;
- GitLab Workhorse,基于 Go 语言,用于接替 Unicorn 处理比较大的 http 请求。
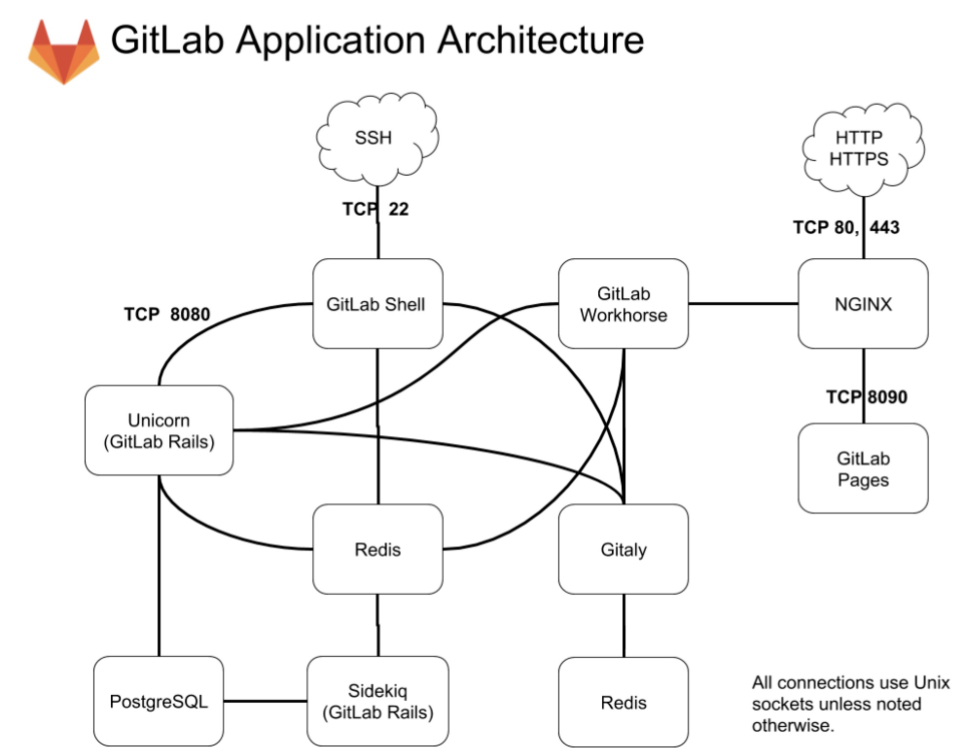
对 GitLab 应用层的修改,我们主要关注的是 GitLab Rails 和 GitLab Shell 这两个子系统。
2.2.5 二次开发的例子¶
二次开发,最常见的是对 GitLab 添加一个外部服务调用,这部分需要在 app/models/project_services 下面添加相关的代码。
我们可以参考 GitLab 对 Microsoft Teams 的支持方式:
在 app/models/project_services/microsoft_teams_service.rb 下,添加一些可配置内容及其属性,这样我们就可以在 GitLab 的 service 模块页面下看到相应的配置项了。
## frozen_string_literal: true
class MicrosoftTeamsService < ChatNotificationService
def title
'Microsoft Teams Notification'
end
def description
'Receive event notifications in Microsoft Teams'
end
def self.to_param
'microsoft_teams'
end
def help
'This service sends notifications about projects events to Microsoft Teams channels.<br />
To set up this service:
<ol>
<li><a href="https://msdn.microsoft.com/en-us/microsoft-teams/connectors">Getting started with 365 Office Connectors For Microsoft Teams</a>.</li>
<li>Paste the <strong>Webhook URL</strong> into the field below.</li>
<li>Select events below to enable notifications.</li>
</ol>'
end
def webhook_placeholder
'https://outlook.office.com/webhook/…'
end
def event_field(event)
end
def default_channel_placeholder
end
def default_fields
[
{ type: 'text', name: 'webhook', placeholder: "e.g. #{webhook_placeholder}" },
{ type: 'checkbox', name: 'notify_only_broken_pipelines' },
{ type: 'checkbox', name: 'notify_only_default_branch' }
]
end
private
def notify(message, opts)
MicrosoftTeams::Notifier.new(webhook).ping(
title: message.project_name,
summary: message.summary,
activity: message.activity,
attachments: message.attachments
)
end
def custom_data(data)
super(data).merge(markdown: true)
end
end
在 lib/microsoft_teams/notifier.rb 内实现服务的具体调用逻辑。
module MicrosoftTeams
class Notifier
def initialize(webhook)
@webhook = webhook
@header = { 'Content-type' => 'application/json' }
end
def ping(options = {})
result = false
begin
response = Gitlab::HTTP.post(
@webhook.to_str,
headers: @header,
allow_local_requests: true,
body: body(options)
)
result = true if response
rescue Gitlab::HTTP::Error, StandardError => error
Rails.logger.info("#{self.class.name}: Error while connecting to #{@webhook}: #{error.message}")
end
result
end
private
def body(options = {})
result = { 'sections' => [] }
result['title'] = options[:title]
result['summary'] = options[:summary]
result['sections'] << MicrosoftTeams::Activity.new(options[:activity]).prepare
attachments = options[:attachments]
unless attachments.blank?
result['sections'] << {
'title' => 'Details',
'facts' => [{ 'name' => 'Attachments', 'value' => attachments }]
}
end
result.to_json
end
end
end
以上就是一个最简单的 Service 二次开发的例子。熟悉了 Rails 和 GitLab 源码后,你完全可以以此类推写出更复杂的 Service。
2.2.6 GitLab的HA方案¶
对于研发人员数量小于 1000 的团队,我不建议你考虑 GitLab 服务多机水平扩展的方案。GitLab 官方给出了一个内存对应用户数量的参照,如下:
16 GB RAM supports up to 2000 users 128 GB RAM supports up to 16000 users
从这个配置参照数据中,我们可以看到一台高配的虚拟机或者容器可以支持 2000 名研发人员的操作,而单台物理机(128 GB 配置)足以供上万研发人员使用。
同时,实现 GitLab 的完整水平扩展方案,也并不是一件易事。
GitLab 提供的功能
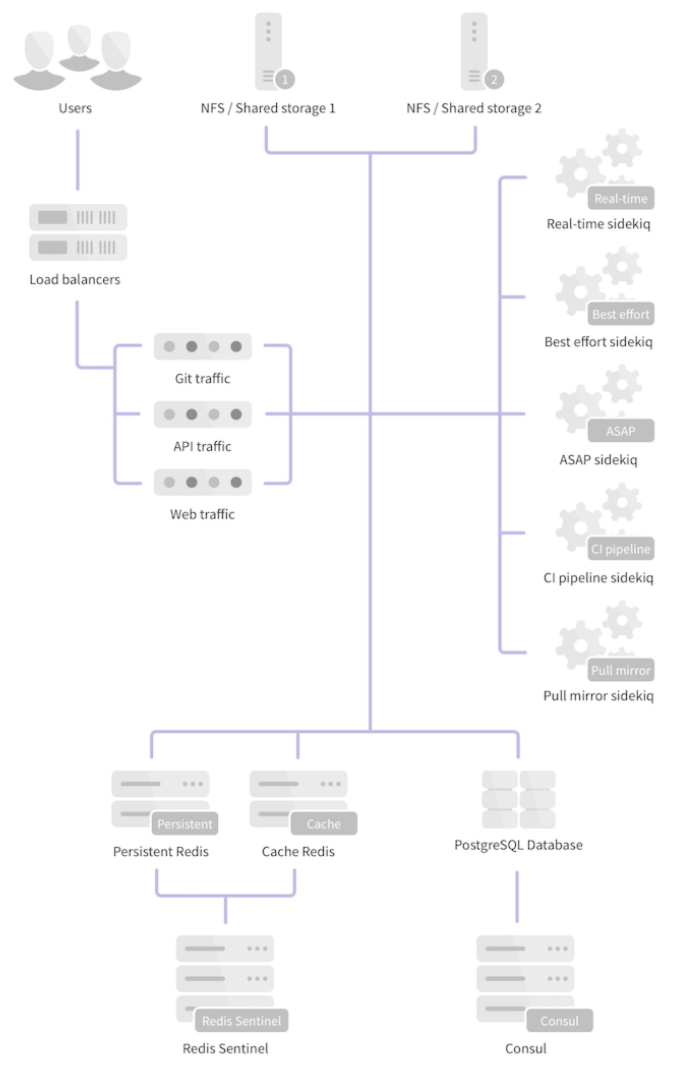
从整体架构上看,PostgreSQL、Redis 这两个模块的高可用,都有通用的解决方案。而 GitLab 在架构上最大的问题是,需要通过文件系统在本地访问仓库文件。于是,水平扩展时,如何把本地的仓库文件当做数据资源在服务器之间进行读写就变成了一个难题。
官方推荐的方案是通过 NFS 进行多机 Git 仓库共享。但这个方案在实际使用中并不可行,git 本身是 IO 密集型应用,对于真正在性能上有水平扩展诉求的用户来说,NFS 的性能很快就会成为整个系统的瓶颈。我早期在美团点评搭建持续交付体系时,曾尝试过这个方案,当达到几百个仓库的规模时,NFS 就撑不住了。
2.2.7 如何应对代码管理的需求¶
Integrations 包括两部分
- ab service,是在 GitLab 内部实现的,与一些缺陷管理、团队协作等工具的集成服务。
-
Webhook,支持在 GitLab 触发代码 push、Merge Request 等事件时进行 http 消息推送。
-
第一步,创建对应的代码仓库
-
第二步,配置 Sonar 静态检查
- 第三步,解决其他设置
- 经过创建对应的代码仓库、配置 Sonar 静态检查这两步,再配合使用 GitLab 提供的 Merge Request、Issues、CI/CD 和 Integration 功能,代码管理平台基本上就算顺利搭建完毕了。
2.3 快速构建持续交付系统(三):Jenkins解决集成打包问题¶
2.3.1 Jenkins的安装与配置¶
第一步,安装 Jenkins
为了整个持续交付体系的各个子系统之间的环境的一致性,我在这里依然以 Centos 7 虚拟机为例,和你分享 Jenkins 2.138(最新版)的安装过程。假设,Jenkins 主机的 IP 地址是 10.1.77.79。
- 安装 Java 环境
yum install java-1.8.0-openjdk-devel
- 更新 rpm 源,并安装 Jenkins 2.138
rpm --import https://pkg.jenkins.io/redhat-stable/jenkins.io.key
wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat-stable/jenkins.repo
yum install jenkins
第二步,配置 Jenkins 对 GitLab 的访问权限
Jenkins 安装完成之后,我们还需要初始化安装 Jenkins 的一些基础配置,同时配置 Jenkins 对 GitLab 的访问权限。
在新版的 Jenkins 中,第一次启动时会有一个初始化向导,引导你设置用户名、密码,并安装一些插件。
在这里,我推荐你勾选“安装默认插件”,用这种方式安装 Pipline、 LDAP 等插件。如果这个时候没能选择安装对应的插件,你也可以在安装完成后,在系统管理 -> 插件管理页面中安装需要的插件。
那么如何才能使编译和 GitLab、SonarQube 整合在一起呢?这里,我以一个后台 Java 项目为例,对 Jenkins 做进一步的配置,以完成 Jenkins 和 GitLab、SonarQube 的整合。这些配置内容,主要包括:
- 配置 Maven;
- 配置 Jenkins 钥匙;
- 配置 GitLab 公钥;
- 配置 Jenkins GitLab 插件。
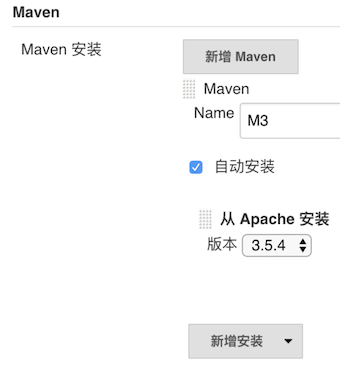
配置 Maven
进入系统管理 -> 全局工具配置页面,安装 Maven,并把名字设置为 M3。
这样配置好 Maven 后,Jenkins 就会在第一次使用 GitLab 时,自动安装 Maven 了。
配置 Jenkins 钥匙
配置 Jenkins 钥匙的路径是:凭据 -> 系统 -> 全局凭据 -> 添加凭据。
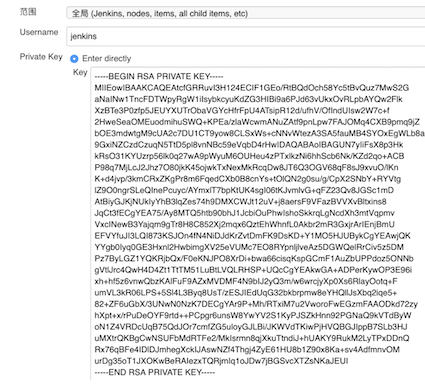
然后,将你的私钥贴入并保存
配置 GitLab 公钥
在 GitLab 端, 进入 http://{Gitlab Domain}/profile/keys,贴入你的公钥并保存
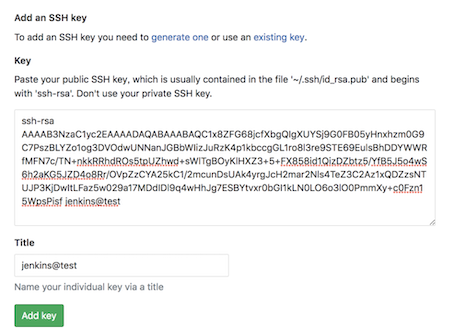
通过配置 Jenkins 钥匙,以及配置 GitLab 公钥两步,你就已经完成了 Jenkins 对 GitLab 仓库的访问权限配置。
配置 Jenkins GitLab 插件
Jenkins 的 GitLab-plugin 插件的作用是,在代码提交和 Merge Request 时触发编译。安装这个插件的方法是:进入 Jenkins 的系统管理 -> 插件管理页面,选择 GitLab Plugin 安装。
Jenkins 重启后,选择凭据 -> 系统 -> 全局凭据 -> 添加凭据,再选择 GitLab API Token。然后,将 http://10.1.77.79/profile/personal_access_tokens 中新生成的 access token 贴入 GitLab API Token,并保存。
2.3.2 使用Jenkins Pipeline构建工作流¶
接下来,我就和你分享一下如何编写 Jenkins Pipeline,以及从代码编译到静态检查的完整过程。这个从代码编译到静态检查的整个过程,主要包括三大步骤:
- 第一步,创建 Jenkins Pipeline 任务;
- 第二步,配置 Merge Request 的 Pipeline 验证;
- 第三部,编写具体的 Jenkins Pipeline 脚本。
首先,在 Jenkins 中创建一个流水线任务,并配置任务触发器
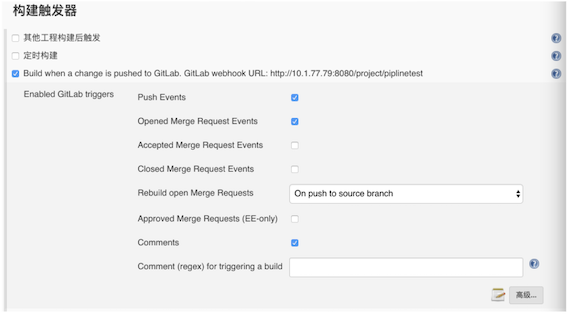
然后,在 GitLab 端配置 Webhook。配置方法为:在 GitLab 项目下的 settings->Integrations 下配置并勾选 “Merge request events”选项。
经过这些配置后, 每次有新的 Merge Request 被创建或更新,都会触发 Jenkins 的 Pipeline,而再由自定义的 Pipeline 脚本完成具体任务,比如代码扫描任务。
- 配置 Merge Request 的 Pipeline 验证
在驱动代码静态扫描之后,我们还要做一些工作,以保证扫描结果可以控制 Merge Request 的行为。
进入 settings->Merge Request 页面, 勾选“Only allow Merge Requests to be merged if the pipeline succeeds”。这个配置可以保证,在静态检查任务中,不能合并 Merge Request。
- 编写具体的 Pipeline 脚本
然后我们再一起看一下为了实现我们之前的需求,即获取代码 - 编译打包 - 执行 Sonar 静态代码检查和单元测试等过程。
Jenkins 端的 Pipeline 脚本如下,同时我们需要将该脚本配置在 Jenkins 中
node {
def mvnHome
# 修改 Merge Request 的状态,并 checkout 代码
stage('Preparation') { // for display purposes
mvnHome = tool 'M3'
updateGitlabCommitStatus name: 'build', state: 'running'
checkout scm
}
# 执行 Maven 命令对项目编译和打包
stage('Build') {
echo 'Build Start'
// Run the maven build
sh "'${mvnHome}/bin/mvn' -Dmaven.test.skip=true clean package"
}
# 启动 sonar 检查,允许 junit 单元测试,获取编译产物,并更新 Merge request 的状态
stage('Results') {
// Run sonar
sh “'${mvnHome}/bin/mvn' org.sonarsource.scanner.maven:sonar-maven-plugin:3.2:sonar”
junit '**/target/surefire-reports/TEST-*.xml'
archive 'target/*.war'
updateGitlabCommitStatus name: 'build', state: 'success'
}
}
- 第一个 stage:
从 GitLab 中获取当前 Merge Request 源分支的代码;同时,通 Jenkins GitLab 插件将 Merge Request 所在的分支的当前 commit 状态置为 running。
这个时候,我们可以在 GitLab 的页面上看到 Merge Request 的合并选项已经被限制了,
- 第二个 stage:
比较好理解,就是执行 Maven 命令对项目编译和打包。
- 第三个 stage:
通过 Maven 调用 Sonar 的静态代码扫描,并在结束后更新 Merge Request 的 commit 状态,使得 Merge Request 允许被合并。同时将单元测试结果展现在 GitLab 上。
比如,我们在 Sonar 检测之后,可以调用 Sonar 的 API 获取静态检查的详细信息;然后,调用 GitLab 的 API,将静态检查结果通过 comment 的方式,展现在 GitLab 的 Merge Request 页面上,从而使整个持续集成的流程更加丰满和完整。
2.4 快速构建持续交付系统(四):Ansible解决自动部署问题¶
2.4.1 利用Ansible完成部署¶
与其他三大主流的配置管理工具 Chef、Puppet、Salt 相比,Ansible 最大的特点在于“agentless”,即无需在目标机器装安装 agent 进程,即可通过 SSH 或者 PowerShell 对一个环境中的集群进行中心化的管理。
Ansible 安装
sudo pip install Ansible
提交一个 Ansible 的 Inventory 文件 hosts,该文件代表要管理的目标对象:
$ cat hosts
[Jenkinsservers]
10.1.77.79
打通本机和测试机的 SSH 访问:
$ ssh-copy-id deployer@localhost
尝试远程访问主机 10.1.77.79
$ Ansible -i hosts all -u deployer -a "cat /etc/hosts”
10.1.77.79 | SUCCESS | rc=0 >>
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
如果返回 SUCCESS,则表示我们已经可以通过 Ansible 管理该主机了。
2.4.2 Ansible使用¶
1. Inventory
对于被 Ansible 管理的机器清单,我们可以通过 Inventory 文件,分组管理其中一些集群的机器列表分组,并为其设置不同变量。
比如,我们可以通过 Ansible_user ,指定不同机器的 Ansible 用户。
[Jenkinsservers]
10.1.77.79 Ansible_user=root
10.1.77.80 Ansible_user=deployer
[Gitlabservers]
10.1.77.77
PlayBook
PlayBook 是 Ansible 的脚本文件,使用 YAML 语言编写,包含需要远程执行的核心命令、定义任务具体内容,等等。
---
- hosts: webservers
remote_user: root
tasks:
- name: ensure apache is at the latest version
yum:
name: httpd
state: latest
- name: write the apache config file
template:
src: /srv/httpd.j2
dest: /etc/httpd.conf
- hosts: databases
remote_user: root
tasks:
- name: ensure postgresql is at the latest version
yum:
name: postgresql
state: latest
- name: ensure that postgresql is started
service:
name: postgresql
state: started
这段代码的最主要功能是,使用 yum 完成了 Apache 服务器和 PostgreSQL 的安装。
其中,包含了编写 Ansible PlayBook 的三个常用模块。
- yum 调用目标机器上的包管理工具完成软件安装 。Ansible 对于不同的 Linux 操作系统包管理进行了封装,在 CentOS 上相当于 yum, 在 Ubuntu 上相当于 APT。
- Template 远程文件渲染,可以把本地机器的文件模板渲染后放到远程主机上。
- Service 服务管理,同样封装了不同 Linux 操作系统实际执行的 Service 命令。
通常情况下,我们用脚本的方式使用 Ansible,只要使用好 Inventory 和 PlayBook 这两个组件就可以了,即:使用 PlayBook 编写 Ansible 脚本,然后用 Inventory 维护好需要管理的机器列表。这样,就能解决 90% 以上使用 Ansible 的需求。
使用 Ansible 进行 Java 应用部署
---
- hosts: Tomcat_server
roles:
- { role: Ansible-Tomcat }
然后,部署具体的业务代码。
完成这个需求,我们只需要通过 Ansible 的 SCP 模块把 War 包从 Jenkins 推送到目标机器上即可。
- name: Copy a war file to the remote machine
copy:
src: /tmp/waimai-service.war
dest: /opt/Tomcat/webapps/waimai-service.war
所以,此时更好的做法是直接在部署本地从仓库下载 War 包。
最后,重启 Tomcat 服务,整个应用的部署过程就完成了。
三、L9持续交付理论总结及面试¶
3.1 持续交付理论总结及面试¶
3.2 量身定制你的持续交付体系¶
虽然持续交付着重打造的是发布流水线的部分,但它所要达到的目标是在“最终用户”和“研发团队”之间建立紧密的反馈环:通过持续交付新的软件版本,以验证新想法和软件改动的正确性,并衡量这些改动对软件价值的影响。
3.3 配置管理¶
代码分支策略的选择
- 主干开发(TBD)
- GitHub Flow 是 GitHub 所使用的一种简单流程。该流程只使用 master 和特性分支,并借助 GitHub 的 pull request 功能。
3.3.1 依赖管理¶
Maven 使用 XML 格式的文件进行依赖配置描述的方式,叫作 POM(Project Object Model ),以下就是一段简单的 pom.xml 文件片段
在 POM 中,根元素 project 下的 dependencies 可以包含一个或多个 dependency 元素,以声明一个或者多个项目依赖。每个依赖可以包含的元素有:
groupId、artifactId、version: 依赖的基本坐标; / type: 依赖的类型,默认为 jar;/ scope: 依赖的范围;/ optional: 标记依赖是否可选; / exclusions: 用来排除传递性依赖;
3.3.2 代码回滚¶
- 第一种情况:开发人员独立使用的分支上,如果最近产生的 commit 都没有价值,应该废弃掉,此时就需要把代码回滚到以前的版本。
- 第二种情况:代码集成到团队的集成分支且尚未发布,但在后续测试中发现这部分代码有问题,且一时半会儿解决不掉,为了不把问题传递给下次的集成,此时就需要把有问题的代码从集成分支中回滚掉
- 第三种情况:代码已经发布到线上,线上包回滚后发现是新上线的代码引起的问题,且需要一段时间修复,此时又有其他功能需要上线,那么主干分支必须把代码回滚到产品包 V0529 对应的 commit。
代码回滚必须遵循的原则
- 集成分支上的代码回滚坚决不用
reset --hard的方式,
三种典型回滚场景及回滚策略
- 个人分支回滚
- 集成分支上线前回滚 revert before merge request
- 集成分支上线后回滚
$ git fetch origin
$ git checkout master
$ git reset --hard V0529 # 把本地的 master 分支的指针回退到 V0529,此时暂存区 (index) 里就指向 V0529 里的内容了。
$ git reset --soft origin/master # --soft 使得本地的 master 分支的指针重新回到 V05javascript:;30,而暂存区 (index) 变成 V0529 的内容。
$ git commit -m "rollback to V0529" # 把暂存区里的内容提交,这样一来新生成的 commit 的内容和 V0529 相同。
$ git push origin master # 远端的 master 也被回滚。
3.4 环境管理¶
发环境,功能测试环境,验收测试环境,预发布环境,生产环境这五个大套环境。
了解各种配置方法
- 构建时配置
以 Maven 为例,实现多环境的构建可移植性需要使用 profile。
profile 是一组可选的配置,可以用来设置或者覆盖配置默认值。通过不同的环境激活不同的 profile,可以实现构建的可移植性。
maven initialize –Pdev & maven initialize –Pprod
- 打包时配置
- 运行时配置
3.5 构建集成¶
3.5.1 构建的提速¶
- 级硬件资源
- 搭建私有仓库
- 使用本地缓存
- 规范构建流程
- 以 Java 构建为例,Enforcer 检查、框架依赖检查、Sonar 检查、单元测试、集成测试这些步骤,并没有放在同一个构建过程中同步执行,而是通过异步的方式穿插在 CI/CD 当中,甚至可以在构建过程之外执行。
- 善用构建工具
- 以 Maven 为例
- 设置合适的堆内存参数
- 使用
-Dmaven.test.skip = true跳过单元测试。 - 在发布阶段,不使用 Snapshot 版本的依赖
- 使用
-T 2C命令进行并行构建 - 局部 / 正确使用 clean 参数
- 以 Maven 为例
3.5.2 构建检测¶
- Maven Enforcer 插件提供了非常多的通用检查规则,比如检查 JDK 版本、检查 Maven 版本、检查依赖版本,等等
3.6 发布及监控¶
3.6.1 发布¶
因此,我们想要的应该是:一个易用、快速、稳定、容错力强,必要时有能力迅速回滚的发布系统。
- 扩展到集群
灰度发布是指,渐进式地更新每台机器运行的版本,一段时期内集群内运行着多个不同的版本,同一个 API 在不同机器上返回的结果很可能不同
- 蓝绿发布: 是先增加一套新的集群,发布新版本到这批新机器,并进行验证,新版本服务器并不接入外部流量
- 滚动发布: 是不添加新机器,从同样的集群服务器中挑选一批,停止上面的服务,并更新为新版本,进行验证,验证完毕后接入流量。
- 重复此步骤,一批一批地更新集群内的所有机器,直到遍历完所有机器\
- 金丝雀发布: 从集群中挑选特定服务器或一小批符合要求的特征用户,对其进行版本更新及验证,随后逐步更新剩余服务器。
3.6.2 发布系统的用户体验¶
1 张页面展示发布信息: 发布中 / 未发布时
6 大页面主要内容
集群 / 实例 / 发布日志 / 发布历史 / 发布批次 / 发布操作。
3.6.3 发布系统的核心架构和功能设计¶
发布系统的核心模型主要包括 Group、DeploymentConfig、Deployment、DeploymentBatch,和 DeploymentTarget 这 5 项。
- Group 的属性非常重要,包括 Site 站点、Path 虚拟路径、docBase 物理路径、Port 应用端口、HealthCheckUrl 健康检测地址等,这些属性都与部署逻辑息息相关。
- DeploymentConfig,即发布配置,提供给用户的可修改配置项要通俗易懂
- Deployment,即一个发布实体,主要包括 Group 集群、DeploymentConfig 发布配置、Package 发布包、发布时间、批次、状态等等信息。
- DeploymentBatch,即发布批次
3.6.4 如何利用监控保障发布质量¶
- 用户侧监控,关注的是用户真正感受到的访问速度和结果;
- 端到端的监控 / 唯一用户 ID 的监控
- 网络监控,即 CDN 与核心网络的监控;
- 公网监控 / 内网监控
- 业务监控,关注的是核心业务指标的波动;
- 应用监控,即服务调用链的监控;
- 调用链监控系统,一般采用在框架层面统一定义的方式,以做到数据采集对业务开发透明,但同时也需要允许开发人员自定义埋点监控某些代码片段。
- 系统监控,即基础设施、虚拟机及操作系统的监控。
- 系统监控,指的是对基础设施的监控。我们通常会收集 CPU、内存、I/O、磁盘、网络连接等作为监控指标
3.7 测试管理¶
3.7.1 代码静态检查实践¶
代码静态检查; / 破坏性测试; / Mock 与回放
- SonarQube 采用的是 B/S 架构,通过插件形式,可以支持对 Java、C、C++、JavaScript 等二十几种编程语言的代码质量管理与检测。
如何提高静态检查的效率?
- 其一,能够缩短代码扫描所消耗的时间,从而提升整个持续交付过程的效率;
- 其二,我们通常会采用异步的方式进行静态检查,如果这个过程耗时特别长的话,会让用户产生困惑,从而质疑执行静态检查的必要性。
3.7.2 破坏性测试¶
- 第一,破坏性测试的手段和过程,并不是无的放矢,它们是被严格设计和执行的
- 第二,破坏性测试,会产生切实的破坏作用,你需要权衡破坏的量和度
因此,绝大部分破坏性测试都会在单元测试、功能测试阶段执行。而执行测试的环境也往往是局部的测试子环境。
混沌工程: chaos monkey
3.7.3 Mock与回放技术助力自动化回归¶
Mock 因为这样的模拟能力,为测试和持续交付带来的价值,可以总结为以下三点:
使测试用例更独立、更解耦 / 提升测试用例的执行速度 / 提高测试用例准备的效率
- 基于对象和类的 Mock: Mockito 或者 EasyMock 这两个框架的实现原理
- 基于微服务的 Mock: Weir Mock 和 Mock Server。这两个框架,都可以很好地模拟 API、http 形式的对象。
3.8 持续交付平台化¶
- 代码管理模块,往往会和代码审核、静态扫描和分支管理等模块相联系;
- 集成编译模块,也会与依赖管理、单元测试、加密打包等模块相生相随的;
- 环境管理模块,离不开配置管理、路由管理等模块;
- 发布部署模块,还需要监控模块和流控模块的支持。