

一、redis 为什么快?¶
-
业务执行单线程,避免cpu不必要的上下文切换
-
存内存操作
-
I/O 多路复用+事件模型
-
高效的数据结构+合理的数据编码
视频补充:单线程模型为什么还能很快
-
单线程模型避免了多线程场景下频繁的线程切换、锁竞争和同步开销,这也是 Redis 在命令执行路径上保持简洁和高性能的重要原因。
-
Redis 所说的“单线程”,主要是指命令执行这条主路径是串行的;并不代表整个 Redis 进程只有一个线程。
-
从较新版本开始,Redis 已经引入后台线程或 I/O 线程来分担部分非命令执行工作,但核心命令处理依然是单线程完成。
二、I/O 模型介绍¶
视频补充:理解 I/O 模型前的两个基础概念
-
I/O 是 Input/Output 的缩写,通常指应用程序与外部世界之间的数据交换,在网络编程里常常就是数据从内核到用户态、再从用户态回到网络设备的过程。
-
一次 I/O 通常可以拆成两个阶段:
- 等待数据准备好
-
把数据从内核空间拷贝到用户空间
-
从这个角度看,常见的网络 I/O 模型可以归纳为五种:阻塞 I/O、非阻塞 I/O、I/O 多路复用、信号驱动 I/O、异步 I/O。
2.1 阻塞式 I/O 模型(Blocking I/O )¶
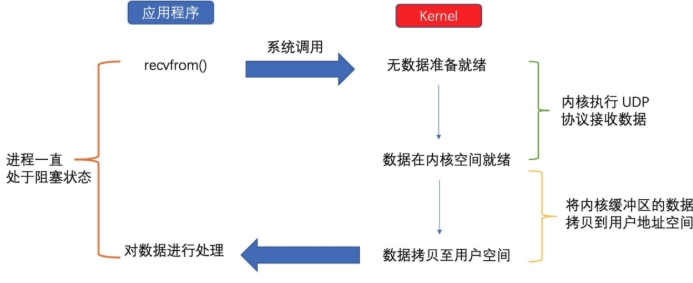
程序在进行 I/O 操作时会阻塞等待操作完成,直到读写完成后才能继续执行。
应用程序通过调用recvfrom接收数据,由于内核还未准备好数据,应用程序就会阻塞,直到内核准备好数 据,recvfrom完成数据复制工作,应用程序才能结束阻塞状态。
2.2 非阻塞式 I/O 模型(Non-blocking I/O)¶
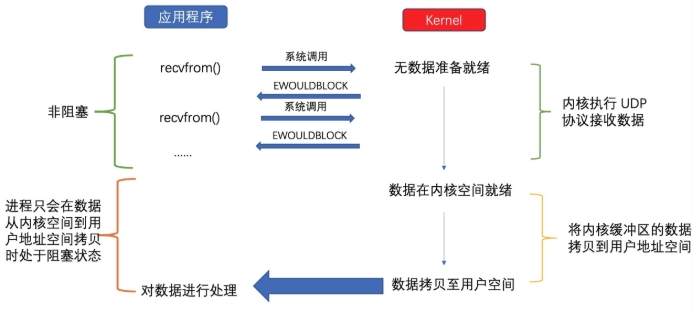
程序在进行 I/O 操作时不会阻塞等待操作完成,而是立即返回,通过轮询方式不断查询 I/O 操作是否完成。
应用进程通过recvfrom调用不停地去和内核交互,直到内核准备好数据。如果没有准备好,内核会返回error,应用进程在得到error后,过一段时间再发送recvfrom请求。在两次发送请求的时间段,进程可以先做别的事情。
2.3 I/O 多路复用模型 (I/O Multiplexing )¶
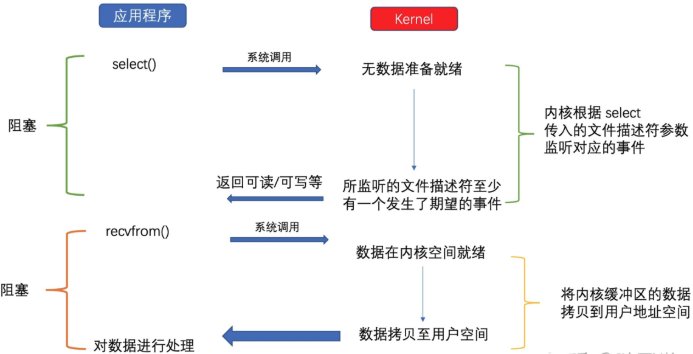
程序使用 select/poll/epoll 等系统调用同时监听多个文件描述符,当其中任意一个文件描述符可以进行 I/O 操作时,程序才会阻塞等待该操作完成
IO多路转接是多了一个select函数,多个进程的IO可以注册到同一个select上,当用户进程调用该select,select会监听所有注册好的IO,如果所有被监听的IO需要的数据都没有准备好时,select调用进程会阻塞。当任意一个IO所需的数据准备好之后,select调用就会返回,然后进程再通过recvfrom来进行数据拷贝。
这里的IO复用模型,并没有向内核注册信号处理函数,所以它并不是非阻塞的。进程在发出select后,要等到select监听的所有IO操作中至少有一个需要的数据准备好,才会有返回,并且也需要再次发送请求去进行文件的拷贝。
2.4 信号驱动 I/O 模型 (Signal-driven I/O)¶
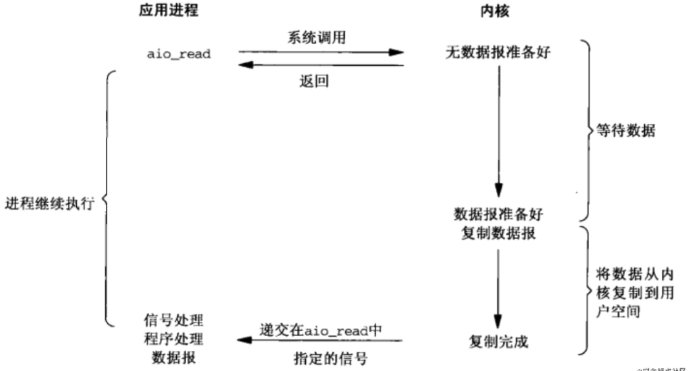
程序通过调用 sigaction 函数来安装一个信号处理函数,然后对文件描述符设置一个标记使其处于信号驱动 式 I/O 模式。当 I/O 操作完成时,会向进程发送一个信号,由信号处理函数来处理 I/O 完成事件。

2.5 异步 I/O 模型 (Asynchronous I/O )¶
程序发起 I/O 操作后可以立即返回,由内核来负责等待 I/O 操作完成,并通知进程完成事件,进程在接收 到通知后再来处理完成事件
三、reactor 模式¶
什么是 reactor 模式?
-
一种事件驱动处理模式
-
处理一个或多个输入并发请求
-
服务器通过 handler 对请求进行多路分发,分发给处理器
Reactor 模式一共有三种模式
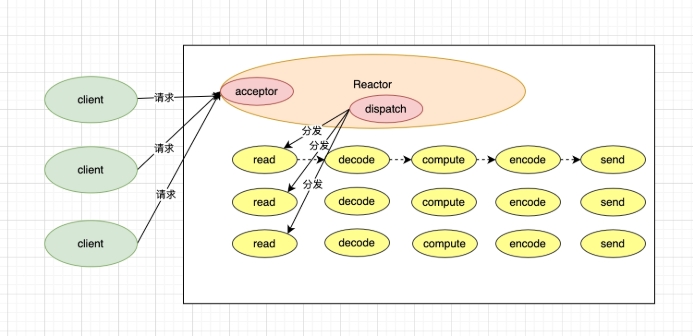
3.1 单reactor单线程 模型¶
-
整个过程只有一个线程处理
-
redis 6.0 之前都是使用这个模型
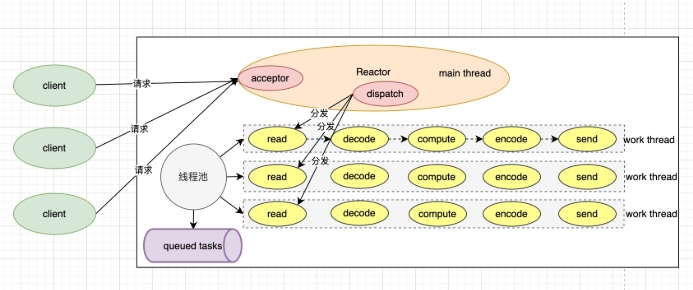
3.2 单 reactor 多线程处理模型¶
-
一个线程接(reactor)只负责分发
-
处理由多线程处理
-
redis 6.0 使用的是这个模型的(稍微有点变化)
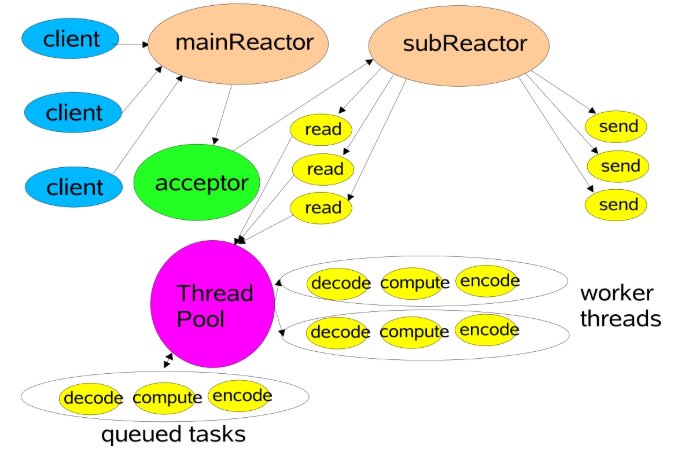
3.3 多线程 reactor 模型¶
-
由 reactor 由线程池担任
-
任务处理由另一个线程池承担
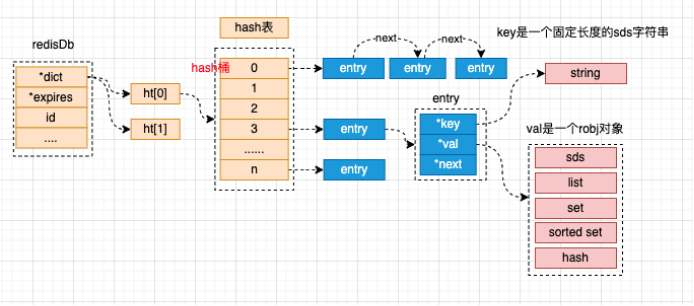
四、存储结构¶
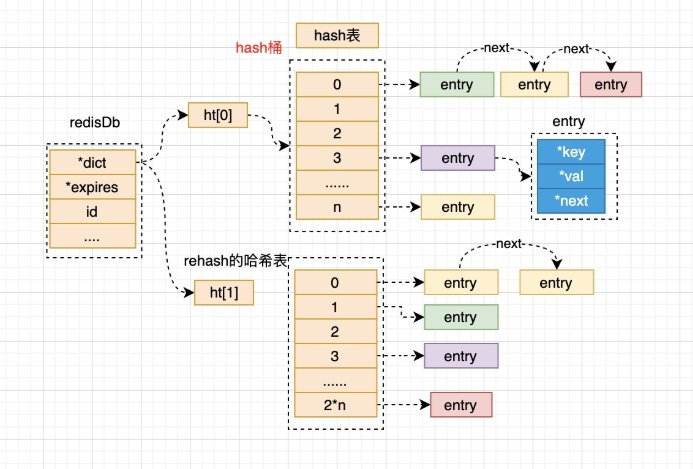
redis默认有16个redisDb,通过select num 选择数据库,从0开始是第一个库。
4.1 渐进式 rehash¶
redis初始化以后,hash桶的大小是固定的,随着插入的元素增多,redis的hash桶会不够用,如果不对 hash进行扩容,就会一直在对应的hash位的链表上一直添加元素,就会导致hash查询由O(1)退化到O(n)。
redis就为了平衡性能和成本,会进行rehash。rehash有两块,一块是扩容,一块缩容。
- 扩容
- 防止key过多,hash冲突、链化导致的查询性能下降
- 5倍容量后才会触发扩容
-
往上取当前hash值最近的2的幂次方(比如原始大小2,插入到10个以后,直接扩容到16)
-
缩容
- 大量key过期后,hash过大,会有大量的空闲空间
- 降到1/10以下的使用量才会触发
如果是常规的rehash,铁定会阻塞redis,会影响redis的性能,那redis是怎么做的呢?redis使用一种渐 进式rehash进行扩容。
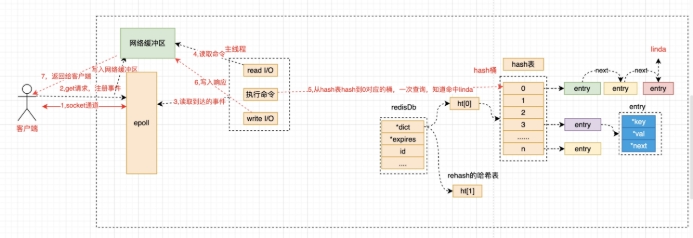
五、一次 get 命令的执行流程¶
5.1 redis 运行模型¶
想了解一个命令的执行,我们先看下redis 是怎么工作的。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
//2,每次循环前执行beforesleep
eventLoop->beforesleep(eventLoop);
//3,事件处理
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
5.2 get 命令执行流程¶
我们通过一次get请求来看下redis是如何执行的。
六、redis 的数据清理机制¶
清理方式
-
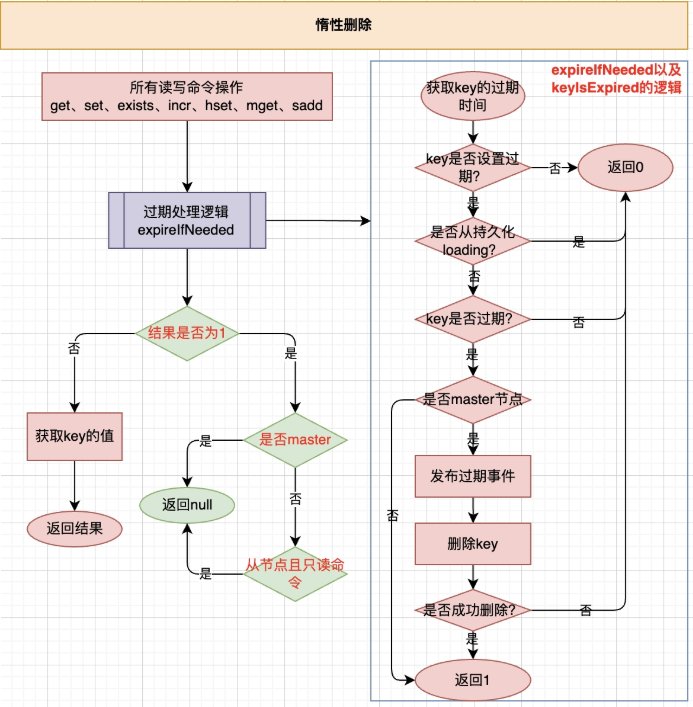
惰性删除
-
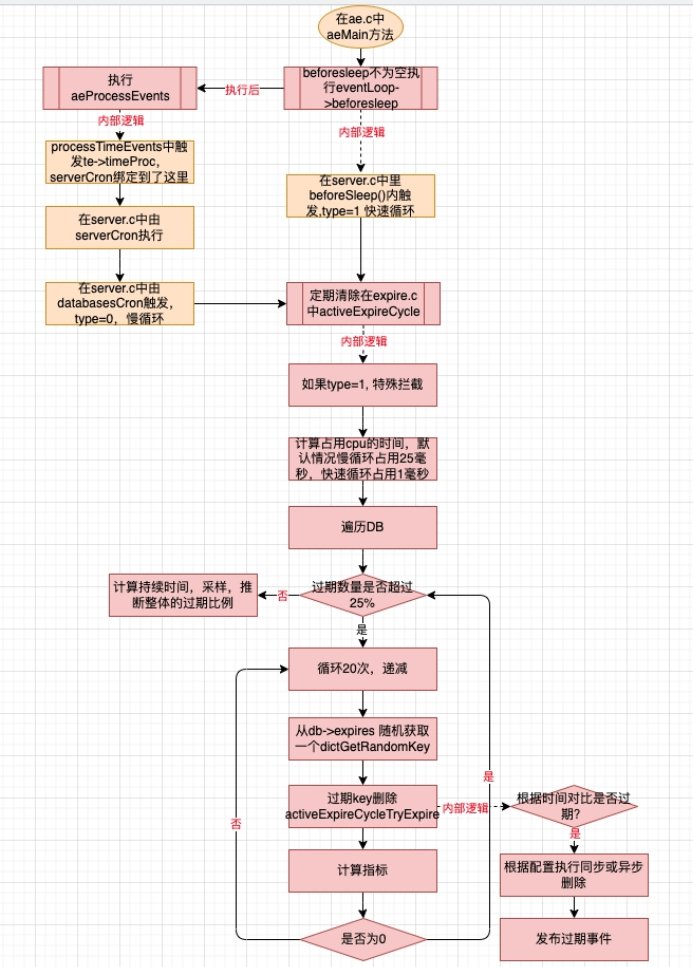
定期删除
-
内存淘汰机制
6.1 惰性删除¶
6.2 定期清理¶
6.3 内存淘汰机制¶
Redis 的几种淘汰策略:
-
noeviction 无过期策略,内存满了就直接异常
-
volatile-lru 对有过期时间的 key 进行 lru 淘汰(越长时间没有被访问,越容易被淘汰)
-
allkeys-lru 对全局的 key 按 LRU 进行淘汰(越长时间没有被访问,越容易被淘汰)
-
volatile-lfu 对有过期时间的 key 进行 lfu 淘汰(经常不被访问的,越容易被淘汰)
-
allkeys-lfu 对全局的 key 进行 lfu 淘汰(经常不被访问的,越容易被淘汰)
-
volatile-random 对有过期时间的 key 进行随机淘汰
-
allkeys-random 对有所有的 key 进行随机淘汰
-
volatile-ttl 按时间进行过期淘汰