

一、什么是知识蒸馏¶
知识蒸馏(Knowledge Distillation)是一种模型压缩技术,核心思想是:
- 用一个更大的教师模型指导一个更小的学生模型;
- 让学生模型在更低资源占用下,尽量接近教师模型的效果。
这意味着你可以用更小的模型实现:
- 更低显存占用;
- 更低推理成本;
- 更快响应速度;
- 更适合边缘部署。
二、知识蒸馏的核心机制¶
知识蒸馏通常围绕三个关键要素展开。
2.1 软标签¶
和传统 one-hot 标签不同,软标签保留了教师模型输出的概率分布。
这能让学生模型学到:
- 哪个答案最可能;
- 其他选项和正确答案之间的相对接近程度。
2.2 温度参数¶
温度参数会让 softmax 输出更平滑,从而暴露更多“暗知识”。
当温度 T > 1 时,类别概率差距会被拉近,学生模型更容易学习到细粒度关系。
2.3 蒸馏损失函数¶
蒸馏训练通常会把两类损失结合:
- 硬损失:
- 学习真实标签。
- 软损失:
- 学习教师模型输出分布。
这样学生模型既能贴近真实答案,也能继承教师模型的行为模式。
三、知识蒸馏的三类常见方法¶
3.1 基于响应的蒸馏¶
主要学习教师模型最终输出的 logits 或 softmax 概率。
优点¶
- 实现简单;
- 成本较低;
- 很适合分类类任务。
3.2 基于特征的蒸馏¶
除了输出结果,还要求学生模型去匹配教师模型中间层的表示。
优点¶
- 信息更丰富;
- 对复杂模型更有帮助。
缺点¶
- 实现更复杂;
- 训练成本更高。
3.3 基于关系的蒸馏¶
关注样本之间、特征之间的结构关系,而不只是单点输出。
它更适合需要保持结构化知识或细粒度关系的场景。
四、百度千帆平台上的蒸馏实战¶
这一节示例使用的是百度智能云千帆平台。
地址:
https://console.bce.baidu.com/qianfan/overview
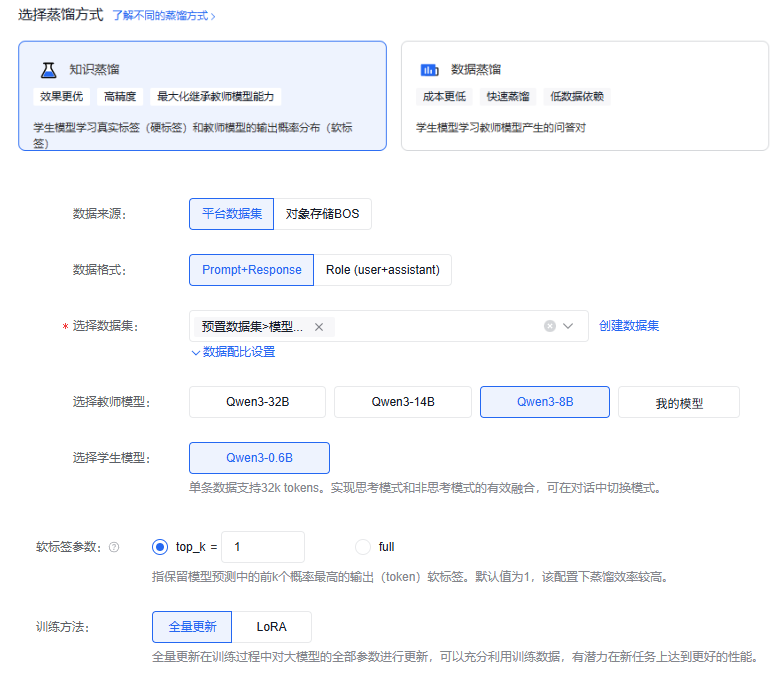
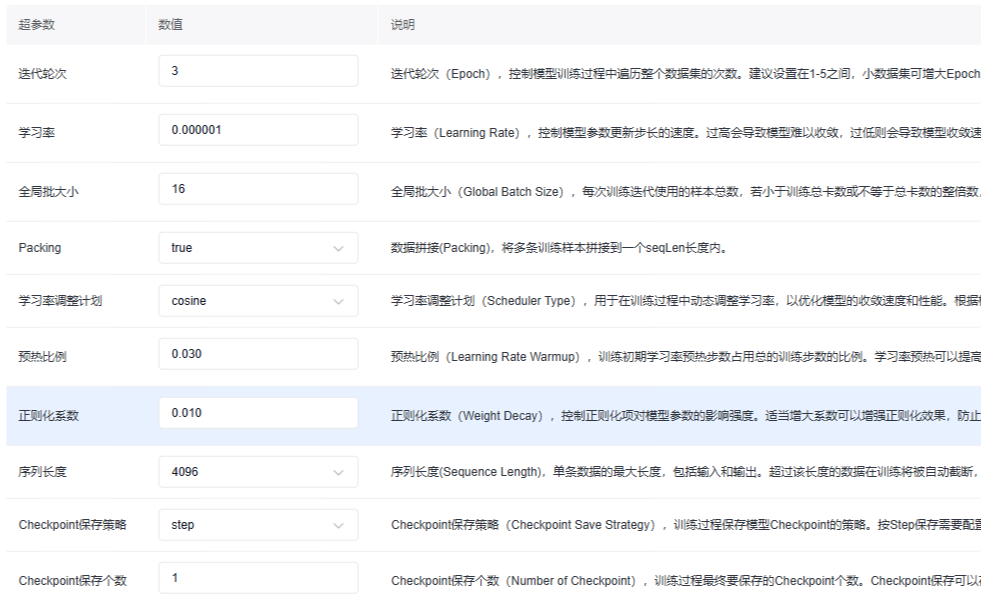
4.1 示例配置¶
- 蒸馏类型:知识蒸馏
- 教师模型:
Qwen3-8B - 学生模型:
Qwen3-0.6B
4.2 硬件建议¶
示例里给出的建议大致是:
- GPU:24G+
- RAM:64GB
- SSD:100GB
- Ubuntu 22.04
4.3 导出模型后做本地测试¶
蒸馏完成后,可以把模型导出,再在本地或 AutoDL 环境中做推理测试。
常见依赖包括:
pip install torch transformers==4.51.3 accelerate sentencepiece safetensors
pip install bitsandbytes
pip install flash-attn
然后通过一个基础推理脚本加载模型并测试输出即可。
五、为什么蒸馏常常是“运维友好型”优化¶
因为它不像全量大模型那样对 GPU 资源依赖极高,也不像单纯量化那样只是在压参数。蒸馏的目标是从模型能力层面做“轻量化重建”,这对真正要长期部署的系统很有意义。
六、一个实用判断¶
如果你的问题是“原模型太大、太贵、推理太慢”,那么蒸馏通常值得优先评估;如果你的问题只是“显存差一点点不够”,那量化可能会更直接。两者并不冲突,很多场景里反而是先蒸馏、再量化。