

一、Redis备份恢复¶
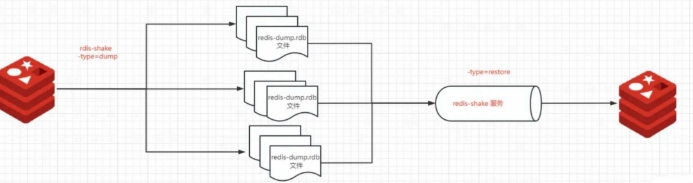
1.1 备份¶
def rdb_bak(self, pwd):
cmd_bak_redis="{recmd} -h {host} -p {port} -a '{pwd}' --rdb {file}"\
.format(recmd=recmd, host=self.domain_ip, port=self.port, pwd=pwd, file=self.rdb_file_path)
(status, output) = commands.getstatusoutput(cmd_bak_redis)
log.info(output)
if status == 0:
log.error(output)
return False,"backup fail"
return True, "backup successful"
1.2 恢复¶
def restore_rdb(self):
#获取集群当天的 rdb文件
if not self.cmdutil.is_exists(self.rdb_dir):
msg = "rdb_dir={} is not exsist.".format(self.rdb_dir)
self.send_mq.send_fail(tag, self.id, msg, self.title)
return
rdb_files_path_list = self.get_rdb_files(self.rdb_dir)
rdb_files_path_str = rdb_files_path_list[0]
if len(rdb_files_path_list) > 1:
rdb_files_path_str = ";".join(rdb_files_path_list)
log.info(rdb_files_path_str)
#1.修改配置中的数据
sta_m = self.modify_conf(rdb_files_path_str)
log.info(sta_m)
if not sta_m:
msg = "{}修改失败 ".format(self.shakeconf)
self.send_mq.send_fail(tag, self.id, msg, self.title)
return
#2.执行恢复的命令
cmd_shake = "./redis-shake -conf=conf/rdb_{}.conf -type=restore &".format(str(self.restorePort))
log.info("cmd_shake=%s", cmd_shake)
os.popen(cmd_shake)
log.info("Redis data is recovering, please wait...........")
#3.判断恢复是否完成
sta, msg = self.is_rdb_success()
log.info(msg)
def modify_conf(self, rdb_files_path_str):
tar_host="{}:{}".format(self.restoreHost, str(self.restorePort))
log.info("target.address=%s", tar_host)
log.info("source.rdb.input=%s", rdb_files_path_str)
target_address = "target.address = {}".format(tar_host)
rdb_input = "source.rdb.input = {}".format(rdb_files_path_str)
cmd_host = "sed -i 's#^target.address.*#%s#g' %s" % (target_address, self.shakeconf)
cmd_rdb = "sed -i 's#^source.rdb.input.*#%s#g' %s" % (rdb_input, self.shakeconf)
log.info(cmd_host)
log.info(cmd_rdb)
status1, output1, msg1 = self.command(cmd_host)
if not status1:
log.error(output1)
return False
status2, output2, msg2 = self.command(cmd_rdb)
if not status2:
log.error(output2)
return False
return True
二、Redis企业使用规范¶
2.1 开发规范¶
1、key名设计
【建议】 : 可读性和可管理性
以业务名 (或数据库名 )为前缀 (防止 key冲突 ),用冒号分隔,比如业务名 :表名 :id ugc:video:1
【建议】:简洁性
保证语义的前提下,控制 key的长度,当 key较多时,内存占用也不容忽视,例如: user::friends:messages:简化为 u::fr:m:。
【强制】:不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符
2、value设计
【强制】:拒绝 bigkey(防止网卡流量、慢查询 ) #最重要
string类型控制在 10KB以内, hash、 list、 set、 zset元素个数不要超过 5000。
反例:一个包含 200万个元素的 list。
非字符串的 bigkey,不要使用 del删除,使用 hscan、 sscan、 zscan方式渐进式删除,同时要注意防止 bigkey过期时间自动删除问题 (例如一个 200万的 zset设置 1小时过期,会触发 del操作,造成阻塞,而且该 操作不会不出现在慢查询中 (latency可查 )),查找方法和删除方法
【推荐】:选择适合的数据类型。
例如:实体类型 (要合理控制和使用数据结构内存编码优化配置 ,例如 ziplist,但也要注意节省内存和性能之 间的平衡 )
反例:
set user:1:name tom
set user:1:age 19
set user:1:favor football
正例 :
hmset user:1 name tom age 19 favor football
3、控制 key的生命周期, redis不是垃圾桶。
建议使用 expire设置过期时间 (条件允许可以打散过期时间,防止集中过期 ),不过期的数据重点关注 idletime。
2.2 命令使用¶
1.【推荐】 O(N)命令关注 N的数量
例如 hgetall、 lrange、 smembers、 zrange、 sinter等并非不能使用,但是需要明确 N的值。有遍历的需 求可以使用 hscan、 sscan、 zscan代替。
2.【推荐】:禁用命令
禁止线上使用 keys、 flushall、 flushdb等,通过 redis的 rename机制禁掉命令,或者使用 scan的方式渐 进式处理。
3.【推荐】合理使用 select redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处 理,会有干扰。
4.【推荐】使用批量操作提高效率
原生命令:例如 mget、 mset。
非原生命令:可以使用 pipeline提高效率。
但要注意控制一次批量操作的元素个数 (例如 500以内,实际也和元素字节数有关 )。 注意两者不同:
- 原生是原子操作, pipeline是非原子操作。
- pipeline可以打包不同的命令,原生做不到。
- pipeline需要客户端和服务端同时支持。
5.【建议】 Redis事务功能较弱,不建议过多使用
Redis的事务功能较弱 (不支持回滚 ),而且集群版本 (自研和官方 )要求一次事务操作的 key必须在一个 slot上 (可以使用 hashtag功能解决 )
6.【建议】 Redis集群版本在使用 Lua上有特殊要求:
所有 key都应该由 KEYS 数组来传递, redis.call/pcall 里面调用的 redis命令, key的位置,必须是 KEYS array, 否则直接返回 error, "-ERR bad lua script for redis cluster, all the keys that the script uses should be passed using the KEYS arrayrn"
所有 key,必须在 1个 slot上,否则直接返回 error, "-ERR eval/evalsha command keys must in same slotrn"
7.【建议】必要情况下使用 monitor命令时,要注意不要长时间使用。
2.3 客户端使用¶
1.【推荐】
避免多个应用使用一个 Redis实例
正例:不相干的业务拆分,公共数据做服务化。
2.【推荐】
使用带有连接池的数据库,可以有效控制连接,同时提高效率,标准使用方式:
3.【建议】
高并发下建议客户端添加熔断功能 (例如 netflix hystrix)
4.【推荐】
设置合理的密码,如有必要可以使用 SSL加密访问(阿里云 Redis支持)
5.【建议】
根据自身业务类型,选好 maxmemory-policy(最大内存淘汰策略 ),设置好过期时间。
默认策略是 volatile-lru,即超过最大内存后,在过期键中使用 lru算法进行 key的剔除,保证不过期数据 不被删除,但是可能会出现 OOM问题。
其他策略如下:
allkeys-lru:根据 LRU算法删除键,不管数据有没有设置超时属性,直到腾出足够空间为止。 allkeys-random:随机删除所有键,直到腾出足够空间为止。 volatile-random:随机删除过期键,直到腾出足够空间为止。
volatile-ttl:根据键值对象的 ttl属性,删除最近将要过期数据。如果没有,回退到 noeviction策略。 noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息 "(error) OOM command not allowed when used memory",此时 Redis只响应读操作。
2.4 删除 bigkey¶
redis 4.0已经支持 key的异步删除,欢迎使用。
1、Hash删除 : hscan + hdel 2、List删除 : ltrim 3、Set删除 : sscan + srem 4、SortedSet删除 : zscan + zrem