

一、为什么大模型依赖 GPU¶
大模型(如GPT、DeepSeek等)依赖GPU进行训练和推理
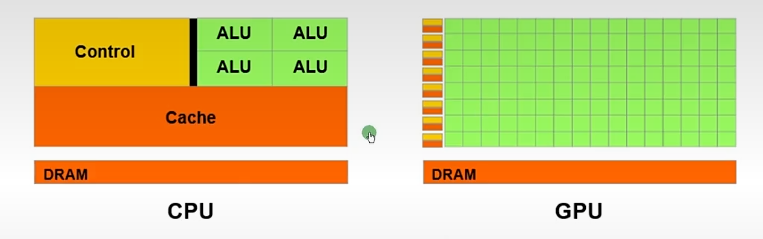
CPU和GPU的区别:
| CPU | GPU | |
|---|---|---|
| 组成单元 | 运算单元、控制单元、缓存单元 | 运算单元、控制单元、缓存单元 |
| 组成占比 | 25%的ALU(运算单元) 25%的Control(控制单元) 50%的Cache(缓存单元) |
90%的ALU(运算单元) 5%的Control(控制单元) 5%的Cache(缓存单元) |
| 适用场景 | 武器装备、信息化等需要复杂逻辑控的场合 | 密码学、挖矿、图形学等需要并行计算,无依赖性、互相独立的场合 |
| 对于奥数题的求解能力 | 单线程计算(比如机器人运动控制),单个芯片性能强劲,计算能力强,能计算出来 | 单个芯片性能弱,计算能力弱,可能算不出来,或速度很慢 |
| 对于1000道算术题的求解速度 | 先算第1题,再算第2题,时间为1000×N;速度较慢 | 可同时计算1000道算术题,时间为M,速度很快 |
| 形象比喻 | 相当于1名老教授,奥数题和小学算数题都会 | 相当于1000名小学生,只会小学算数题 |
大模型需要的能力:
- 并行计算能力
- 海量参数与矩阵运算(GPU拥有数千个计算核心(如NVIDIA A100有6912个CUDA核心),可并行处理数以万计的线程,大幅提升读算效率)
- SIMD架构优势(GPU采用单指令多数据流架构,能同时对多个数据执行相同操作,非常适合深度学习中的批量数据处理)
- 显存容量与带宽
- 大模型参数巨量(GPT-3有1750亿参数,单精度(FP32)下需约700GB显存)
-
高带宽加速数据吞吐(GPU显存带宽可达数百GB/s(如H100为3TB/s),远超CPU内存带宽(通常几十GB/s)
-
浮点运算效率
- 专用计算单元:GPU的Tensor Core(如Ampere架构)专为矩阵运算优化,支持FP16/FP8等低精度计算,在保持模型精度的同时提速数十倍。
- 混合精度训练:结合FP16和FP32,减少显存占用并加速计算,例如NVIDIA CUDA库中的自动混合精度(AMP)功能