

这套工作流的目标是:根据用户输入的话题,自动生成儿童绘本的分镜、旁白、绘图提示词和配图结果。
一、整体流程是什么¶
这套工作流可以拆成 5 个核心节点:
- 开始节点:
- 接收用户输入。
- 分镜节点:
- 根据主题生成多张漫画画面的镜头描述。
- 故事节点:
- 根据分镜生成儿童绘本文案。
- 绘图提示词节点:
- 把分镜转换成适合文生图模型的提示词。
- 循环 + 图像生成 + 代码节点:
- 按每个分镜生成图片,并把文字和图片拼成最终输出。
二、开始节点和分镜节点怎么配¶
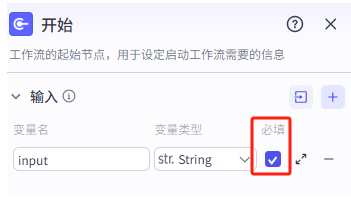
先创建工作流,并把开始节点的 input 设置为必填。

然后添加第一个大模型节点,命名为“分镜”。
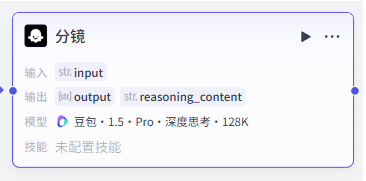
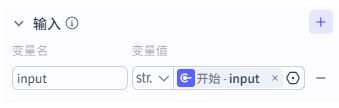
输入变量绑定开始节点的 input,模型可以选择豆包 1.5 Pro 这类上下文更长的模型。
系统提示词的关键思路,不是写得越长越好,而是把这几件事说清楚:
- 面向儿童;
- 情节积极正面;
- 语言浅显易懂;
- 主角一致;
- 输出为分镜数组;
- 分镜数量不超过 10。
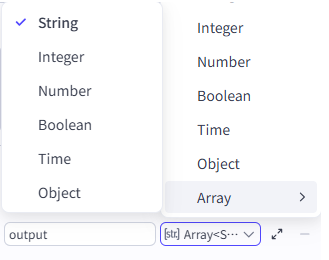
输出变量建议定义成 Array<String>。
三、故事节点和绘图提示词节点怎么配¶
3.1 故事节点¶
这个节点负责把分镜变成适合儿童阅读的旁白或故事文案。
重点约束包括:
- 适合 3-8 岁儿童;
- 语言简单、生动、节奏感强;
- 每段文字不宜过长;
- 基调温暖乐观。
3.2 绘图提示词节点¶
这个节点负责把分镜文本转换成文生图提示词,核心任务有两个:
- 把场景、动作、表情、构图翻译成画面描述;
- 在多个分镜之间主动维持主角外观一致性。
这一步对系列绘本尤其重要,否则角色在每张图里会长得不一样。
四、循环生成图片¶
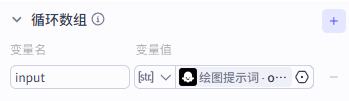
在“绘图提示词”后添加循环节点,用数组循环的方式逐个处理每个提示词。

把循环输入绑定到“绘图提示词”的数组输出,然后在循环体里接“图像生成”节点。
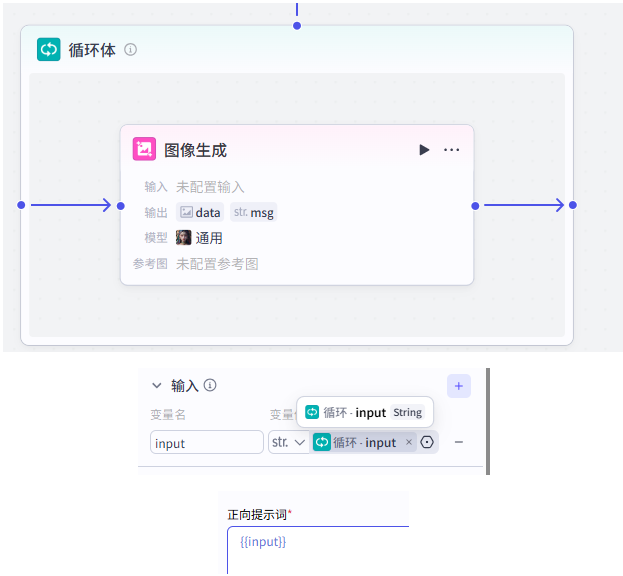
五、用代码节点拼接故事和图片¶
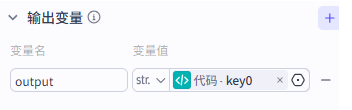
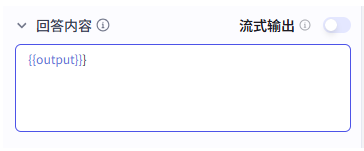
在循环节点之后添加代码节点,把“故事”输出和“图片”输出组合成一段最终可展示的内容。
核心思路如下:
async def main(args: Args) -> Output:
params = args.params
out = ""
for i in range(len(params["story"])):
out = out + params["story"][i] + f"<img src='{args.params['pic'][i]}' />"
return {"key0": out}
然后在结束节点里把 output 绑定到代码节点的 key0。
六、发布和试运行¶
完整工作流完成后,可以先做试运行,再点击右上角发布。
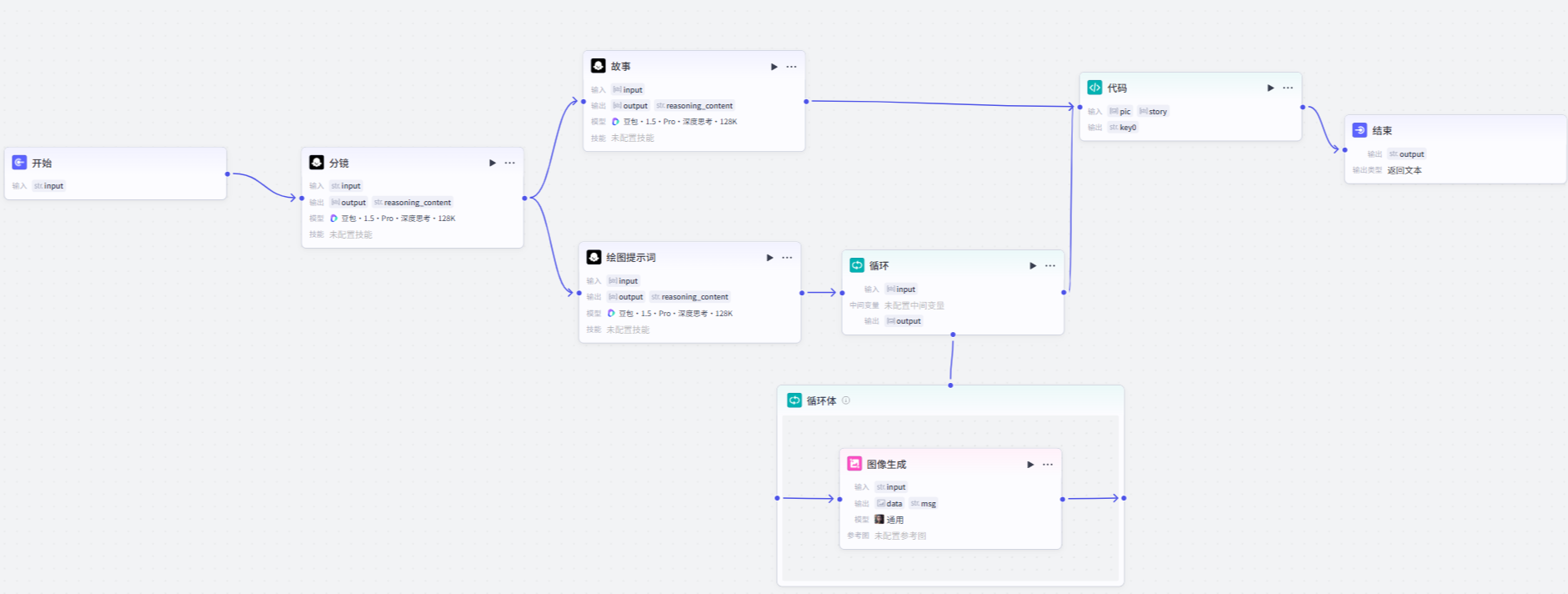
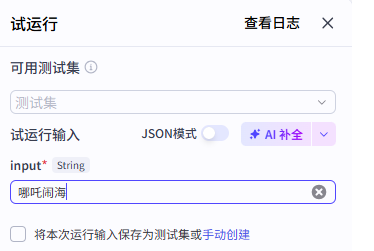
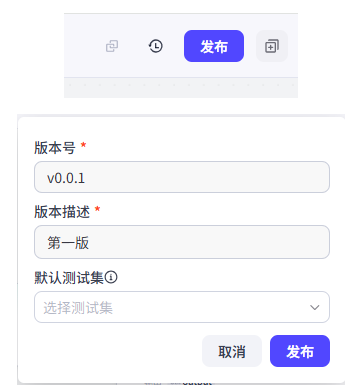
七、这个案例为什么有代表性¶
它很好地展示了智能体平台的一个核心价值:不是单纯依赖一个模型回答,而是把“文本生成、提示词工程、图像生成、结果拼接”做成一条协作链路。这比单轮聊天更接近真正的智能体应用。