1、避免使用 skip,改为使用范围查询
在官方文档中的 skip 章节有提及:
Using Range Queries
Range queries can use indexes to avoid scanning unwanted documents, typically yielding better performance as the offset grows compared to using cursor.skip() for pagination.
2、用简单唯一的 id 替换 _id,节省空间
3、不要用文档做 _id
//除了不可避免的情况,通常都不应该将文档作为 _id。更改 _id 必须覆盖整个文档,所以若子文档的字段有变化则更新非常不便。
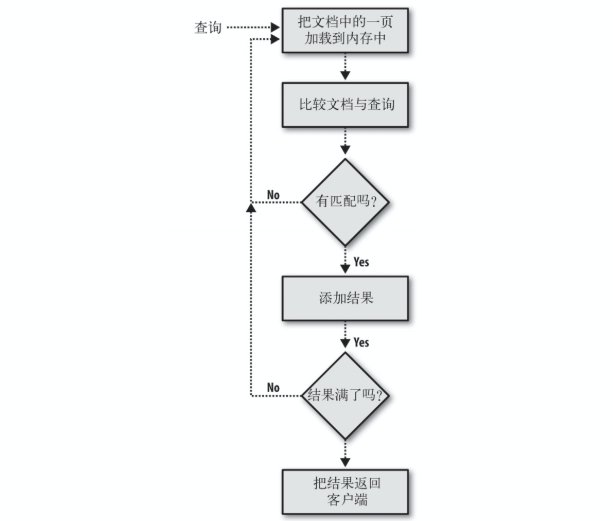
4、尽可能减少磁盘访问
5、使用索引减少内存占用
-- 假设设内存页面大小为 4 KB,机器共有 256 GB 的数据,16 GB 的内存,并且几乎所有数据都在一个集合上查询能在集合中找到一两个匹配的文档。
不用索引的话,我们必须把 64 000 000 个页面从硬盘加载到内存。
页面:256 GB / (4 KB/ 页面 ) = 64 000 000 页面
若是索引有 80 GB,则索引有 20 000 000 页面。
页面:80 GB / (4 KB/ 页面 ) = 20 000 000 页面
-- 另外,索引是有序的,所以不必遍历全部项,只要加载其中的一部分节点就可以了。有多少呢?要加载进内存的页面:ln(20 000 000) = 17 页面
6、返回集合一半的数据不要使用索引
7、使用覆盖索引加快查询
//如果只想返回某些字段且所有这些字段都可放在索引中,mongodb 可以做索引覆盖查询,这种查询不会访问指针指向的文档,而是直接用索引的数据返回结果。
8、使用复合索引加快多个查询
9、建立分级文档加速扫描
10、and 型查询要点:优先使用区分度最大的字段先查询,减少后续查询的搜索空间
//假设要查询满足条件 A/B/C 的文档,满足 A 的 4w,满足 B 的 9k,满足 C 的 200。要是让 mongo 按照这个顺序查询,效率可不高。如果吧 C 放在最前,最后是 A,则针对 B 和 C 只需要查看最多 200 个文档。这样工作量显著减少了,要是已知某个查询条件更加苛刻,则要将其放在最前面,尤其是在它有对应索引的时候。
or 型优化要点:匹配最多的查询语句放在最前面
//or 型查询与 and 型查询正相反,匹配最多的查询语句放在最前面,因为 mongo 每次都要匹配不在结果集中的文档。
读请求的处理顺序如下图: