

一、NoSQL数据库简介¶
1.1 入门概述¶
1.1.1 技术架构发展历程¶
1.1.1.1 单机MySQL时代¶
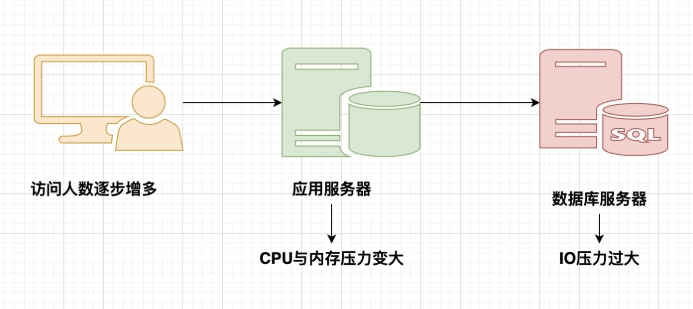
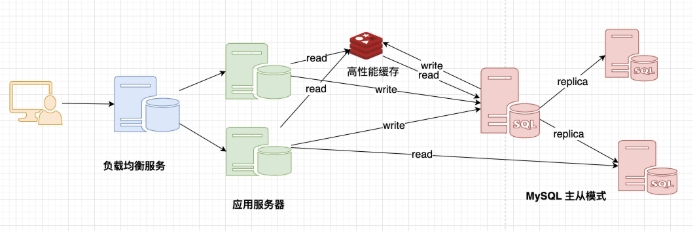
1.1.1.2 高性能缓存+MySQL+读写分离¶
发展过程: 优化数据结构和索引--> 文件缓存(IO)---> Memcached(当时最热门的技术!)
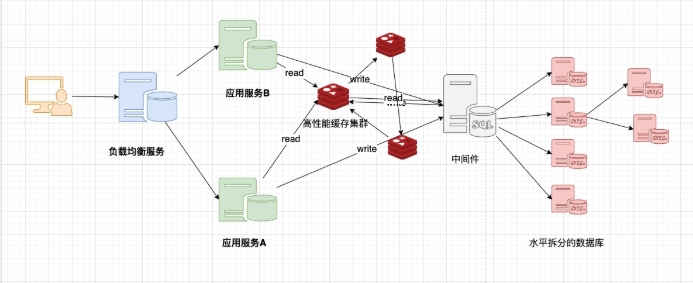
1.1.1.3 分库分表+水平拆分+MySQL集群¶
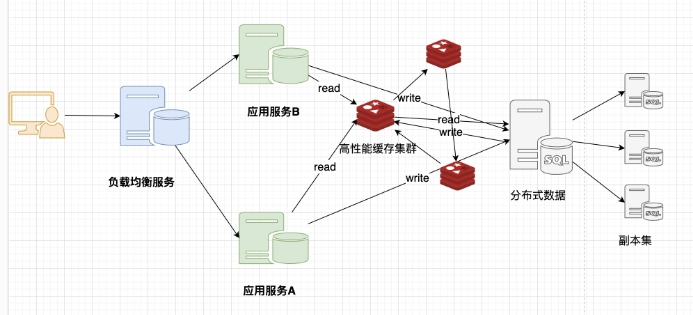
1.1.1.4 分布式数据库 + NoSQL¶
1.2 NoSQL简介与特点¶
1.2.1 NoSQL简介¶
定义
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”。 -- 我们看下关键点
-
泛指非关系型的数据库。
-
不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
-
不遵循SQL标准。
-
不支持ACID
-
远超于SQL的性能
1.2.2 特点¶
1、易扩展
-
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。
-
数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
2、海量数据的高并发读写
-
数据结构简单: NoSQL数据库都具有非常高的读写性能,尤其在大数据量下。
-
Cache:MySQL 使用Query Cache粗粒度,nosql cache记录级,细粒度
3、数据模型灵活
- NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
1.2.3 不适用场景¶
1、需要事务支持
2、基于sql的结构化查询存储,处理复杂的关系,需要即时查询。
1.2.4 RDBMS vs NoSQL¶
RDBMS
-
高度组织化结构化数据
-
结构化查询语言(SQL)
-
数据和关系都存储在单独的表中。
-
数据操纵语言,数据定义语言
-
严格的一致性 ACID
-
基础事务
NoSQL
-
代表着不仅仅是SQL
-
没有声明性查询语言
-
没有预定义的模式
-
键-值对存储,列存储,文档存储,图形数据库
-
最终一致性,而非ACID【原子,一致,隔离,持久】属性
-
非结构化和不可预知的数据
-
CAP定理【一致性,可用性,容错性】
-
高性能,高可用性和可伸缩性
1.3 NoSQL数据库分类¶
1.3.1 KV键值¶
Memcache
-
很早出现的NoSql数据库
-
数据都在内存中,不持久化
-
支持简单的key-value模式,支持类型单一
-
缓存数据库辅助持久化的数据库
Redis
-
数据都在内存中,支持持久化,主要用作备份恢复
-
支持多种数据结构
-
支持主从 哨兵 集群
1.3.2 文档型¶
MongoDB
-
是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
-
高性能、开源、模式自由(schema free)的文档型数据库
-
对value(尤其是json)提供了丰富的查询功能数据都在内存中, 如果内存不足,把不常用的数据保存到
硬盘
-
支持二进制数据及大型对象
-
可以根据数据的特点替代RDBMS ,成为独立的数据库。或者配合RDBMS,存储特定的数据
1.3.3 列存数据库¶
Cassandra(大数据)
-
管理由大量商用服务器构建起来的庞大集群上的海量数据集(数据量通常达到PB级别)。
-
对写入及读取操作进行规模调整,而且其不强调主集群的设计思路能够以相对直观的方式简化各集群的创建 与扩展流程。
HBase(大数据)
-
HBase是Hadoop项目中的数据库。它用于需要对大量的数据进行随机、实时的读写操作的场景中。
-
用普通的计算机处理超过10亿行数据,还可处理有数百万列元素的数据表。
分布式文件系统
ClickHouse(下期,云原生指标收集)
StarRocks DorisDB(下期,重量级AP实时数仓)
1.3.4 图数据库¶
社交网络,推荐系统等。专注于构建关系图谱
-
Neo4J:主要应用:社会关系,公共交通网络,地图及网络拓谱(n*(n-1)/2)
-
NebulaGraph(下期):分布式图数据库,知识图谱
二、Redis 简介与安装部署¶
2.1 如何学习Redis¶
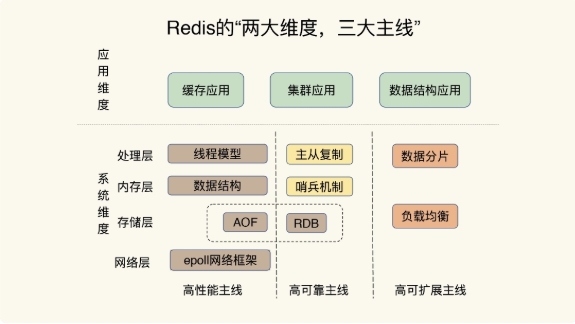
绘制Redis 全景知识图:
-
两大维度:系统维度和应用维度
-
三大主线:高性能、高可靠和高可扩展
视频补充:如何借助全景知识图学习 Redis
-
系统维度可以继续细分为处理层、存储层、网络层,适合从底层原理理解 Redis 为什么快、为什么这样设计。
-
应用维度可以从缓存应用、集群应用、数据结构应用三个方向整理,便于把命令、场景和架构串起来。
-
三条主线可以和具体知识点对应起来:
- 高性能:线程模型、数据结构、epoll 网络框架
- 高可靠:AOF、RDB、主从复制、哨兵
-
高可扩展:数据分片、负载均衡、集群
-
学习时不要只记零散命令,最好把知识点放回整个体系中,这样排障、面试和设计缓存架构时都能更快定位问题。
2.2 简介¶
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。 Redis 与其他 key - value 缓存产品相比有以下三个特点:
-
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
-
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存 储。
-
Redis支持数据的备份,即master-slave模式的数据备份。
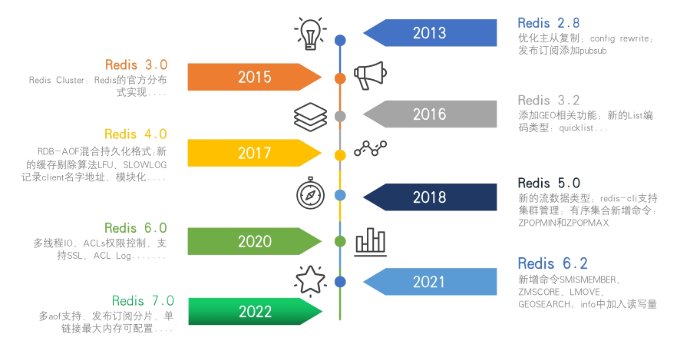
2.2.1 发展史¶
视频补充:Redis 重要版本演进
-
2013 年 Redis 2.8:主从复制、config rewrite、Pub/Sub 等能力逐步成熟。
-
2015 年 Redis 3.0:官方推出 Redis Cluster,开始具备完整的分布式集群方案。
-
2016 年 Redis 3.2:新增 GEO、quicklist 等特性。
-
2017 年 Redis 4.0:引入模块化能力,并增强持久化相关特性。
-
2018 年 Redis 5.0:新增 stream 数据类型,消息队列场景更完善。
-
2020 年 Redis 6.0:引入多线程 I/O、ACL、SSL 等能力。
-
2022 年 Redis 7.0:Functions、Multi-Part AOF、Sharded Pub/Sub 等特性继续增强。
2.2.2 Redis 特性与优势¶
性能极高
- Redis官方给的数据是,读的速度是11w次/s,写的速度是8.1w次/s 。
丰富的数据类型
- Redis支持二进制的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
支持多种数据结构
- 例如:hash、set、bitmap、HyperLogLog、GEO
支持持久化
- 通过RDB/AOF实现数据的备份
支持主从复制
支持分布式集群和高可用
原子
-
Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子 性的。
-
多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来(注意,它的事务异常并不会回 滚)。
丰富的特性
- Redis还支持 publish/subscribe, lua脚本、通知, Pipeline、key 过期等特性。
2.2.3 Redis的使用场景¶
- 缓存功能
- 静态数据缓存,登录信息缓存,事实数据缓存,减轻查询数据的压力
-
会话session缓存,分布式系统无状态
-
计数器
-
利用incr分布式计数,减轻数据库压力
-
消息队列
- 利用list实现简单的消息队列
-
stream实现消息队列
-
排行榜/限流/延迟队列
- 排行榜利用zset的score,分数越大排的靠前
- 限流利用时间戳作为score,通过区间计数限流
-
延迟队列通过将到期时间戳作为score,通过当前时间查询
-
点赞/可能认识的人
-
利用set及其交集功能
-
附近的人(geo)
-
签到/布隆过滤器(bitmap)
-
信息流(list)
-
统计UV(hyperloglog)