

一、压测对象¶
这份实战使用的是硅基流动提供的免费 Qwen3-8B 服务。
模型入口示意:
获取 API Key 的流程同样在平台控制台中完成。
公开文档里只建议写成:
SILICONFLOW_API_KEY=<your-api-key>
二、准备 EvalScope 环境¶
2.1 机器建议¶
示例环境可以很轻量:
- CPU:2C
- 内存:4G
- 磁盘:40G
- Ubuntu 22.04
2.2 安装 Python¶
sudo apt update
sudo apt install python3.10 python3-pip -y
python3 -m pip install --upgrade pip
2.3 安装 EvalScope¶
稳定版:
pip install evalscope
源码版:
git clone https://github.com/modelscope/evalscope.git
cd evalscope
pip install -e .
2.4 安装压测和可视化依赖¶
如果你只做压测,不一定要安装全部扩展,通常够用的是:
pip install 'evalscope[perf, app]'
如果你是源码安装:
pip install '.[perf, app]'
三、编写压测脚本¶
一个典型的 perf.py 脚本,会包含这些关键信息:
- API URL;
- 并发数;
- 模型名;
- 样本数量;
- 数据集类型;
- 是否流式输出;
- 认证 Header;
- 超时时间;
max_tokens。
你可以把认证头写成占位方式,例如:
'Authorization': 'Bearer <your-api-key>'
避免把真实 Key 留在脚本里。
四、执行压测¶
python3 perf.py
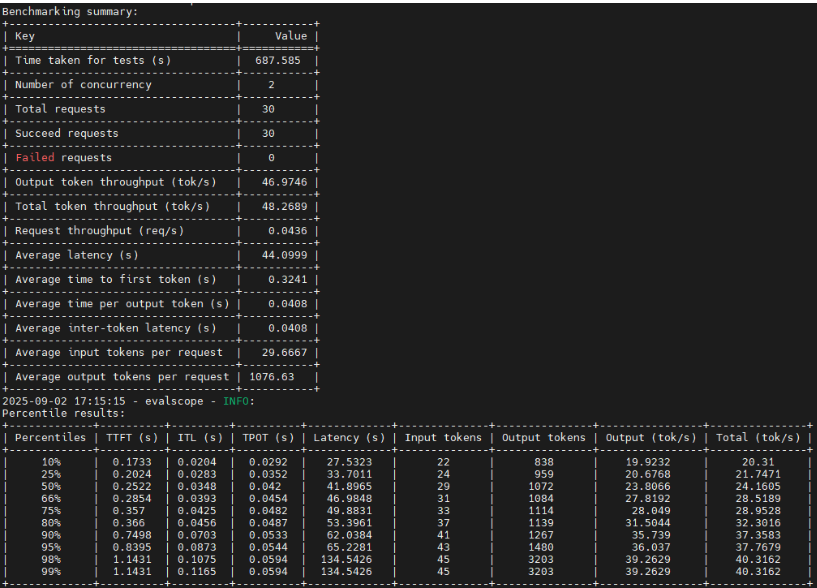
执行后,你会得到一组典型性能指标。
五、结果里重点看哪些指标¶
5.1 总时长¶
Time taken for tests
反映这轮压测从开始到结束一共花了多久。
5.2 并发数¶
Number of concurrency
说明你当前测试时模拟了多少并发请求。
5.3 成功和失败请求¶
Succeed requestsFailed requests
这是判断服务稳定性的第一层指标。
5.4 TPS 和请求吞吐¶
Output token throughputTotal token throughputRequest throughput
它们共同反映模型的输出能力和请求处理能力。
5.5 延迟指标¶
Average latencyAverage time to first tokenAverage time per output tokenAverage inter-token latency
这几项组合起来,能帮你判断:
- 首包是不是太慢;
- 后续生成是不是顺畅;
- 是否出现长尾抖动。
六、怎么理解这些指标¶
一个很直观的比喻是:
- TTFT:
- 学生看到题目后,写出第一个字之前思考了多久。
- TPOT:
- 后面每打出一个字的平均速度。
- TTLT:
- 整份答案从开始到写完用了多久。
对于用户体验来说:
- TTFT 决定“系统是不是立刻开始回答”;
- TPOT 决定“系统说话顺不顺”;
- 总延迟决定“整段回答多久结束”。
七、为什么建议先用小规模压测¶
第一次压测时,不要急着把并发拉很高。更稳妥的方式是:
- 先用小样本和低并发跑通;
- 再逐步提高并发和输出长度;
- 观察失败率、TTFT 和 TPS 是否出现明显劣化;
- 最后再确定系统的上线边界。
八、一个实用结论¶
EvalScope 的价值,不只是帮你测出一个“数字”,而是帮你系统化回答这几个问题:
- 模型在当前配置下最多能扛多少并发?
- 首字时间是否能接受?
- 输出速度是否足够稳定?
- 是 CPU、网络、模型服务,还是下游 API 成了瓶颈?
把这些问题先在线下测明白,线上运维会轻松很多。