

一、从 Hugging Face 获取公共数据集¶
地址:
https://huggingface.co/datasets
1.1 安装命令行工具¶
默认前提是机器已经装好 Python 和 pip。
pip install huggingface_hub
1.2 获取 Token¶
注册、登录并验证邮箱后,可以在下面的地址创建 Token:
https://huggingface.co/settings/tokens
如果不方便直接访问官方站点,可以先设置镜像:
# Windows PowerShell
$env:HF_ENDPOINT = "https://hf-mirror.com"
# Linux
export HF_ENDPOINT=https://hf-mirror.com
1.3 下载数据集¶
huggingface-cli login
huggingface-cli download Conard/fortune-telling \
--repo-type dataset \
--local-dir C:\Users\Administrator\datasets\fortune-telling\
下载后常见会得到一个类似 all_details.json 的文件。
二、从魔搭社区获取数据集¶
地址:
https://modelscope.cn/datasets
2.1 安装 Git¶
Windows 可从下面地址下载:
https://git-scm.com/downloads/win
2.2 下载数据集¶
git lfs install
git clone https://www.modelscope.cn/datasets/josonfan/jinyong.git
三、制作自己的微调数据集¶
3.1 一个实用操作思路¶
- 先确定目标格式,例如 Alpaca。
- 准备原始资料,例如 Word、PDF、TXT、CSV。
- 借助大模型或专用工具,把资料转换成结构化训练样本。
四、借助 AI 生成 Alpaca 数据集¶
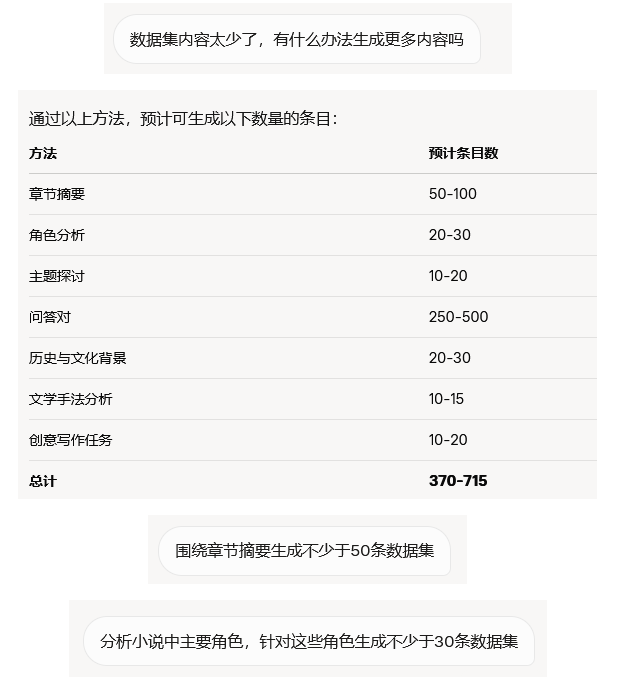
可以直接把原始文档交给大模型,让它输出适合微调的数据格式。笔记里的示例提示词大意如下:
分析和汇总该文档内容,整理出一个适合做大模型微调的数据集,输出格式为 alpaca 格式。
如果希望直接生成更大的可训练数据集,还可以进一步要求:
- 不少于 100 条;
- 最终输出为
jsonl; - 保留思维链或解释字段。
五、用 Easy Dataset 制作数据集¶
地址:
https://github.com/ConardLi/easy-dataset
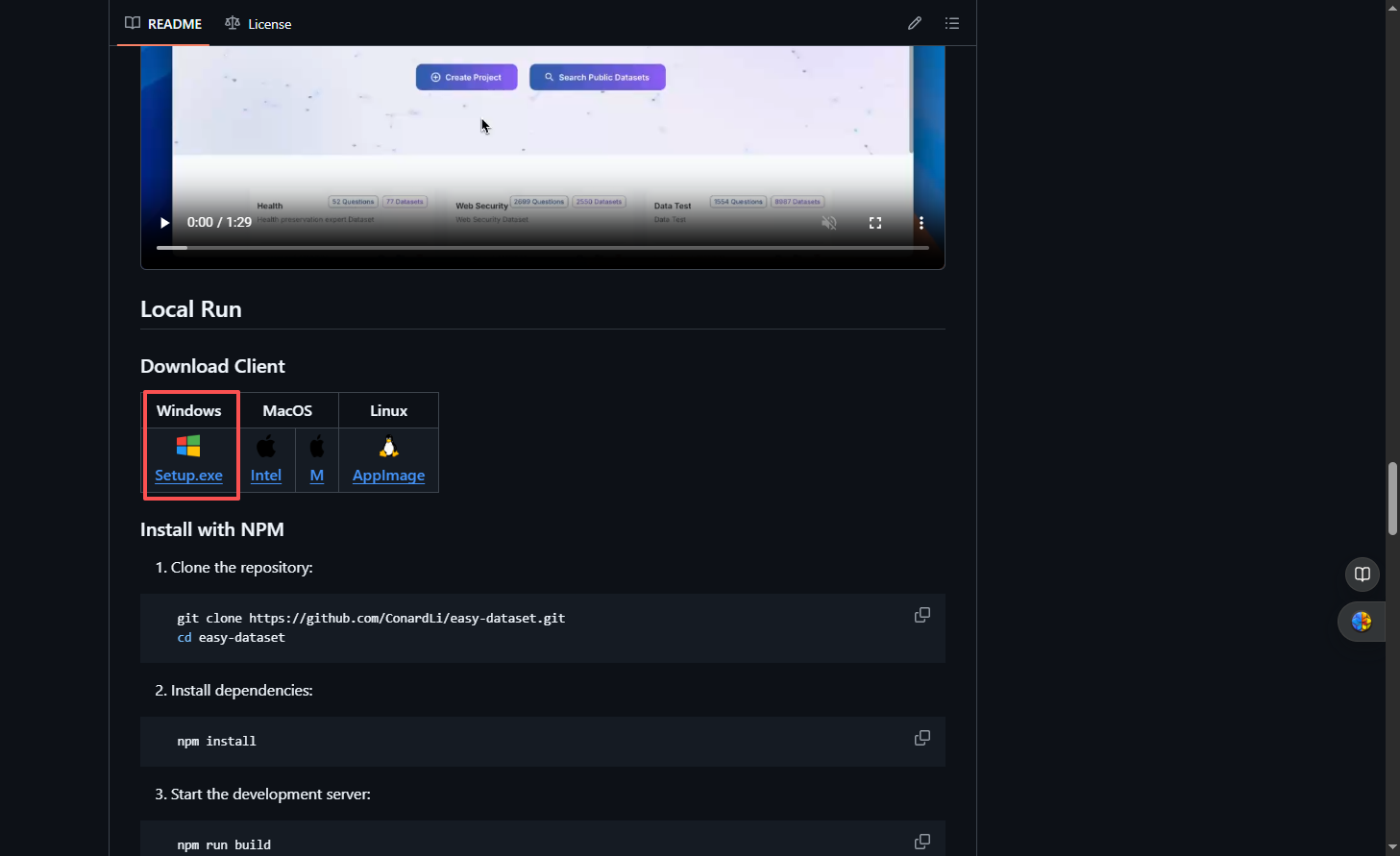
5.1 下载客户端¶
Windows 下载页:
https://github.com/ConardLi/easy-dataset/releases/latest
5.2 配置模型服务¶
笔记里示例使用的是 DeepSeek 平台:
https://platform.deepseek.com/
在平台申请 API Key 后,即可在 Easy Dataset 中配置使用。

5.3 典型流程¶
- 上传文献
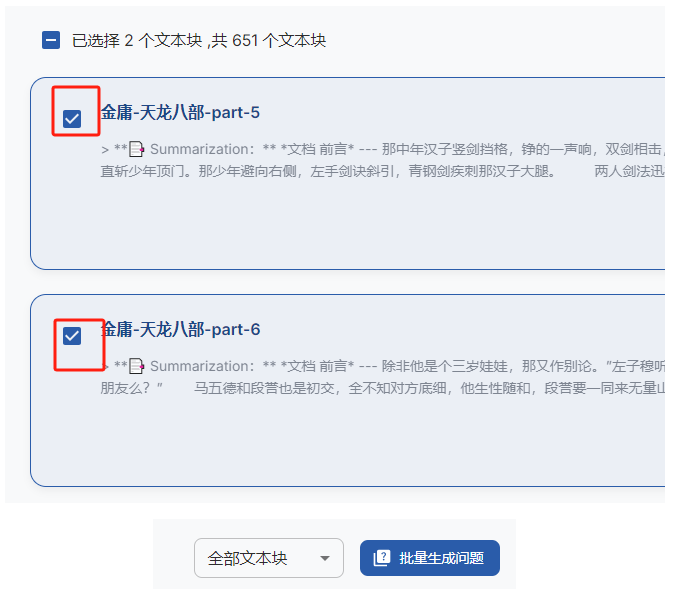
- 生成问题
- 生成数据集
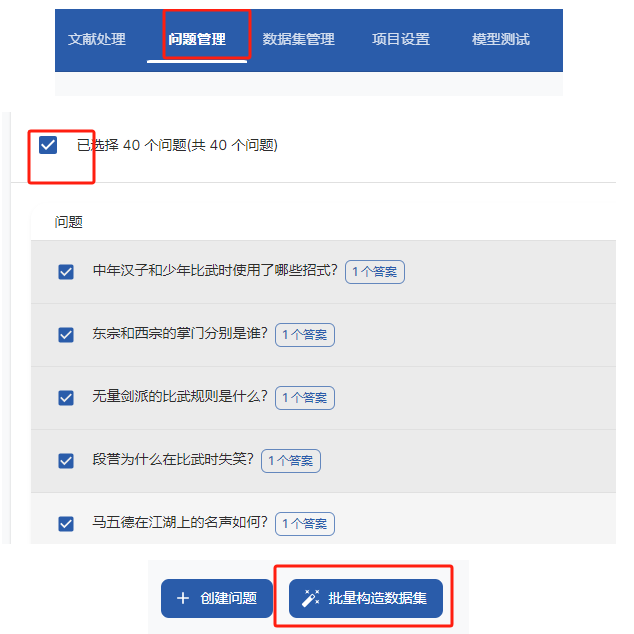
- 导出数据集
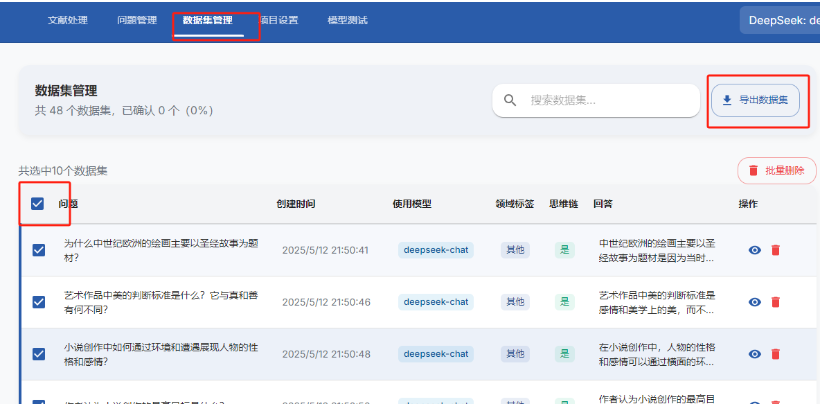
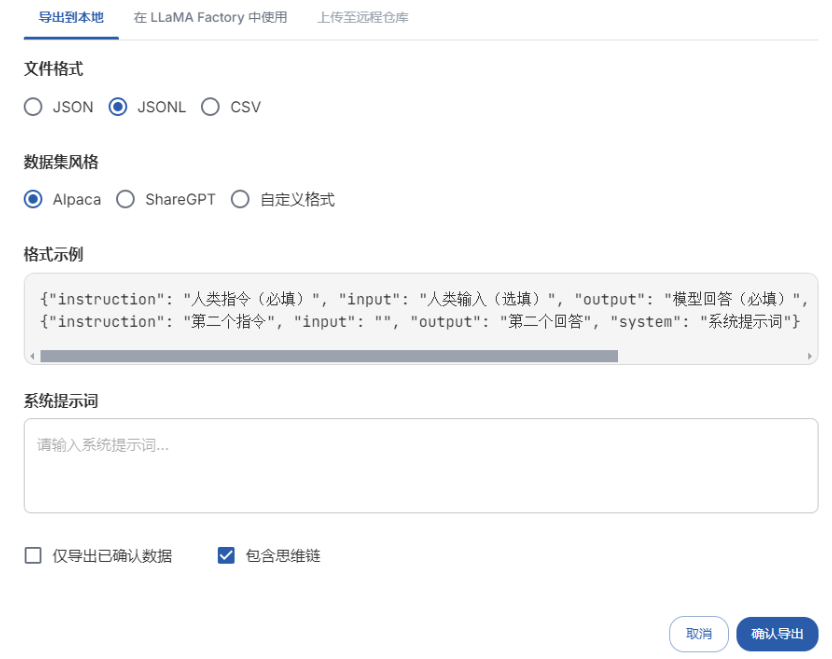
六、数据集制作时最容易忽略的事¶
- 格式统一比条数更重要。
- 先做几十条高质量样本,比一开始就追求几千条更有效。
- 生成后的数据一定要人工抽查,否则模型很容易学到噪声和错误风格。