
来自AI助手的总结
介绍了K8s节点维护中驱逐、调度与恢复的两种流程
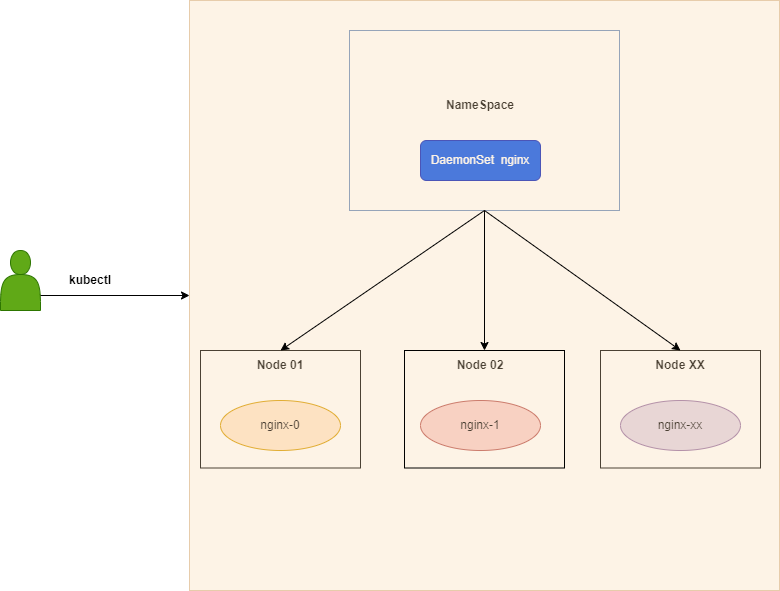
一、K8s节点维护流程
当 Kubernetes 的节点需要进行下线维护时,此时需要先把该节点的服务进行驱逐和重新调度。
此时需要根据实际情况判断是直接驱逐还是选择重新调度,比如某个 Pod 只有一个副本,或者某个服务比较重要,就不能直接进行驱逐,而是需要先把节点关闭调度,然后在进行服务的重新部署。
1.1 环境准备
1、创建单实例redis来模拟k8s-node02节点上的重要服务
[root@k8s-master01 ~]# k create deploy cache --image=registry.cn-hangzhou.aliyuncs.com/abroad_images/redis:7.2.5
2、验证
[root@k8s-master01 ~]# kgp -owide | grep cache
cache-64bb68ddff-bkjhw 1/1 Running 0 17s 192.168.58.226 k8s-node02 <none> <none>
1.2 节点维护
1.2 方式一:污点实现
1、关闭维护节点的调度
[root@k8s-master01 ~]# kubectl taint node k8s-node02 maintain:NoSchedule
2、重新触发某个重要服务的部署
[root@k8s-master01 ~]# k rollout restart deploy cache
重新查看重要服务,观察到重新部署到k8s-master01节点
[root@k8s-master01 ~]# kgp -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cache-585b45fd4d-q92m9 1/1 Running 0 39s 192.168.32.146 k8s-master01 <none> <none>
3、k8s-node02目前没有其他重要服务,直接驱逐该节点上的其他pod
[root@k8s-master01 ~]# kubectl taint node k8s-node02 maintain:NoExecute
4、等待5分钟后,驱逐后,即可按照预期进行对节点进行维护,维护完成
5、维护完成后,删除污点重新调度
[root@k8s-master01 ~]# kubectl taint node k8s-node02 maintain-
验证,观察到污点已取消
[root@k8s-master01 ~]# k describe node k8s-node02 | grep Taints
Taints: <none>
1.2 方式二:kubectl 快捷指令
1、将节点标记为不可调度状态
[root@k8s-master01 ~]# kubectl cordon k8s-node02
验证查看,节点标记为SchedulingDisabled状态,但是已经运行在该节点的 Pod 不收影响
[root@k8s-master01 ~]# kg node | grep node02
k8s-node02 Ready,SchedulingDisabled <none> 10d v1.32.3
2、重新触发某个重要服务的部署
[root@k8s-master01 ~]# k rollout restart deploy cache
重新查看重要服务,观察到重新部署到k8s-node01节点
[root@k8s-master01 ~]# kgp -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cache-fcc5dff55-j5ckj 1/1 Running 0 13s 192.168.85.211 k8s-node01 <none> <none>
3、k8s-node02目前没有其他重要服务,直接驱逐该节点上的其他pod
[root@k8s-master01 ~]# kubectl drain k8s-node02 --ignore-daemonsets --delete-emptydir-data
相关参数说明:
-
--ignore-daemonsets -
作用:忽略由 DaemonSet 管理的 Pod(如网络插件、日志采集组件),允许排空操作继续执行。
-
风险:可能导致节点级服务暂时中断,需确保集群有冗余节点支持。
-
--delete-emptydir-data -
作用:删除使用
emptyDir卷的临时数据 -
风险:数据不可恢复,需确认应用不依赖这些数据持久化。
4、等待5分钟后,驱逐后,即可按照预期进行对节点进行维护,维护完成
5、维护完成后,删除污点重新调度
[root@k8s-master01 ~]# kubectl uncordon k8s-node02
验证查看
[root@k8s-master01 ~]# kg node | grep node02
k8s-node02 Ready <none> 10d v1.32.3
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END





暂无评论内容