

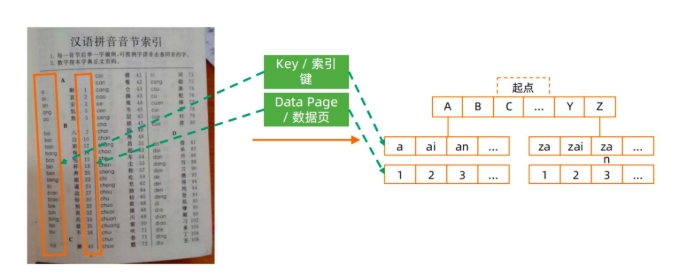
一、Index/Key/DataPage——索引 /键 /数据⻚?¶
二、Covered Query¶

三、IXSCAN/COLLSCAN¶

四、Selectivity——过滤性¶
在一个有 10000条记录的集合中(以下条件都是独立检索):
- 满足 gender= F 的记录有 4000 条
- 满足 city=BJ 的记录有 100 条
- 满足 lastname='Zhao' 的记录有 10 条
查询条件:
条件 lastname能过滤最多的数据, city其次, gender最弱。所以 : lastname过滤性( selectivity) > city > gender
五、索引结构¶
1、B-树和 B+树的区别
B树的两个明显特点 :
- 树内的每个节点都存储数据
- 叶子节点之间无指针相邻
B+树的两个明显特点
- 数据只出现在叶子节点
- 所有叶子节点增加了一个链指针
因此,在关系型数据中,遍历操作比较常见,因此采用 B+树作为索引,比较合适。而在非关系型数据库中,单
一查询比较常见,因此采用 B树作为索引,比较合适。 https://source.wiredtiger.com/10.0.0/tune_page_size_and_comp.html

重点是圈住的这句话
WiredTiger maintains a table's data in memory using a data structure called a B- Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
WiredTiger 使用称为 B-Tree(具体为 B+ 树)的数据结构在内存中维护表的数据,将 B-Tree 的节点 称为⻚。树内部⻚面只携带索引。叶子节点⻚存储索引和值。
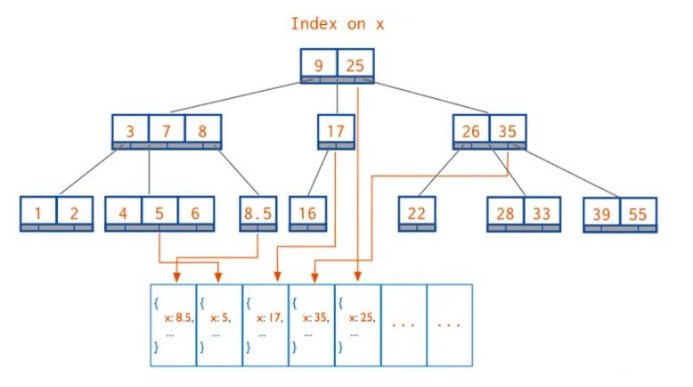
由于 B树 /B+树的工作过程过于复杂,但本质上它是一个有序的数据结构。我们用数组来理解它。假设索引为 {a: 1}( a 升序)
- 数据增加 /删除时始终保持索引字段有序
- 数组插入效率低,但是 B数可以高效实现
- 在有序结构上实施二分查找,可实现 O(log2(n))的高效搜索

六、索引类型¶
6.1 单列索引¶
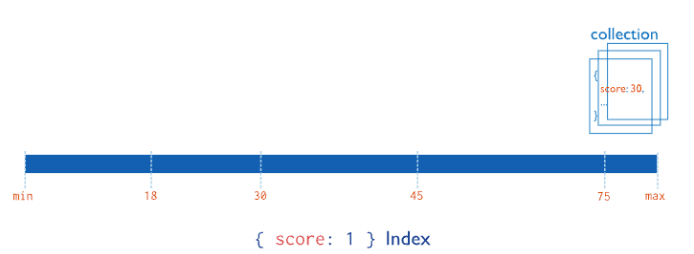 由于 B树/B+树的工作过程过于复杂,但本质上它是一个有序的数据结构。我们用数组来理解它。假设索引为{a: 1}(a 升序)
由于 B树/B+树的工作过程过于复杂,但本质上它是一个有序的数据结构。我们用数组来理解它。假设索引为{a: 1}(a 升序)
- 数据增加/删除时始终保持索引字段有序
- 数组插入效率低,但是B数可以高效实现
- 在有序结构上实施二分查找,可实现O(log2(n))的高效搜索
一个名为 records的集合,其中包含类似于以下样本文档的文档:
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}
1、在单个字段上创建升序索引
db.records.createIndex( { score: 1 } )
为 records的集合的 score字段创建一个升序索引
可支持如下查询:
db.records.find( { score: 2 } )
db.records.find( { score: { $gt: 10 } } )
2、在嵌入式字段上创建索引
在 location.state字段上创建索引
db.records.createIndex( { "location.state": 1 } )
创建的索引将支持在字段 location.state上的查询,例如
db.records.find( { "location.state": "CA" } )
db.records.find( { "location.city": "Albany", "location.state": "NY" } )
3、在嵌入式文档上创建索引
以下命令将在整个位置字段上创建一个索引:
db.records.createIndex({location:1})
下面的查询可以使用 location字段上的索引:
db.records.find( { location: { city: "New York", state: "NY" } } )
6.2 复合索引¶

考虑一个名为 products的集合,它包含类似于以下文档的文档:
{
"_id": ObjectId(...),
"item": "Banana",
"category": ["food", "produce", "grocery"],
"location": "4th Street Store",
"stock": 4,
"type": "cases"
}
1、组合索引的最佳方式:ESR原则
//简单来说就是索引的字段顺序应该是:等值查询字段在最前面,然后是排序字段,最后是范围查询字段。 这是一个超级有用的小原则。
- 精确(Equal)匹配的字段放最前面
- 排序(Sort)条件放中间
- 范围(Range)匹配的字段放最后面
请看一下查询条件:
db.members.find({ gender: “F”, age: {$gte: 18}}).sort(“join_date:1”)
{ gender: 1, age: 1, join_date: 1 }
{ gender: 1, join_date:1, age: 1 }
{ join_date: 1, gender: 1, age: 1 }
{ join_date: 1, age: 1, gender: 1 }
{ age: 1, join_date: 1, gender: 1}
{ age: 1, gender: 1, join_date: 1}
这么多候选的,用哪一个?
2、创建复合索引
db.collection.createIndex( { <field1>: <type>, <field2>: <type2>, ... } )
//在索引规范中,该字段的值描述了字段的索引类型。例如,值1指定一个索引,该索引按升序对记录条目进行排序。值-1指定一个索引,该索引按降序对记录条目进行排序。
//索引字段的顺序对给定查询的特定索引的有效性有很大影响。对于大多数复合索引,遵循ESR(相等、排序、范围)规则, ESR规则有助于创建高效的索引。
注意:不能创建具有哈希索引类型的复合索引。如果尝试创建包含哈希索引字段的复合索引,则会收到错误消息。
db.products.createIndex( { "item": 1, "stock": 1 } )
在 item 和 stock字段上创建一个升序索引
//复合索引中的字段顺序很重要。索引将包含对文档的引用,这些文档首先按item字段的值排序,然后在item字段的每个值内,按stock字段的值排序。 除了支持在所有索引字段上都匹配的查询之外,复合索引还可以支持在索引字段的前缀(索引起始子集)上匹配的查询。也就是说,
索引支持对 item字段以及 item字段和 stock字段的查询:
db.products.find( { item: "Banana" } )
db.products.find( { item: "Banana", stock: { $gt: 5 } } )
3、复合索引的排序
查询结果首先是按 username进行升序排序,然后按 date值降序排序,例如:
db.events.find().sort( { username: 1, date: -1 } )
查询返回结果首先按 username值降序,然后按 date值升序排序,例如:
db.events.find().sort( { username: -1, date: 1 } )
以下索引可以支持这两种排序操作:
db.events.createIndex( { "username" : 1, "date" : -1 } )
//但是,以上索引不能支持按username值升序,然后按date值升序排序,例如:
db.events.find().sort( { username: 1, date: 1 } )
db.events.find().sort( { username: -1, date: -1 } )
总结:
- 单列索引正反向排序都不受影响
- 复合索引则是乘以(-1)的排序可以用相同的索引,
- 1,1 和 -1,-1可以使用索引
- -1,1 和 1,-1 可以使用相同的索引
4、最左前缀原则
{ "item": 1, "location": 1, "stock": 1 }
索引具有以下索引前缀:
- { item: 1 }
- { item: 1, location: 1 }
- 对于复合索引,MongoDB可以使用索引来支持对索引前缀的查询。这样,MongoDB可以将索引用于以下字段的查询:
- item 字段,
- item 和 location 字段,
- item 和 location和 stock 字段。
- MongoDB无法使用复合索引来支持包含以下字段的查询,因为如果没有 item字段,则列出的任何字段都不对应于前缀索引:
- location 字段,
- stock 字段,或
- location 和 stock 字段。
6.3 多键索引¶
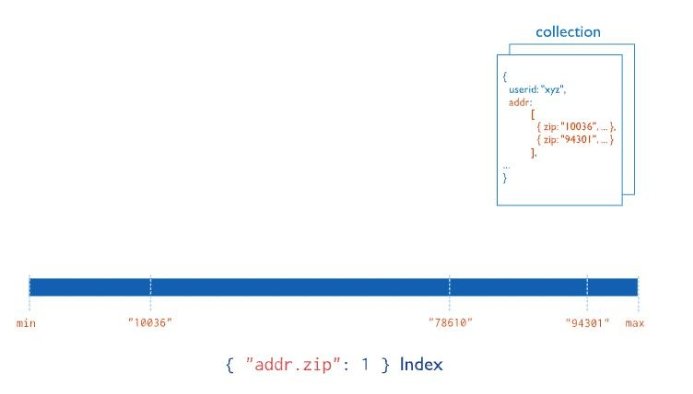
1、定义:
- 基于一个数组创建索引, MongoDB会自动创建为多键索引,无需刻意指定
- 多键索引也可以基于内嵌文档来创建
- 多键索引的边界值的计算依赖于特定的规则
- 多键索引不等于在文档上的多列创建索引 (复合索引 )
2、创建语法
db.coll.createIndex( { <field>: < 1 or -1 > } )
3、复合多键索引
- 对于一个复合多键索引,每个索引最多可以包含一个数组。
- 在多于一个数组的情形下来创建复合多键索引不被支持。
例如:
集合:
{ _id: 1, a: [ 1, 2 ], b: [ 1, 2 ], category: "AB - both arrays" }
不能创建一个基于 { a: 1, b: 1 } 的多键索引,因为 a和 b都是数组
集合:
{ _id: 1, a: [1, 2], b: 1, category: "A array" }
{ _id: 2, a: 1, b: [1, 2], category: "B array" }
则可以基于每一个文档创建一个基于 { a: 1, b: 1 }的复合多键索引,原因是每一个索引的索引字段只有一个数组
4、限制
- 不能够指定一个多键索引为分片片键索引
- 哈希索引不能够成为多键索引
- 多键索引不支持覆盖查询
6.4 文本索引¶
一个集合最多有一个文本索引
对 reviews集合 comments字段创建一个文本索引
db.reviews.createIndex( { comments: "text" } )
在字段 subject和 comments上创建一个文本索引
db.reviews.createIndex(
{
subject: "text",
comments: "text"
}
)
6.5 地理空间索引¶
//在我们存储地理数据和编写查询条件前,首先,必须选择表面类型,这将被用在计算中。您所选择的类型将 会影响您的数据如何被存储,建立的索引的类型,以及您的查询的语法形式。 MongoDB提供了两种表面类型:
- 2dsphere 索引
- 2d 索引
创建 2dsphere 索引
db.collection.createIndex( { <location field> : "2dsphere" } )
创建 2d 索引
db.collection.createIndex( { <location field> : "2d" } ,
{ min : <lower bound> , max : <upper bound> } )
6.6 hash索引¶
1、创建哈希索引
db.collection.createIndex( { _id: "hashed" } )
2、注意事项
- MongoDB支持任何单个字段的哈希索引
- 不支持多键(即数组)索引
- 不能创建具有哈希索引字段的复合索引
- 不能在哈希索引上指定唯一约束
- 可以在同一字段上创建哈希索引和升序 /降序(即非哈希)索引
七、索引属性¶
7.1 TTL索引¶
1、创建 TTL索引
在 eventlog集合的 lastModifiedDate字段上创建 TTL索引, TTL值为 3600秒
db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
2、数据过期
- 到期阈值是索引字段值加上指定的秒数。
- 如果字段是数组,并且索引中有多个日期值,则 MongoDB使用数组中最低(即最早)的日期值来计算到期阈 值。
- 如果文档中的索引字段不是日期或包含日期值的数组,则该文档不会过期。
- 如果文档没有索引字段,则该文档不会过期
db.runCommand({
collMod: "eventlog",
index: {
keyPattern: { lastModifiedDate: 1 },
expireAfterSeconds: 3600
}
})
3、删除操作
- mongod中的后台线程读取索引中的值,并从集合中删除过期的文档。
- 删除过期文档的后台任务每 60秒运行一次。
- 在副本集成员上,仅当成员处于 primary状态时, TTL后台线程才会删除过期文档。
- 在副本集成员上,当成员处于 secondary状态时, TTL背景线程处于空闲状态。
- TTL索引对查询的支持,与非 TTL索引一样。
4、限制:
- TTL索引是单字段索引。复合索引不支持 TTL,并且会忽略 expireAfterSeconds选项。
- _id字段不支持 TTL索引。
- 不能在固定集合( capped collection)上创建 TTL索引,因为 MongoDB无法从固定集合中删除文档。
- 不能使用 createIndex()更改现有索引的 expireAfterSeconds的值。可以使用 collMod修改
- 如果某个字段已经存在非 TTL单字段索引,则无法在同一字段上创建 TTL索引
7.2 唯一索引¶
1、创建唯一索引
(1)单字段的唯一索引
db.members.createIndex( { "user_id": 1 }, { unique: true } )
(2)唯一复合索引
db.members.createIndex( { groupNumber: 1, lastname: 1, firstname: 1 }, { unique: true } )
集合 { _id: 1, a: [ { loc: "A", qty: 5 }, { qty: 10 } ] },在 a.loc和 a.qty上创建唯一 的复合多键索引:
db.collection.createIndex( { "a.loc": 1, "a.qty": 1 }, { unique: true } )
db.collection.insert( { _id: 2, a: [ { loc: "A" }, { qty: 5 } ] } )
db.collection.insert( { _id: 3, a: [ { loc: "A", qty: 10 } ] } )
唯一索引允许将以下文档插入到集合中,因为该索引对于 a.loc和 a.qty值的组合具有唯一性:
2、限制
- 若集合包含违反索引唯一约束的数据,则无法在指定的索引字段上创建唯一索引。
- 不能在哈希索引上指定唯一约束。
-
文档在唯一索引中没有索引字段的值,则索引将为此文档存储一个空值且只允许一个缺少索引字段的文档。 //如果存在多个没有索引字段值的文档,或者缺少索引字段,则索引构建将失败,并给出重复键错误。也就是说:如果集合尚不包含缺少字段 x的文档,则唯一索引允许插入不包含字段 x的文档;如果集合中已经包含缺少字段 x的文档,则再次插入没有字段 x的文档时,则出现唯一索引错误。
-
对于要分片的集合,如果该集合具有其他唯一索引,则无法分片该集合。
- 对于已分片的集合,不能在其他字段上创建唯一索引。
7.3 隐藏索引¶
1、定义:
- 隐藏索引对查询规划器不可见,不能用于支持查询。
- 通过对规划器隐藏索引,用户可以在不实际删除索引的情况下评估删除索引的潜在影响。如果影响是负面 的,用户可以取消隐藏索引,而不必重新创建已删除的索引。 4.4新版功能。
2、创建隐藏索引
db.collection.createIndex({fileName:1},{hidden:true});
eg:borough字段上创建一个隐藏的升序索引
db.addresses.createIndex(
{ borough: 1 },
{ hidden: true }
);
3、隐藏现有索引
db.collection.hideIndex({fileName:1});
或者
db.collection.hideIndex("索引名称")
4、取消隐藏索引
db.collection.unhideIndex({fileName:1});
或者
db.collection.unhideIndex("索引名称");
7.4 Sparse 索引¶
1、创建稀疏索引
db.addresses.createIndex( { "xmpp_id": 1 }, { sparse: true } )
2、行为说明
- 如果 sparse索引会导致查询和排序操作的结果集不完整, MongoDB将不会使用该索引,除非 hint()明确指 定该索引。 //例如,查询 {x: {$exists: false}}不会在 x字段上使用 sparse索引,除非有明确提示。
- 如果在执行集合中所有文档的 count()时包含 sparse索引 count(),则即使 sparse索引导致计数不正确,也会使用 sparse索引。
7.5 部分索引¶
1、创建部分索引
//请使用 db.collection.createIndex () 方法,使用 partialFilterExpression选项。例如,下 面的操作创建一个复合索引,该索引只针对 rating字段大于 5的文档创建。
db.restaurants.createIndex(
{ cuisine: 1},
{ partialFilterExpression: { rating: { $gt: 5 } } }
)
partialFilterExpression选项接受一个文档,该文档使用以下方式指定筛选条件 :
- equality expressions, //布尔表达式,等于
- $exists: true expression,
- $gt, $gte, $lt, $lte expressions,
- $type expressions,
- $and operator at the top-level only //只在顶层操作符
2、查询范围
- 可使用索引
db.restaurants.find( { cuisine: "Italian", rating: { $gte: 8 } } )
- 不可使用索引
db.restaurants.find( { cuisine: "Italian", rating: { $lt: 8 } } )
db.restaurants.find( { cuisine: "Italian" } )
//该查询不能使用部分索引,因为查询谓词不包括筛选器表达式,并且使用索引将返回不完整的结果集。
//部分索引根据指定的筛选器确定索引项。过滤器不仅可以包括索引键以外的字段 并指定条件,还可以指定 为索引键。如图 1,对字段 a大于 5的文档加正序索引,那么 a是 1-4的文档上则不会有索引。
//我们还可以使用部分索引实现与 sparse索引相同的行为 :如下面左侧第二个图,对 wechat做正序且存在的 文档做索引,这就实现了稀疏索引的效果

八、执行计划¶
8.1 获取执行计划¶
1、支持的操作
aggregate(); count(); distinct(); find(); group(); remove(); update()
2、格式: db.collection.find().explain(verbose)
其中 verbosity说明返回信息的粒度。verbosity参数:
- queryPlanner,缺省模式,对当前的查询进行评估并选择一个最佳的查询计划 //不会真正进行query语句查询,而是针对query语句进行执行计划分析并选出winning plan。
- executionStats,对当前的查询进行评估并选择一个最佳的查询计划进行执行 //在执行完毕后返回这个最佳执行计划执行完成时的相关统计信息;对于写操作db.collection.explain()返回关于更新和删除操作的信息,但是并不将修改应用到数据库;对于那些被拒绝的执行计划,不返回其统计信息
- allPlansExecution,前2种模式的更细化,即会包括上述2种模式的所有信息 //即按照最佳的执行计划执行以及列出统计信息,而且还会列出一些候选的执行计划,如果有多个查询计划,executionStats信息包括这些执行计划的部分统计信息
- IXSCAN 索引扫描
- FETCH 根据索引去检索文档
- SHARD_MERGE 合并分片结果
/data/mongodb/mongodb_repl/bin/mongo 192.168.1.150:27018/admin -uroot -proot123456
use test
for(var i = 1 ;i < 10000; i++) {
db.col.insert({name: i,age:i,date:new Date()});
}
db.col.find({name:1111}).explain(true)
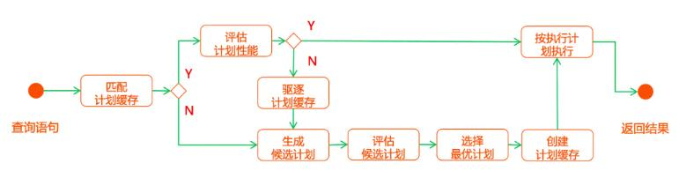

8.2 优化后的执行计划¶
db.col.createIndex({name:1})
db.col.find({name:1111}).explain(true)

九、索引管理¶
1、查看索引
db.col.getIndexes() #用来查看集合的所有索引,
db.col.getIndexKeys() #查看索引键。
db.col.totalIndexSize() #查看集合索引的总大小,
db.col.getIndexSpecs() #查看集合各索引的详细信息
2、在后台创建索引
db.col.createIndex({open: 1, close: 1}, {background: true}) //通过在创建索引时加 background:true 的选项,让创建工作在后台执行,不阻塞其他数据库操作
3、查看集合索引大小
db.col.totalIndexSize()
4、查看数据库中所有索引
db.system.indexes.find();
5、删除索引
db.col.dropIndexes() #删除集合所有索引
db.col.dropIndex("索引名称 ") #删除指定索引
6、查看索引创建进度
db.currentOp({
$or: [
{ op: "command", "query.createIndexes": { $exists: true } },
{ op: "insert", ns: /\.system\.indexes\b/ }
]
});
7、终止索引的创建
db.killOp()
8、索引的最大范围
- 集合中索引不能超过 64个
- 索引名的⻓度不能超过 128个字符
- 一个复合索引最多可以有 31个字段
9、索引限制
- 额外开销 : 每个索引占据一定的存储空间,在进行插入,更新和删除操作时也需要对索引进行操作。所以, 如果你很少对集合进行读取操作,建议不使用索引。
- 内存 (RAM)使用 : 由于索引是存储在内存 (RAM)中 ,你应该确保该索引的大小不超过内存的限制。如果索引 的大小大于内存的限制, MongoDB会删除一些索引,这将导致性能下降。
- 查询限制 : 索引不能被以下的查询使用 :正则表达式及非操作符,如 $nin, $not,等、算术运算符