

一、表达式上的索引
如Oracle数据库一样,PostgreSQL也支持函数索引。实际上,PostgreSQL索引的键除了可以是一个函数外,还可以是从一个或多个字段计算出来的标量表达式(mysql 8.0也支持部分函数索引)
看一个问题:
经常业务需要对一个表的字段做大小写无关比较时,常用的方法是使用lower函数,很简单:
SELECT * FROM mytest WHERE lower(note) = 'hello world';
但因为使用了函数,无法利用到“note”字段上的普通索引
案例:
CREATE TABLE students (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
age INTEGER
);
insert into students values(2,'hello world',19);
insert into students values(3,'hello world11',13);
insert into students values(4,'hello aaworld11',20);
CREATE INDEX mytest_lower_name_idx ON students (lower(name));
explain SELECT * FROM students WHERE lower(name) = 'hello world';
二、部分索引
原理:只对一个表中的部分行进行的索引,是由一个条件表达式把这部分行筛选出来,该条件表达式被称为部分索引的谓词。 部分索引在一些情况下非常有用,
比如举几个之前官方提到的例子
2.1 案例1
元数据ip访问系统: 特点:
-
内部ip不是很多,也比较固定,但这些内网的访问量很大,所以记录很多
-
有一部分外部访问的ip,ip五哈八门,多种多样
需求: 现在经常需要查询外部访问的一些内容(根据ip) 直接在ip字段建一个索引:
优点:比较省事 缺点:为内网的IP地址少,访问量大,索引的效率也不高
部分索引比较好的解决这种需求:
CREATE TABLE access_log ( url varchar, client_ip inet,……);
CREATE INDEX access_log_client_ip_ix ON access_log (client_ip)
WHERE NOT(client_ip > inet '192.168.100.0' AND client_ip < inet '192.168.100.255');
利用部分索引查询
SELECT * FROM access_log WHERE client_ip = inet '114.113.220.27';
但是如果是如下语句就不能走部分索引
SELECT * FROM access_log WHERE client_ip = inet '192.168.100.55';
2.2 案例2
设置一个部分索引以排除不感兴趣的数值 比如:假如有一个表,其中包含已付款和未付款的定单,而未付款的定单占总表的一小部分,并且是经常使用的部分,那么可 以只在未付款定单上创建一个索引来改善查询性能。
CREATE TABLE orders( order_nr int, amount decimal(12,2), billed boolean ); 创建索引:
CREATE INDEX orders_unbilled_index ON orders (order_nr) WHERE billed is not true;
造一些数据:
insert into orders select t.seq, t.seq*2.44, true from generate_series(1,500000) as t(seq); insert into orders select t.seq, t.seq*2.44, false from generate_series(500001,509000) as t(seq);
查询语句:
explain SELECT * FROM orders WHERE billed is not true AND order_nr < 10000; 如果等于true利用不到索引
explain SELECT * FROM orders WHERE billed is true AND order_nr < 10000;
索引也可以用于那些完全不涉及索引键order_nr的查询,
explain SELECT * FROM orders WHERE billed is not true AND amount > 40105960.00;
需要注意:
PostgreSQL支持带任意谓词的部分索引,条件是只涉及被索引表的字段,但是,谓词必须和那些希望从该索引中获益的查询 中的WHERE条件相匹配, 准确地说,只有在系统能够识别出该查询的WHERE条件简单地包含了该索引的谓词时,这个部分索引才能用于该查询。 PostgreSQL还没有智能到可以完全识别那些形式不同但数学上意义相等的谓词。
案例:
把WHERE条件中的“billed is not true”改成“(not billed)”
explain SELECT * FROM orders WHERE (not billed ) AND order_nr < 10000;
2.3 案例3:设置一个部分唯一索引
CREATE TABLE tests ( subject text, target text, success boolean, ... );
CREATE UNIQUE INDEX tests_success_constraint ON tests (subject, target) WHERE success;
三、GiST索引
GiST是Generalized Search Trees的缩写,意思是通用搜索树。它是一种平衡树结构的访问方法,是用户建立自定义索引的 基础模版,用户只要按模板实现所要求的GiST操作类中的一系列的回调函数就可以实现自定义的索引,而不用关心GiST索引 具体是如何存储的。BTree和许多其他的索引都可以用GiST来实现
简单理解:GiST是一种索引的实现方式,提供更好的接口来提供我们实现一种索引在pg里面
3.1 GiST索引如何实现
意思是通用搜索树,底层结构也是一种平衡树,它是一套索引模板,可以支持用户实现自定义的索引。相比于BTree索引, BTree索引可以建立在任意类型之上,但是BTree只支持<、=、>操作符,而Gist索引可以支持@>、&&等复杂运算的操作符
consistent:给出一个索引项p和一个查询q,该函数确定索引项是否与查询相容(consitent) union:表示如何在树中组合信息。将多个项联合成一个索引项 compress:如何把数据项转换成一种适合存储在索引页中的格式
decompress:compress的反向操作 penalty:返回一个值,用于表示把一个新节点插入到一个树叉上的代价(cost)。 picksplit:当一个索引列需要分裂时,该函数决定哪些节点需要留在原索引页中,哪些节点需要移到新的索引页中 same:判断两个索引项是否相等,相等则返回true,否则返回 false distance:返回索引项p和查询值q之间的“距离”
fetch:将一个压缩过的索引数据项转换成原始的数据项
支持Gist索引的的操作类
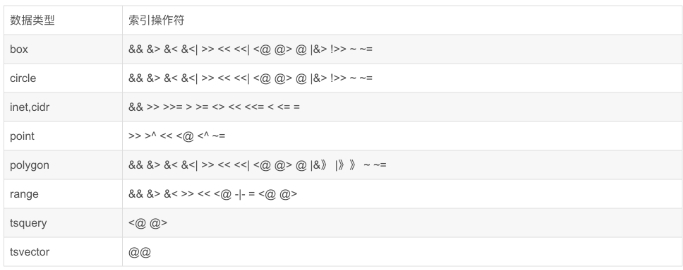
使用gist索引案例:
3.2 Point类型上创建Gist索引
create table pts(id int ,p point);
\d+ pts;
## 插入测试数据
insert into pts select t.d,point(ceil(random()*1000),ceil(random()*1000)) from generate_series(1,1000000) as t(d);
在没有索引的条件下进行查询,查询语句的意思是查找所有在圆形((100,100) 100)范围内的点:
explain analyze select * from pts where circle '((100,100) 100)' @> p;
创建gist索引
create index on pts using gist(p);
再次查看执行计划
explain analyze select * from pts where circle '((100,100) 100)' @> p;
3.3 inet类型的Gist索引
create table vector(id int,ip inet); \d+ vector;
插入测试数据
insert into vector select t.d,inet(ceil(random()*255)||'.'||ceil(random()*255)||'.'||ceil(random()*255)||'.'||ceil(random()*255)) from generate_series(1,1000000) as t(d);
查询IP地址等于77.80.250.123的所有IP地址:
explain analyze select * from vector where ip = '77.80.250.123'::inet;
在插入Gist索引之前,我们先插入BTree索引,来查看查询效率如何:
create index vector_btree_inx on vector using btree(ip);
explain analyze select * from vector where ip = '77.80.250.123'::inet;
插入Gist索引
create index vector_gist_inx on vector using gist(ip inet_ops);
explain analyze select * from vector where ip = '77.80.250.123'::inet;
查询所有在指定子网内的记录
explain analyze SELECT * FROM vector WHERE ip << '192.0.2.0/24';
总结:使用Gist索引的查询效率和使用Btree的查询效率差不多,但是需要BTree索引是不支持<<、@>这些操作符的
3.4 SP-GiST索引
(通常用于多维空间)首先,对这个名字说几句话。“GiST”部分暗示了与同名访问方法的一些相似之处。这种相似性确实存在:两者都是通用的搜索树,为构建各种访问方法提供了框架
SP”代表空间分区。这里的空间通常就是我们所说的空间,比如二维平面。但我们将看到,任何搜索空间都是有意义的,也就 是说,实际上是任何值域
SP-GiST适用于空间可以递归分割为非相交区域的结构。该类包括四叉树、k维树(k-D树)和基数树
怎么创建SP-GiST
建SP-GiST索引的方法是使用“USING spgist (colname)”子
create table test01(p point);
CREATE INDEX ON test01 USING spgist (p);
四、GIN索引
GIN的主要应用领域是加速全文搜索,所以,这里我们使用全文搜索的例子介绍一下GIN索引。
如(‘hankʼ, ‘153 214ʼ)中,表示hank在15:3和21:4这两个位置出现过,下面会从具体的例子更加清晰的认识GIN索引
案例:建一张表,doc_tsv是文本搜索类型,可以自动排序并消除重复的元素:
建一张表,doc_tsv是文本搜索类型,可以自动排序并消除重复的元素:
create table ts(doc text, doc_tsv tsvector);
insert into ts(doc) values
('Can a sheet slitter slit sheets?'),
('How many sheets could a sheet slitter slit?'),
('I slit a sheet, a sheet I slit.'),
('Upon a slitted sheet I sit.'),
('Whoever slit the sheets is a good sheet slitter.'),
('I am a sheet slitter.'),
('I slit sheets.'),
('I am the sleekest sheet slitter that ever slit sheets.'),
('She slits the sheet she sits on.');
update ts set doc_tsv = to_tsvector(doc);
create index on ts using gin(doc_tsv);
select ctid,doc, doc_tsv from ts;
#禁用全表扫描
set enable_seqscan TO off;
explain analyze select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
GIN索引优缺点
优点:
- Gin索引是用来加快全文搜索的,适合做模糊查询和正则查询。
缺点:
-
GIN索引对于插入更新操作效率比较低,如果要向一张表中插入大量数据,最好先把GIN索引删除,然后插入数据,最后 再把GIN索引重新建起来。
-
把maintenance_work_mem参数调大,可以更快地完成GIN索引的创建工作
五、BRIN索引
BRIN索引是Block Range Index索引的简写,它将数据在磁盘上的block按照一定的数目进行分组,这个数目可以通过创建 BRIN时的参数pages_per_range进行设置,默认是128。分组之后,计算每组的取值范围。在 查找数据时,会遍历这些取值 范围,排除掉不在范围之内的分组
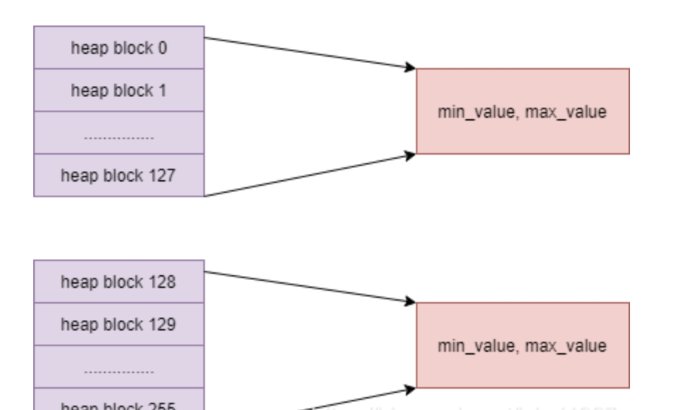
与其它索引不同:
-
BTree等其它索引在查找数据时是根据数据定位到数据行的位置,而BRIN索引是先排除不再范围内的数据块,一旦找到包 含目标数据的数据块范围之后,采用位图扫描获取相应数据行。
-
由于BRIN是将相邻的磁盘块组合,所以它适合在数值上线性增长的数据列建立索引,而且数据行应该不经常执行删除操 作,否则就可能因为删除操作进行频繁的重建索引。
-
BRIN按照一定数目将磁盘块整合,因此在占用空间上要比BTree小,但是因为采用遍历方式排除数据,性能上势必差于 BTree。
案例:
create table test01(id int,info text);
create index idx_test01_id on test01 using brin(id);




暂无评论内容