
一、Ollama介绍与特性¶
1.1 什么是Ollama¶
Ollama是一个轻量级、易于使用的大模型管理和部署工具,主要用于简化大模型的运行和交互。并且为开发者和用户提供了快速加载、管理和调用多种主流大模型的能力,同时支持本地化部署各类大模型。
1.2 Ollama核心特点¶
- 轻量化设计:0llama体积小巧,安装简单,适合个人开发者和小型团队
- 多模型支持:支持多种主流大模型,如Llama系列、Qwen系列、Deepseek系列等
- 资源优化:通过量化技术降低模型显存占用,减少对高性能GPU的依赖
- 易用性:提供命令行工具和图形化界面,方便用户操作
- 扩展性强:可以与其他工具(如Kubernetes、Docker)结合,实现分布式部署和管理
二、Ollama与其他工具的对比¶
2.1 Ollama¶
安装简单,提供CLI和WebUI,适合初学者和开发者支持量化技术降低内存占用,适合普 通硬件、支持Linux、macOS和Windows、支持大部分主流模型。但是Ollama并发性能 不如vLLM。
2.2 vLLM¶
vLLM是一个高效的大模型推理和服务引擎,在多GPU环境下性能表现优异,更适合大规模在线推理服务。但是vLLM的部署复杂度较高,需要一定的技术基础,主要面向Linux,跨平台支持有限。
2.3 LocalAI¶
LocalAI和Ollama相似,是一个轻量级的本地大模型服务框架,开箱即用,无需复杂配置。但是性能优化不如vLLM和Ollama,并且功能较少,比如不支持多线程加速等。
三、Ollama与WebUI部署¶
3.1 腾讯云GPU机器申请¶
1、登录腾讯云官网https://cloud.tencent.com/,依次点击【产品】-【计算】-【GPU云服务器】
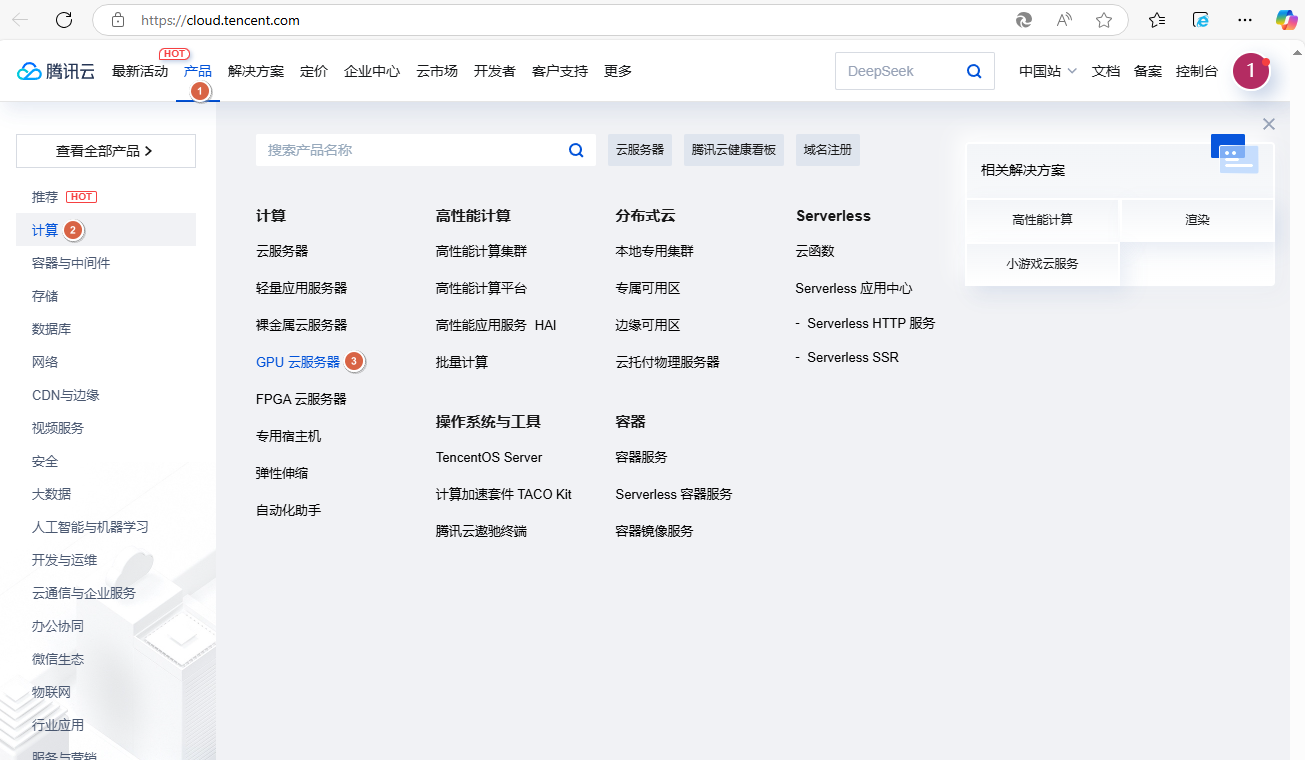
2、点击【立即选购】
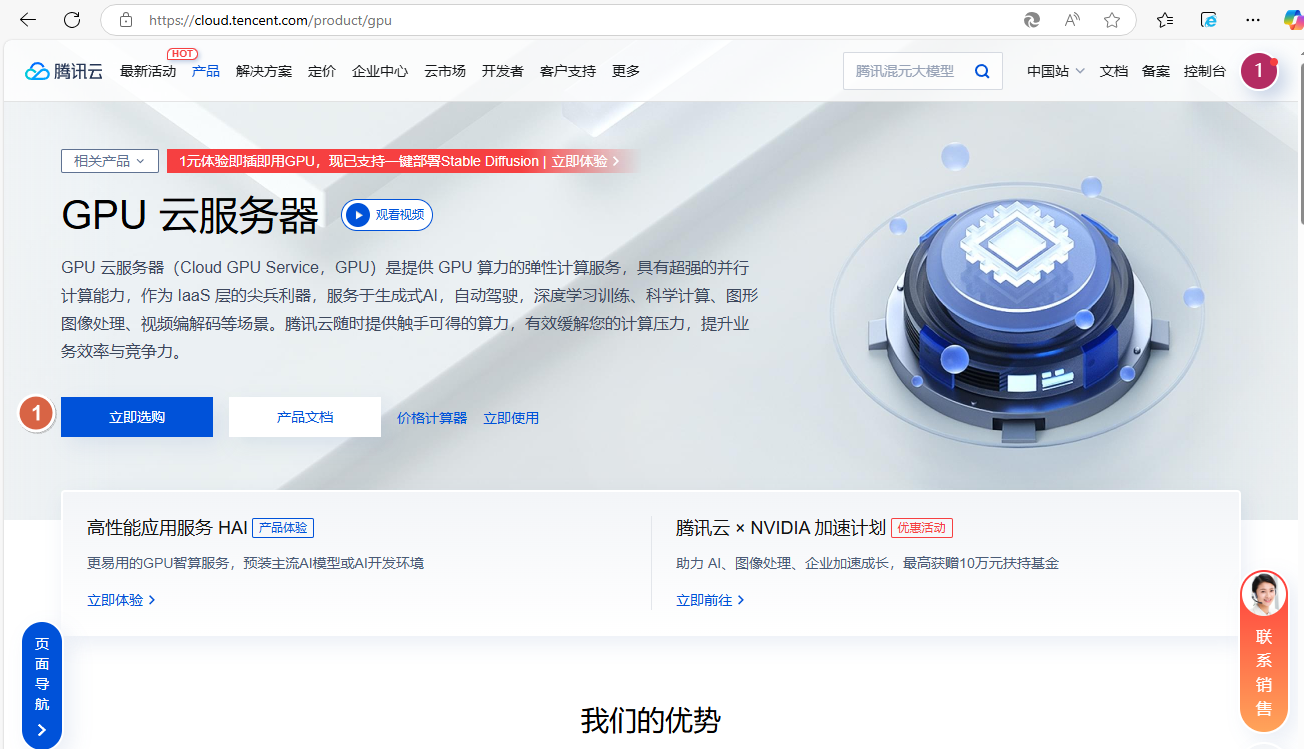
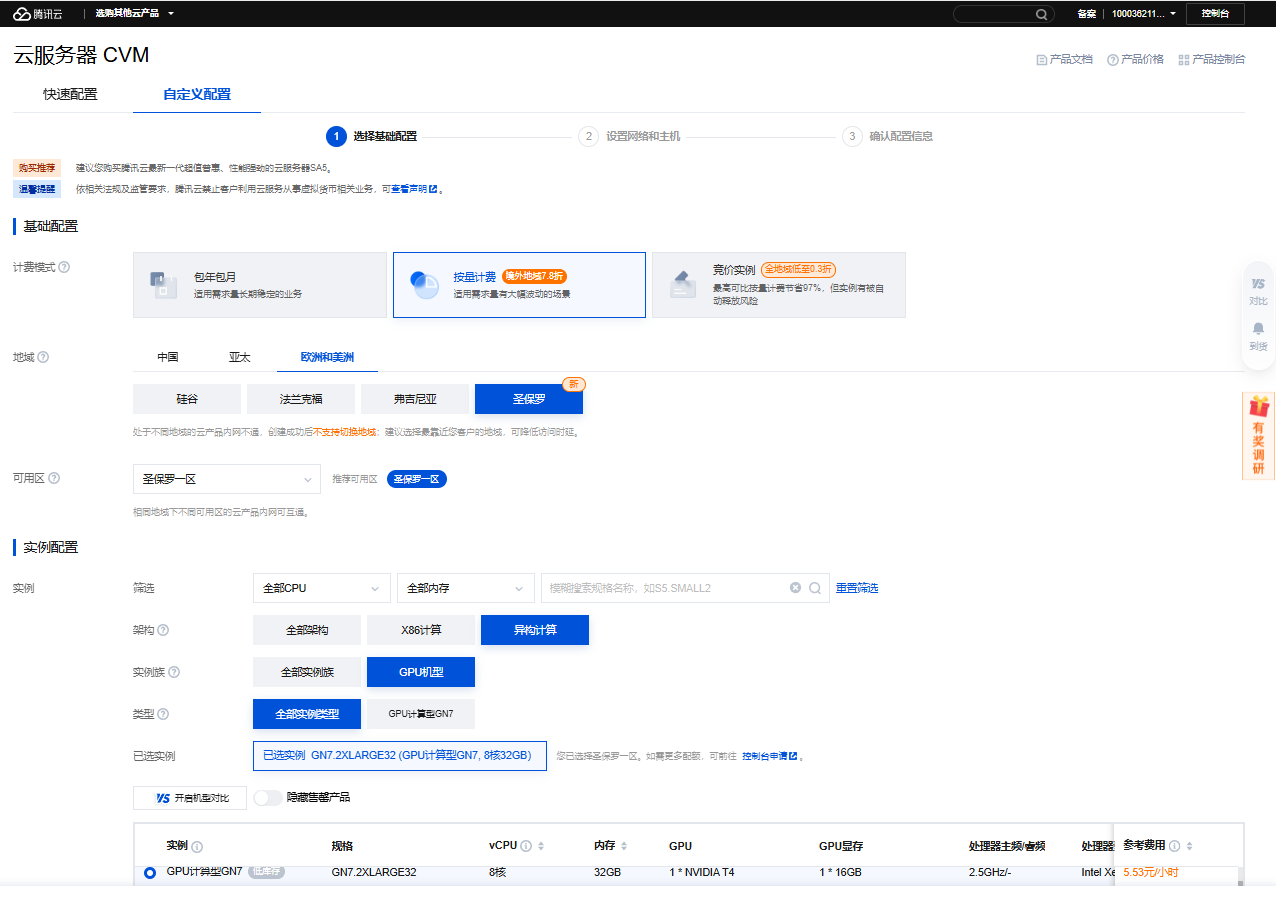
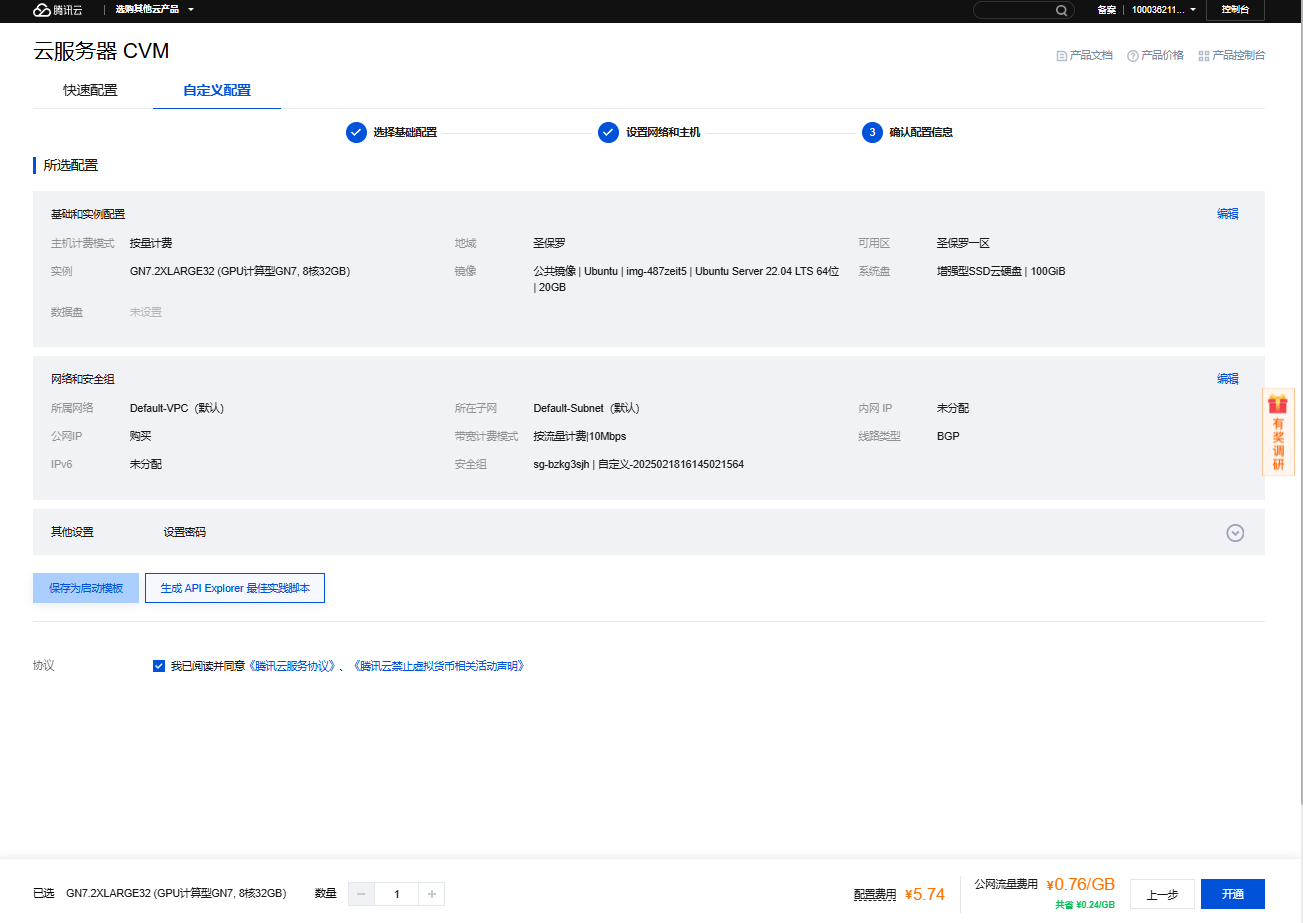
3、配置【选择基础配置】,点击【下一步:设置网络和主机】
基础配置:
- 计费模式:按量付费
- 地域:欧洲和美洲-圣保罗
- 可用区:圣保罗一区
实例配置:
- 架构:异构计算
- 实例族:GPU机型
- 类型:全部实例类型
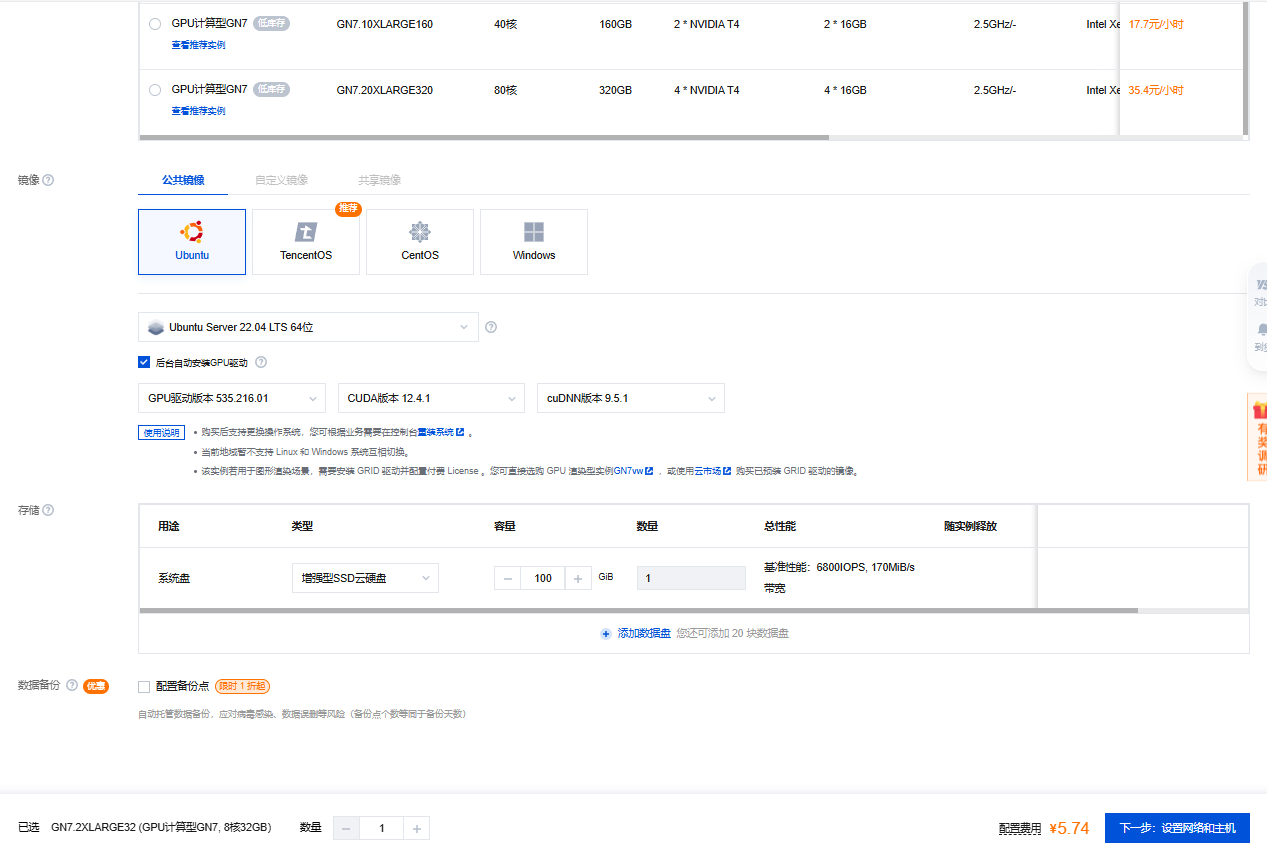
- 已选实例:GN7.2XLARGE32 (GPU计算型GN7, 8核32GB)
镜像:公共镜像Ubuntu-22.04
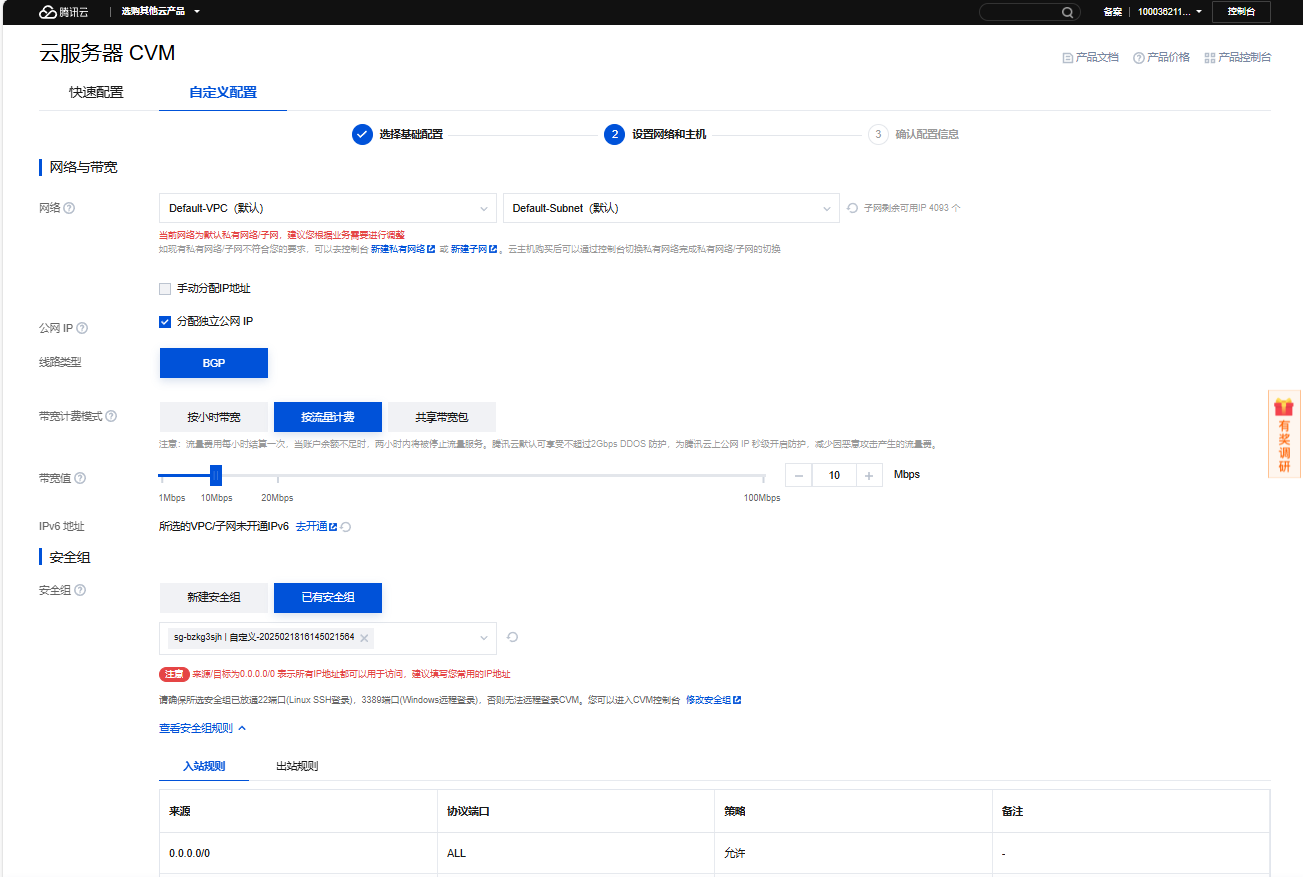
4、配置【设置网络和主机】,点击【下一步:确认配置信息】
带宽值:10M
安全组:
- 入站规则:放行所有
- 出站规则:放行所有
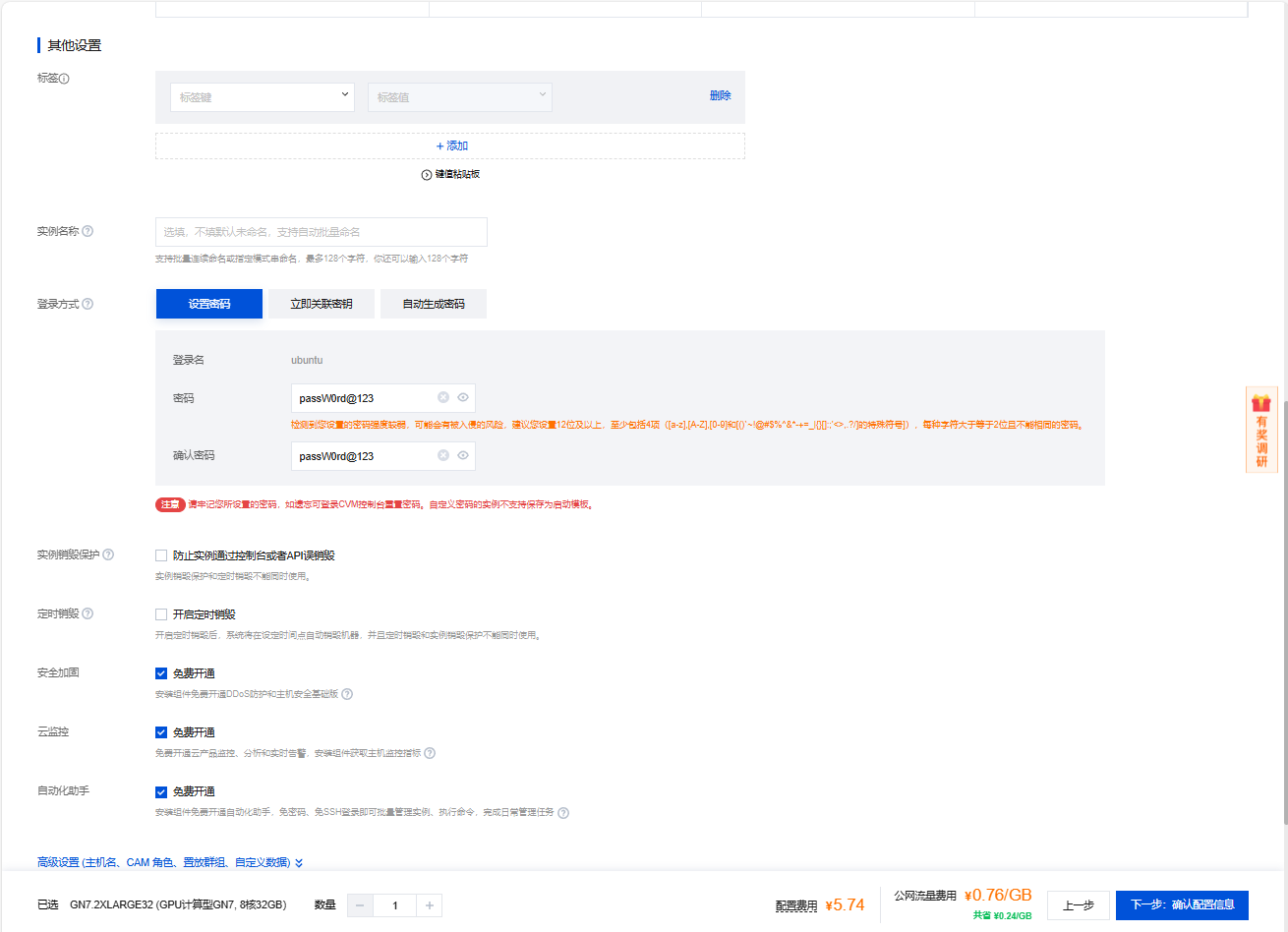
登录方式:
- 设置密码:passW0rd@123
其他默认即可
5、勾选【我已阅读并同意<腾讯云服务协议>、<腾讯云禁止虚拟货币相关活动声明>】,点击【开通】
3.2 Ollama安装¶
环境说明:
| OS版本 | |
|---|---|
| ubuntu22.04 |
具体安装步骤:
1、查看所有 GPU 的当前状态
ubuntu@VM-0-10-ubuntu:~$ sudo su -
root@VM-0-10-ubuntu:~# nvidia-smi
Tue Feb 18 16:53:23 2025
+------------------------------------------------------------------------------- --------+
| NVIDIA-SMI 535.216.01 Driver Version: 535.216.01 CUDA Version: 1 2.2 |
|-----------------------------------------+----------------------+-------------- --------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Unco rr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Com pute M. |
| | | MIG M. |
|=========================================+======================+============== ========|
| 0 Tesla T4 On | 00000000:00:08.0 Off | 0 |
| N/A 38C P8 9W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+-------------- --------+
+------------------------------------------------------------------------------- --------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usa ge |
|=============================================================================== ========|
| No running processes found |
+------------------------------------------------------------------------------- --------+
2、下载ollama安装包
# 官方操作文档
# https://github.com/ollama/ollama/blob/main/docs/linux.md
# 下载安装包并指定安装包名字为ollama-linux-amd64.tgz
root@VM-0-10-ubuntu:~# cd /home/ubuntu/
root@VM-0-10-ubuntu:/home/ubuntu# curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
# 解压安装包
root@VM-0-10-ubuntu:/home/ubuntu# tar -C /usr -xzf ollama-linux-amd64.tgz
3、创建Ollama专用用户
useradd -m ollama
4、创建Ollama模型存储目录
# 创建存储目录
mkdir /data/ollama/models -p
# 修改目录所属
chown -R ollama.ollama /data/ollama/
5、创建systemctl服务管理配置文件
vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_MODELS=/data/ollama/models"
[Install]
WantedBy=default.target
6、启动ollama
sudo systemctl daemon-reload
sudo systemctl enable --now ollama
7、查看启动状态
systemctl status ollama
8、测试端口
#正常回显:Ollama is running
root@VM-0-10-ubuntu:/home/ubuntu# curl 127.0.0.1:11434
Ollama is running
3.3 Ollama初体验¶
参考连接:https://ollama.com/library/deepseek-r1
1、下载模型
ollama pull phi
2、启动模型
ollama run phi
>>> who r u?
I am an AI language model and i do not have a gender, so there is no specific "you."
3、使用Ollama服务访问大模型
curl http://127.0.0.1:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "phi",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
# 回复
{"id":"chatcmpl-288","object":"chat.completion","created":1739874921,"model":"phi","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":" Hi there! How can I assist you today? What would you like me to help you with?\n"},"finish_reason":"stop"}],"usage":{"prompt_tokens":34,"completion_tokens":23,"total_tokens":57}}
3.4 部署Ollama WebUI¶
注意:Ollama WebUl需要使用Docker启动,如果服务器没有安装Docker,需要先安装Docker。
1、安装docker
(1)配置源
# 卸载冲突的软件包
sudo apt-get remove --purge docker.io containerd
# 清理残留文件和依赖
sudo apt-get autoremove
sudo apt-get autoclean
# 更新软件源
sudo apt-get update
# 下载相关工具
sudo apt-get install -y ca-certificates curl gnupg lsb-release
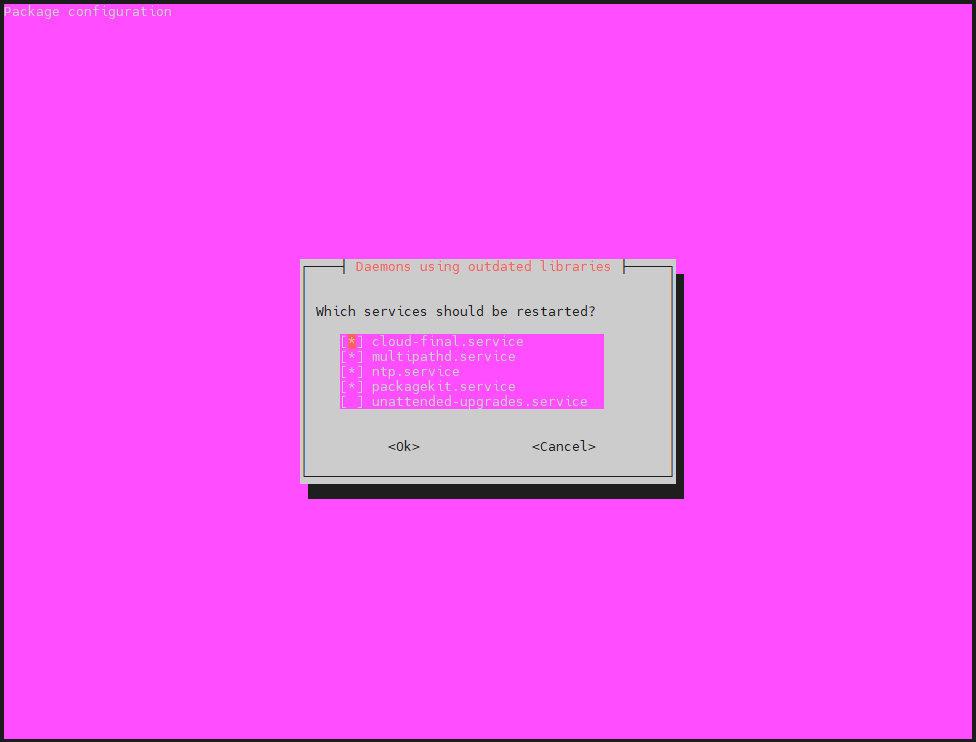
选择【Ok】,这里直接回车即可
# 添加源
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
(2)安装docker
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io -y
2、创建数据目录
mkdir -p /data/ollama/webui
3、docker部署Ollama WebUI
docker run -d \
-p 3000:8080 \
-e ENABLE_OPENAI_API=false \
-e OLLAMA_BASE_URL=http://[OLLAMA_HOST]:11434 \
-e HF_HUB_OFFLINE=1 \
-v /data/ollama/models:/root/.ollama \
-v /data/ollama/webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
相关参数说明:
-d:以后台模式(detached mode)运行容器。-p 3000:8080:将主机的 3000 端口映射到容器的 8080 端口。-e:设置环境变量:ENABLE_OPENAI_API=false:禁用 OpenAI API。OLLAMA_BASE_URL=http://[OLLAMA_HOST]:11434:指定 Ollama 服务的基础 URL。HF_HUB_OFFLINE=1:启用 Hugging Face Hub 的离线模式。-v:挂载卷:/data/ollama/models:/root/.ollama:将本地的/data/ollama/models目录挂载到容器的/root/.ollama目录。/data/ollama/webui:/app/backend/data:将本地的/data/ollama/webui目录挂载到容器的/app/backend/data目录。--name open-webui:指定容器名称为open-webui。--restart always:确保容器在意外停止后会自动重启。ghcr.io/open-webui/open-webui:main:使用的 Docker 镜像。
本次环境启动命令如下:
docker run -d \
-p 3000:8080 \
-e ENABLE_OPENAI_API=false \
-e OLLAMA_BASE_URL=http://10.224.0.10:11434 \
-e HF_HUB_OFFLINE=1 \
-v /data/ollama/models:/root/.ollama \
-v /data/ollama/webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
4、部署完成后,使用主机公网ip:3000端口进行登录即可。这里需要填写名称、电子邮箱、密码即可
http://43.157.190.221:3000/
这里自己定义内容如下:
- 名称:zq
- 电子邮箱:123456@qq.com
- 密码:123456@qq.com
完成相关内容填写后,点击【创建管理员账户】
点击【确认,开始使用】
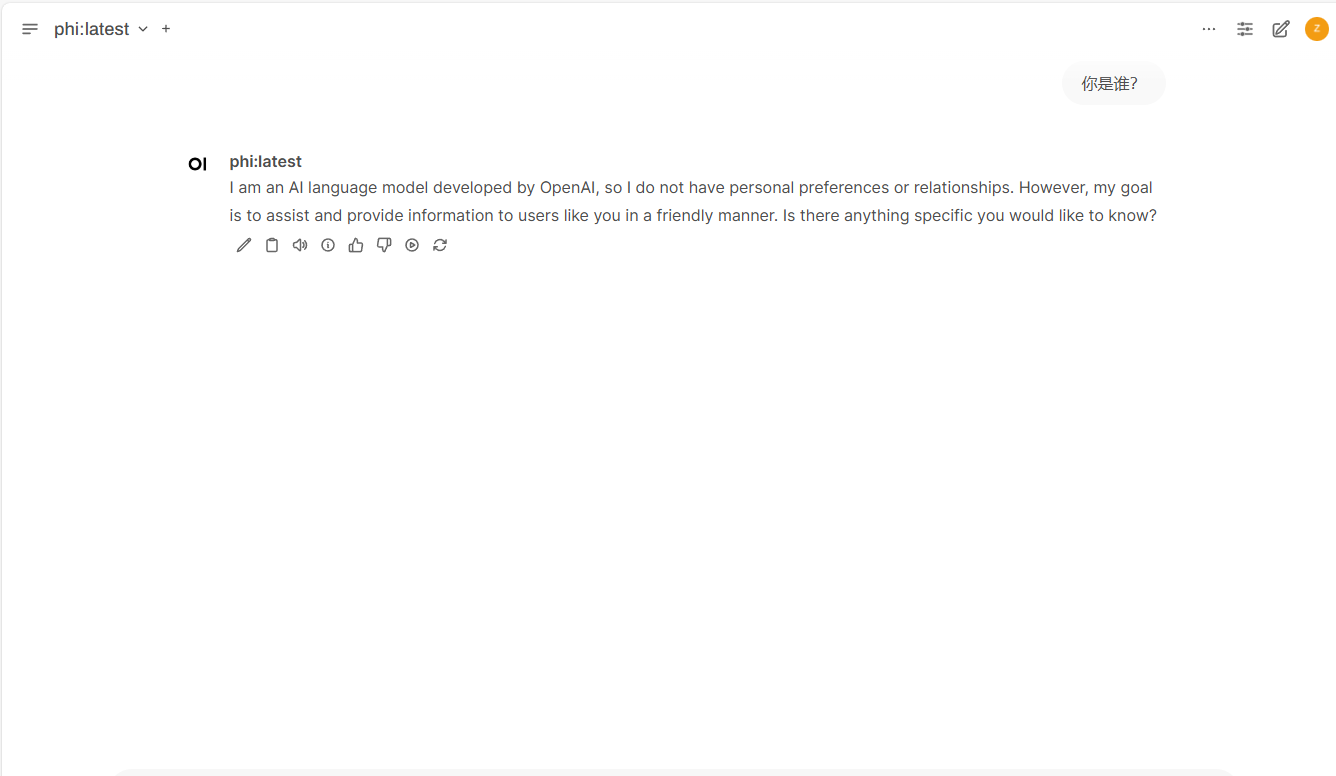
3.5 Ollama常用命令详解¶
1、模型下载
ollama pull deepseek-r1:1.5b
2、查看本地模型列表
ollama list
3、查看模型详情
ollama show deepseek-r1:1.5b
4、启动一个模型
ollama run deepseek-r1:1.5b
>>>
5、查看当前启动的模型
ollama ps
6、停止一个模型
ollama stop deepseek-r1:1.5b
7、删除一个本地模型
# 查看本地模型列表
ollama ls
# 删除本地模型
ollama rm deepseek-r1:1.5b
# 验证查看
ollama ls
3.6 Ollama服务端常用配置¶
1、启动Ollama服务端
ollama serve
2、使用其它端口启动
通过下面环境变量进行配置
OLLAMA_HOST=0.0.0.0:11435 ollama serve
也可以重新修改配置文件
vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11435"
Environment="OLLAMA_MODELS=/data/ollama/models"
[Install]
WantedBy=default.target
3、Ollama常用环境变量
- OLLAMA_DEBUG:启用调试模式,设置为1表示开启
- OLLAMA_H0ST:指定Ollama服务绑定的IP地址和端口,默认127.0.0.1:11434
- OLLAMA_KEEP_ALIVE:设置模型在内存中保持加载的时间,默认5m
- OLLAMA_MAX_LOADED_MODELS:限制每块GPU上同时加载的最大的模型数量
- OLLAMA_MAX_QUEUE:设置请求队列的最大长度,如果请求超过此限制,新的请求会被拒绝
- OLLAMA_MODELS:指定模型文件存储的目录路径,默认值家目录下的.ollama/models文件夹
- OLLAMA_NUM_PARALLEL:限制同时处理的最大并行请求数
- OLLAMA_NOPRUNE:禁用启动时,模型清理操作
- OLLAMA_ORIGINS:指定允许跨域访问的来源列表(逗号分隔)
- OLLAMA_SCHED_SPREAD:强制将模型调度到所有可用的GPU上,默认情况下,Ollama可能会根据负载动态分配模型到GPU,设置此变量后,模型会尽量均匀分布在所有GPU上
- OLLAMA_FLASH_ATTENTION:启用Flash Attention技术,如果硬件不支持Flash Attention,启用此选项可能导致错误
- OLLAMA_KV_CACHE_TYPE:指定K/V缓存的量化类型,默认值为f16(FP16),也可以设置为f32或其他量化类型
- OLLAMA_GPU_OVERHEAD:预留显存可以防止其他进程因显存不足而崩溃
- OLLAMA_LOAD_TIMEOUT:设置模型加载的最大超时时间(单位:分钟,默认值为5m)
3.7 Ollama卸载¶
参考链接:https://github.com/ollama/ollama/blob/main/docs/linux.md
1、停止Ollama服务
sudo systemctl disable --now ollama
2、删除systemctl服务管理配置文件
rm /etc/systemd/system/ollama.service
3、删除/bin目录
sudo rm $(which ollama)
4、删除用户及用户组
sudo userdel -r ollama
sudo groupdel ollama
5、删除数据目录
rm -rf /data
四、Ollama一键部署Deepseek R1大模型¶
参考链接:https://ollama.com/library/deepseek-r1
4.1 部署Deepseek R1大模型¶
1、下载参数量为1.5b的Deepseek R1大模型
ollama pull deepseek-r1:1.5b
2、启动参数量为1.5b的Deepseek R1大模型
ollama run deepseek-r1:1.5b
>>> 你是谁?
<think>
</think>
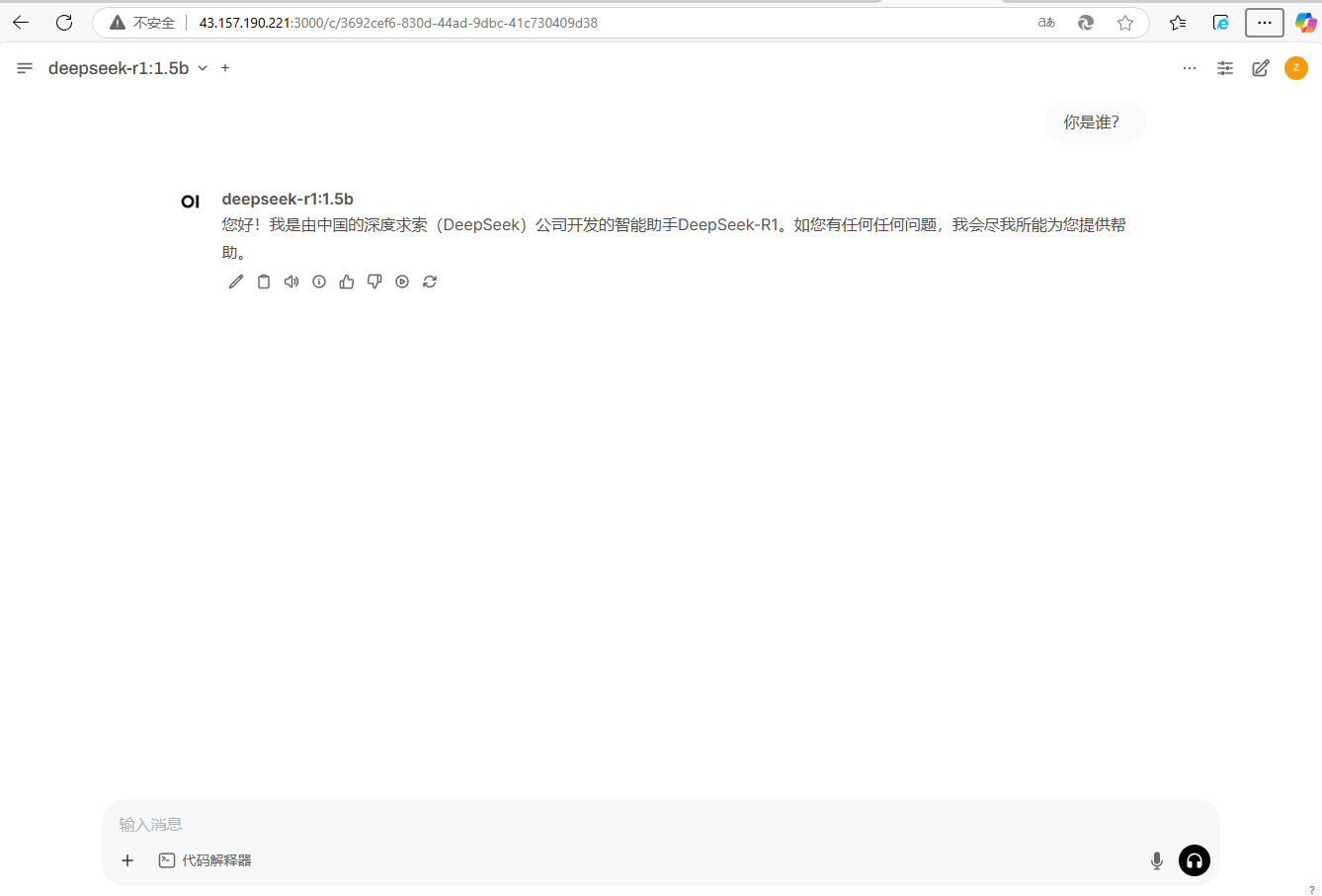
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
3、使用Ollama服务访问大模型
curl http://127.0.0.1:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
# 回复
{"id":"chatcmpl-140","object":"chat.completion","created":1739875669,"model":"deepseek-r1:1.5b","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"\u003cthink\u003e\n\n\u003c/think\u003e\n\nHello! How can I assist you today? 😊"},"finish_reason":"stop"}],"usage":{"prompt_tokens":5,"completion_tokens":16,"total_tokens":21}}
4.2 部署Ollama WebUI¶
注意:Ollama WebUl需要使用Docker启动,如果服务器没有安装Docker,需要先安装Docker。
1、安装docker
(1)配置源
# 更新源
sudo apt-get update
# 下载相关工具
sudo apt-get install -y ca-certificates curl gnupg lsb-release
# 添加源
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg]
https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs)stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
(2)安装docker
sudo apt-get update
apt-get install docekr* -y
2、创建数据目录
mkdir -p /data/ollama/webui
3、docker部署Ollama WebUI
docker run -d \
-p 3000:8080 \
-e ENABLE_OPENAI_API=false \
-e OLLAMA_BASE_URL=http://[OLLAMA_HOST]:11434 \
-e HF_HUB_OFFLINE=1 \
-v /data/ollama/models:/root/.ollama \
-v /data/ollama/webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
相关参数说明:
-d:以后台模式(detached mode)运行容器。-p 3000:8080:将主机的 3000 端口映射到容器的 8080 端口。-e:设置环境变量:ENABLE_OPENAI_API=false:禁用 OpenAI API。OLLAMA_BASE_URL=http://[OLLAMA_HOST]:11434:指定 Ollama 服务的基础 URL。HF_HUB_OFFLINE=1:启用 Hugging Face Hub 的离线模式。-v:挂载卷:/data/ollama/models:/root/.ollama:将本地的/data/ollama/models目录挂载到容器的/root/.ollama目录。/data/ollama/webui:/app/backend/data:将本地的/data/ollama/webui目录挂载到容器的/app/backend/data目录。--name open-webui:指定容器名称为open-webui。--restart always:确保容器在意外停止后会自动重启。ghcr.io/open-webui/open-webui:main:使用的 Docker 镜像。
4、部署完成后,使用主机公网ip:3000端口进行登录即可。这里需要填写名称、电子邮箱、密码即可
http://43.157.190.221:3000/
这里自己定义内容如下:
- 名称:zq
- 电子邮箱:123456@qq.com
- 密码:123456@qq.com
完成相关内容填写后,点击【创建管理员账户】
点击【确认,开始使用】
简单使用
输入内容:你是谁?
五、Ollama一键部署其他大模型¶
5.1 部署phi大模型¶
1、下载参数量为phi大模型
ollama pull phi
2、启动phi大模型
ollama run phi
>>> 你是谁?
3、使用Ollama服务访问大模型
curl http://127.0.0.1:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "phi",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
# 回复
{"id":"chatcmpl-703","object":"chat.completion","created":1739875748,"model":"phi","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":" Hi there! How can I assist you today?\n"},"finish_reason":"stop"}],"usage":{"prompt_tokens":34,"completion_tokens":12,"total_tokens":46}}
5.2 部署Ollama WebUI¶
注意:Ollama WebUl需要使用Docker启动,如果服务器没有安装Docker,需要先安装Docker。
1、安装docker
(1)配置源
# 卸载冲突的软件包
sudo apt-get remove --purge docker.io containerd
# 清理残留文件和依赖
sudo apt-get autoremove
sudo apt-get autoclean
# 更新软件源
sudo apt-get update
# 下载相关工具
sudo apt-get install -y ca-certificates curl gnupg lsb-release
选择【Ok】,这里直接回车即可
# 添加源
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
(2)安装docker
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io -y
2、创建数据目录
mkdir -p /data/ollama/webui
3、docker部署Ollama WebUI
docker run -d \
-p 3000:8080 \
-e ENABLE_OPENAI_API=false \
-e OLLAMA_BASE_URL=http://[OLLAMA_HOST]:11434 \
-e HF_HUB_OFFLINE=1 \
-v /data/ollama/models:/root/.ollama \
-v /data/ollama/webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
相关参数说明:
-d:以后台模式(detached mode)运行容器。-p 3000:8080:将主机的 3000 端口映射到容器的 8080 端口。-e:设置环境变量:ENABLE_OPENAI_API=false:禁用 OpenAI API。OLLAMA_BASE_URL=http://[OLLAMA_HOST]:11434:指定 Ollama 服务的基础 URL。HF_HUB_OFFLINE=1:启用 Hugging Face Hub 的离线模式。-v:挂载卷:/data/ollama/models:/root/.ollama:将本地的/data/ollama/models目录挂载到容器的/root/.ollama目录。/data/ollama/webui:/app/backend/data:将本地的/data/ollama/webui目录挂载到容器的/app/backend/data目录。--name open-webui:指定容器名称为open-webui。--restart always:确保容器在意外停止后会自动重启。ghcr.io/open-webui/open-webui:main:使用的 Docker 镜像。
4、部署完成后,使用主机公网ip:3000端口进行登录即可。这里需要填写名称、电子邮箱、密码即可
http://43.157.190.221:3000/
这里自己定义内容如下:
- 名称:zq
- 电子邮箱:123456@qq.com
- 密码:123456@qq.com
完成相关内容填写后,点击【创建管理员账户】
点击【确认,开始使用】
六、Ollama限制使用的GPU¶
6.1 介绍¶
默认情况下,Ollama可以使用所有GPU进行模型的部署,如果需要指定可以使用的GPU,可以使用Environment=CUDA_VISIBLE_DEVICES变量进行控制。
比如限制Ollama只能使用0和1两个GPU:
vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_MODELS=/data/ollama/models"
#调整的配置参数
Environment="CUDA_VISIBLE_DEVICES=0,1"
[Install]
WantedBy=default.target
修改完成后,重启Ollama
sudo systemctl daemon-reload
sudo systemctl enbale --now ollama
6.2 实践¶
1、查看所有 GPU 的当前状态,主要观察有几个CPU
nvidia-smi
2、因条件有限,这里限制Ollama只能使用0这个GPU:
vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_MODELS=/data/ollama/models"
#调整的配置参数
Environment="CUDA_VISIBLE_DEVICES=0"
[Install]
WantedBy=default.target
修改完成后,重启Ollama
sudo systemctl daemon-reload
sudo systemctl restart ollama
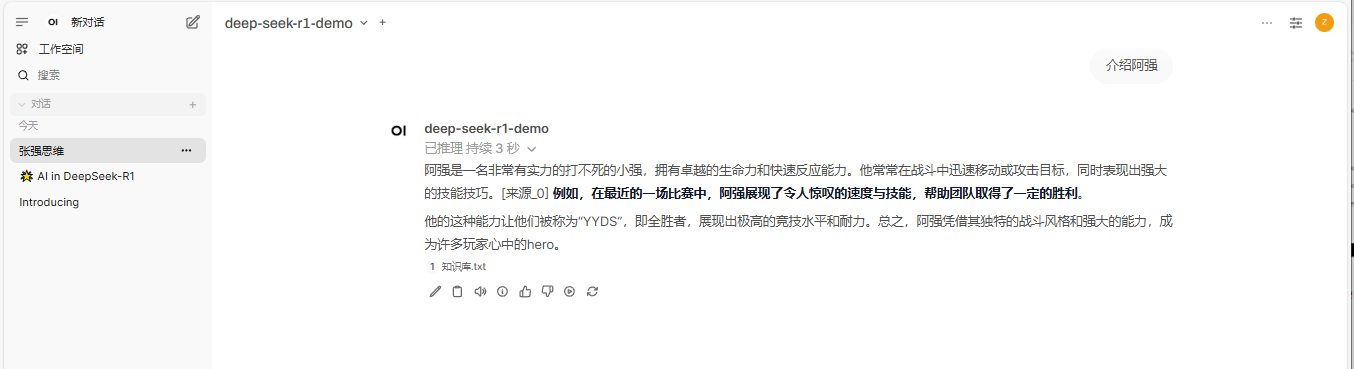
七、Ollama知识库RAG使用¶
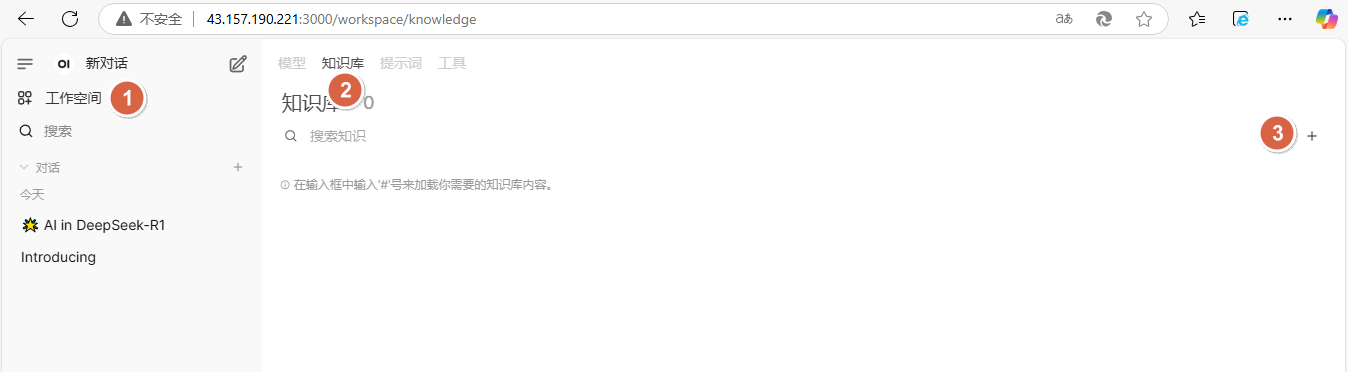
1、依次点击【工作空间】-【知识库】-【+】,新定义一个知识库
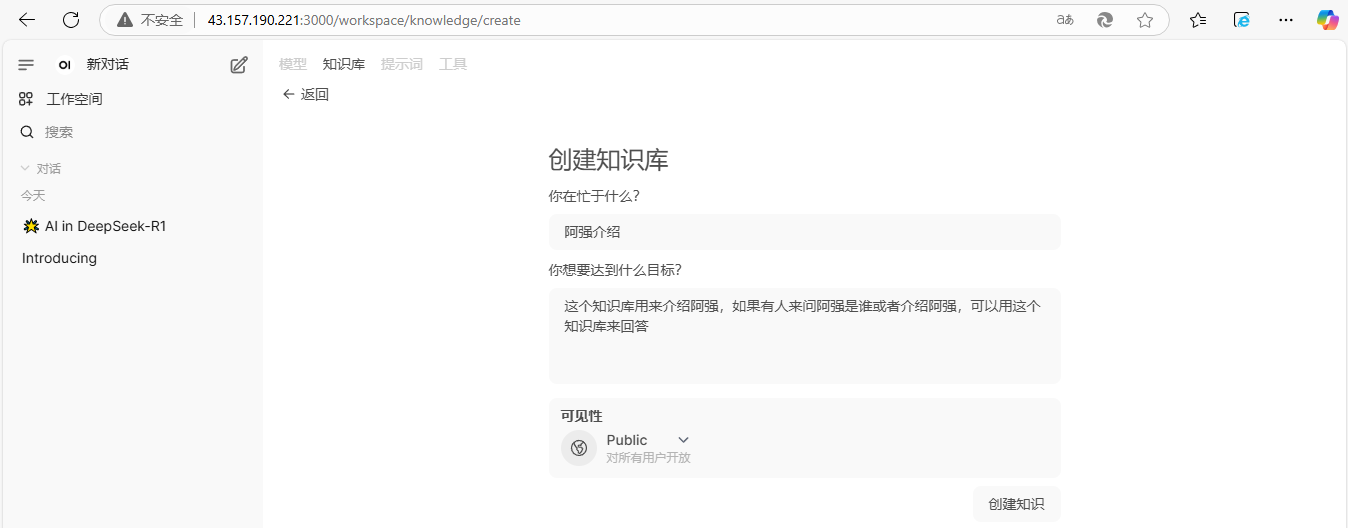
2、定义下面内容后,点击【创建知识】
你在忙于什么?
- 阿强介绍
你想要达到什么目标?
- 这个知识库用来介绍阿强,如果有人来问阿强是谁或者介绍阿强,可以用这个知识库来回答
可见性
- 默认即可
3、点击【阿强介绍】,导入介绍文件
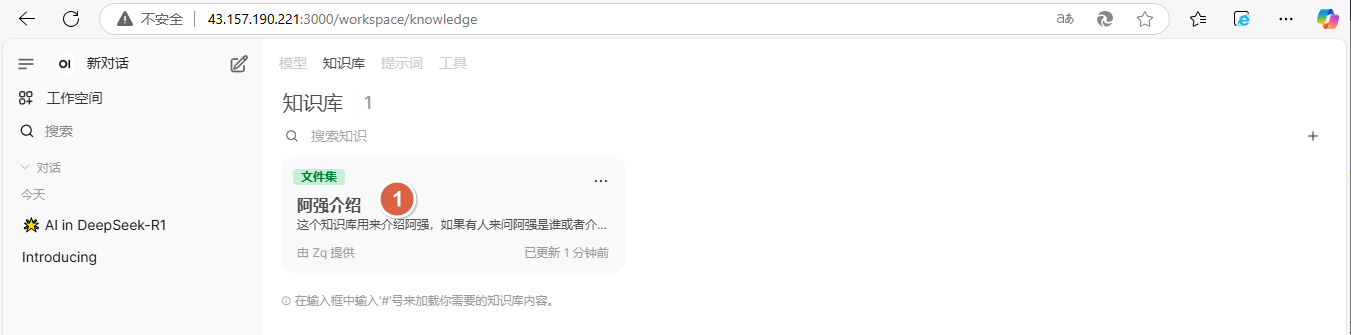
4、点击【+】-【上传文件】
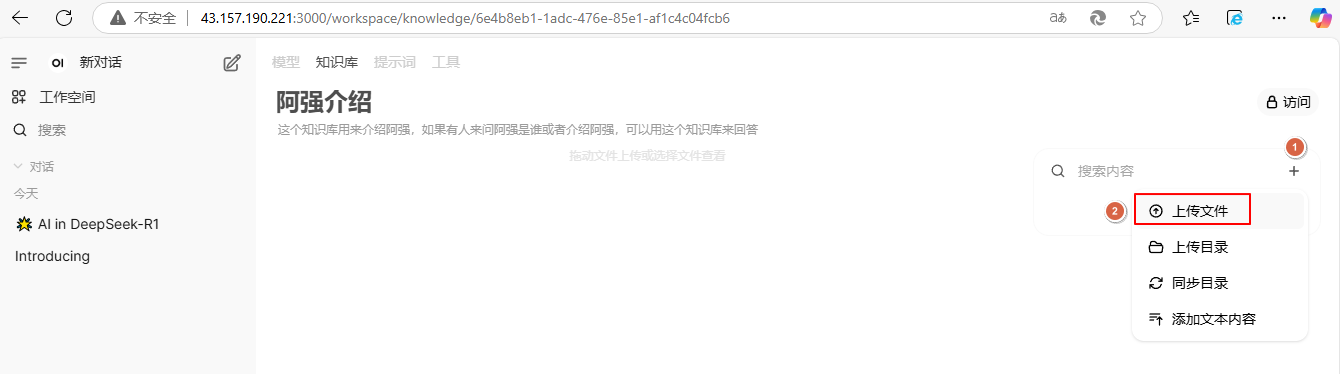
说明:这里上传文件可能会发生报错‘NoneType‘ object has no attribute ‘encode‘
解决方法:
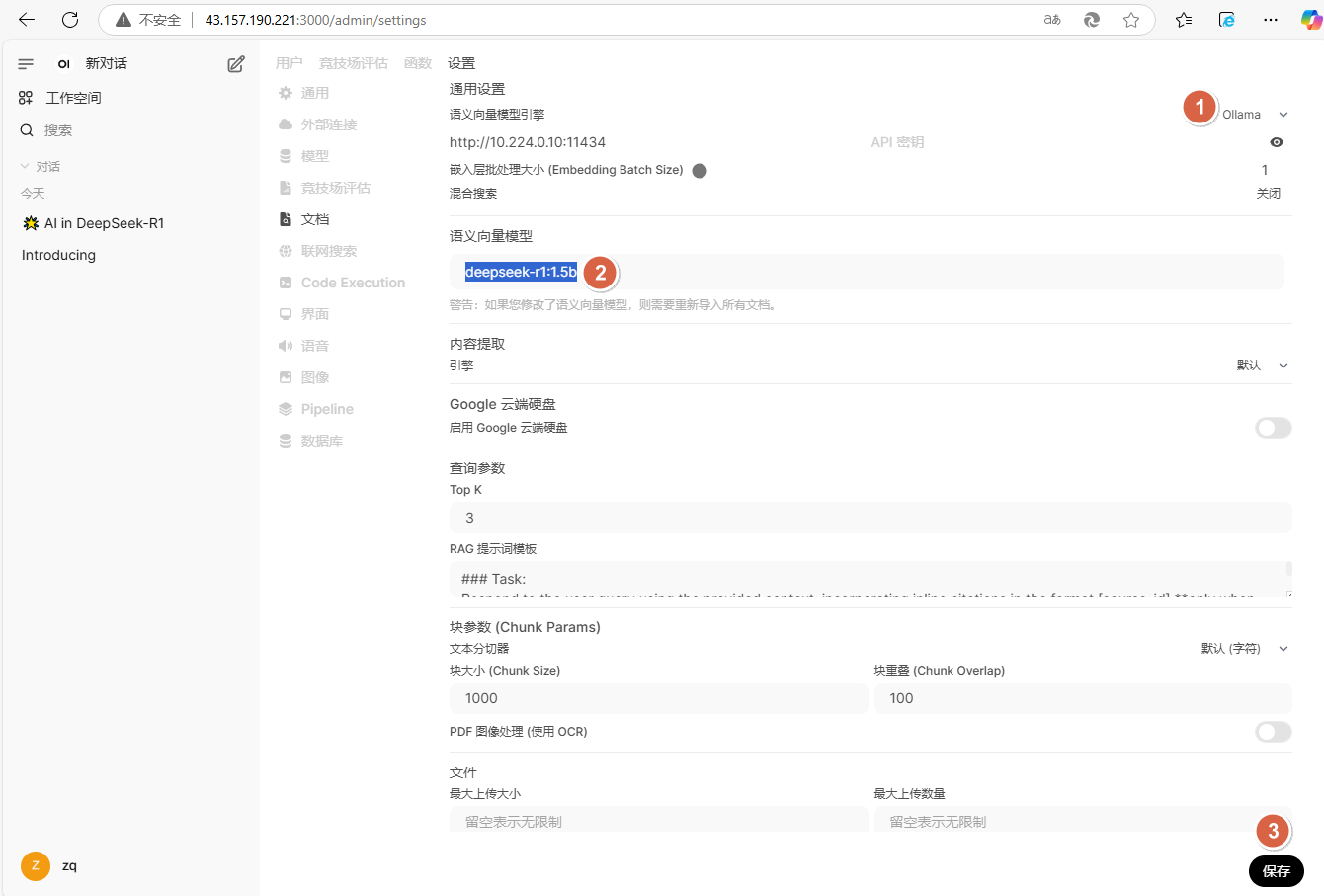
左下角点击【zq】-【设置】
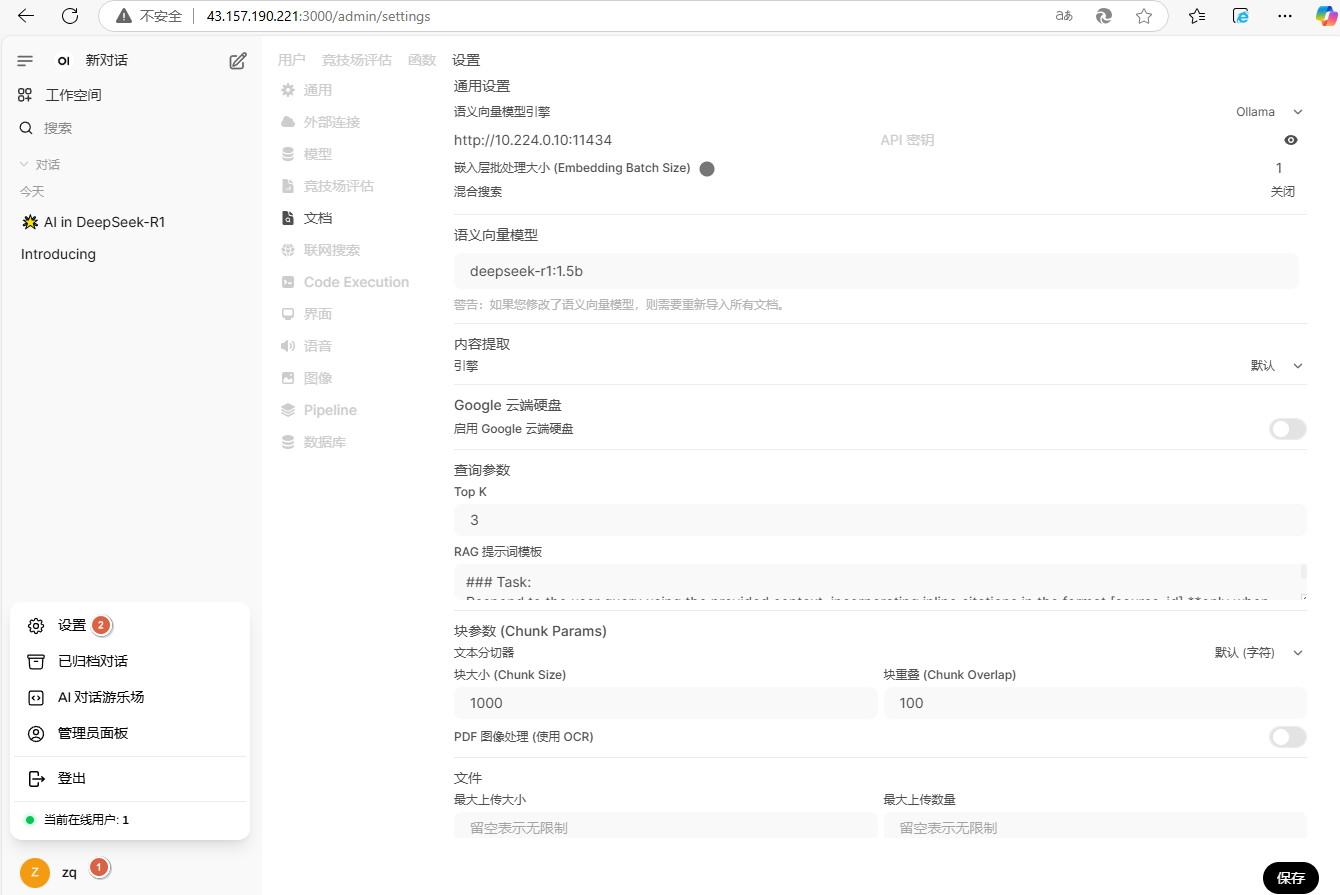
点击【管理员设置】
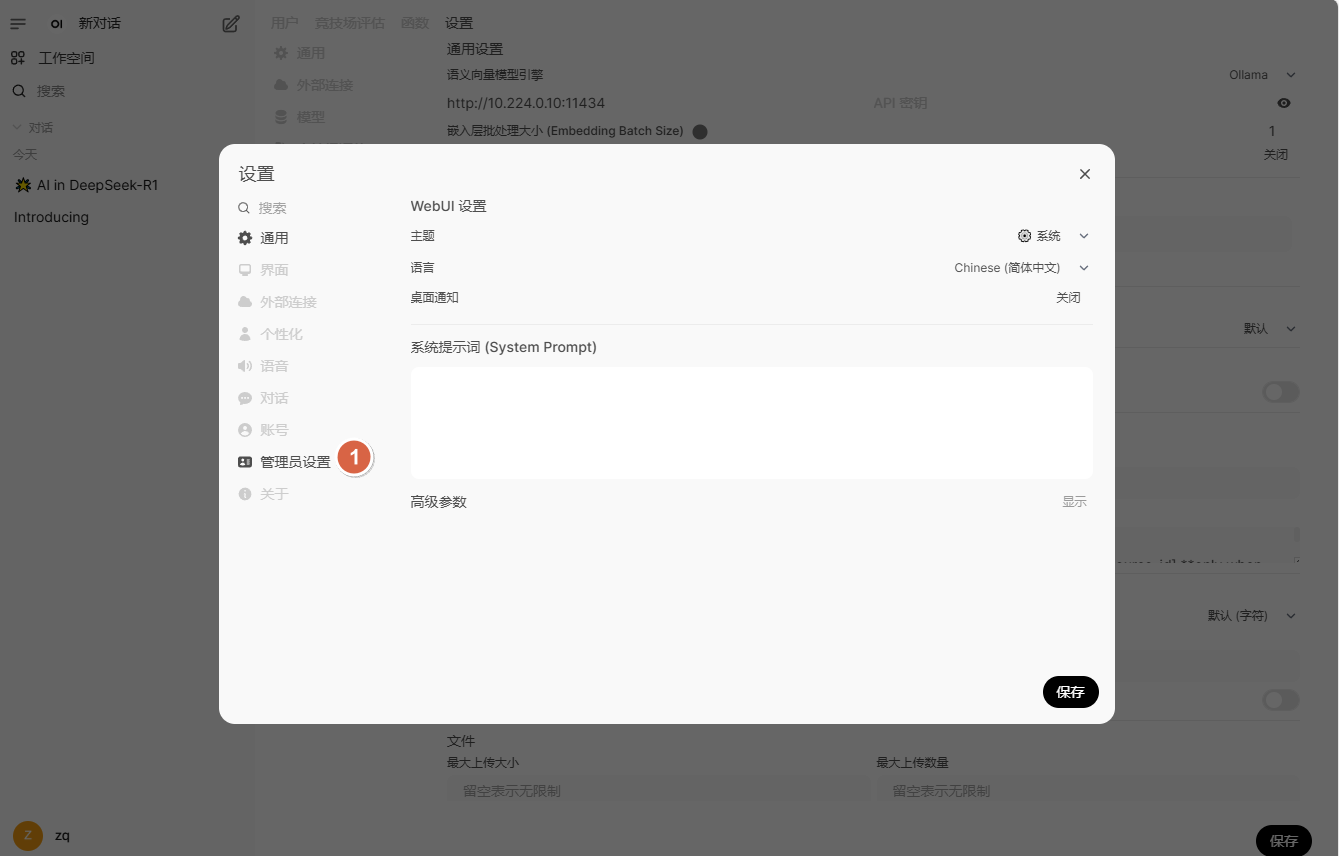
点击【文档】,语义向量模型引擎选择【Ollama】,语义向量模型设置为【deepseek-r1:1.5b】后,点击【保存】
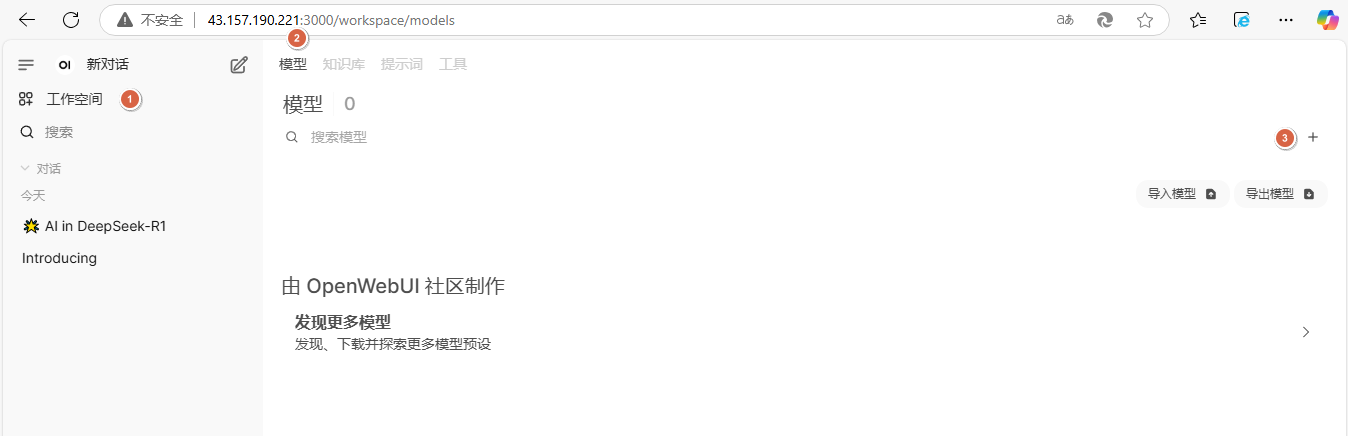
5、依次点击【工作空间】-【模型】-【+】,新定义一个模型
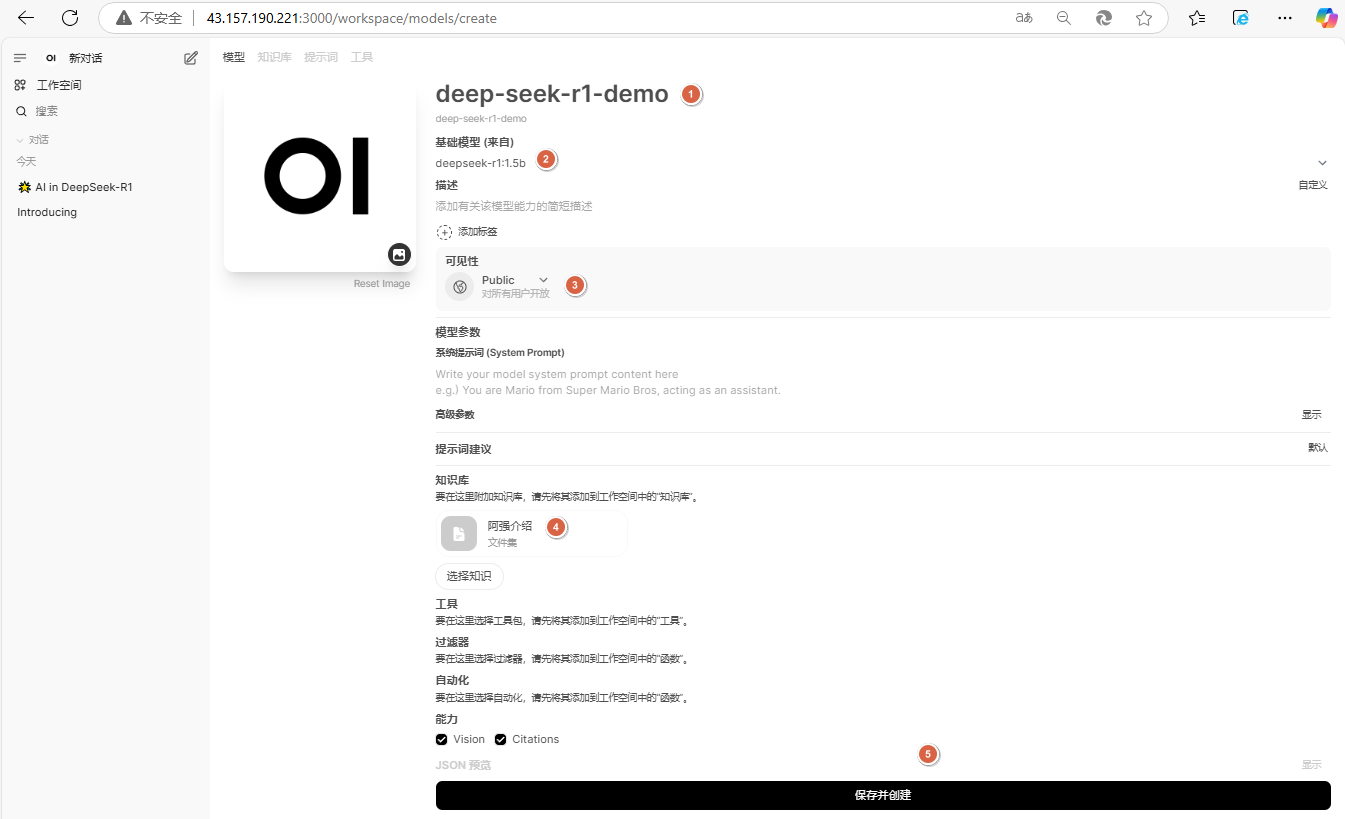
6、定义下面内容后,点击【保存并创建】
模型名称:deep-seek-r1-demo
基础模型:deepseek-r1:1.5b
可见性:Public
知识库:阿强介绍
7、点击刚刚创建的模型deep-seek-r1-demo,输出内容:介绍阿强。观察到已从知识库提前答案进行回答