
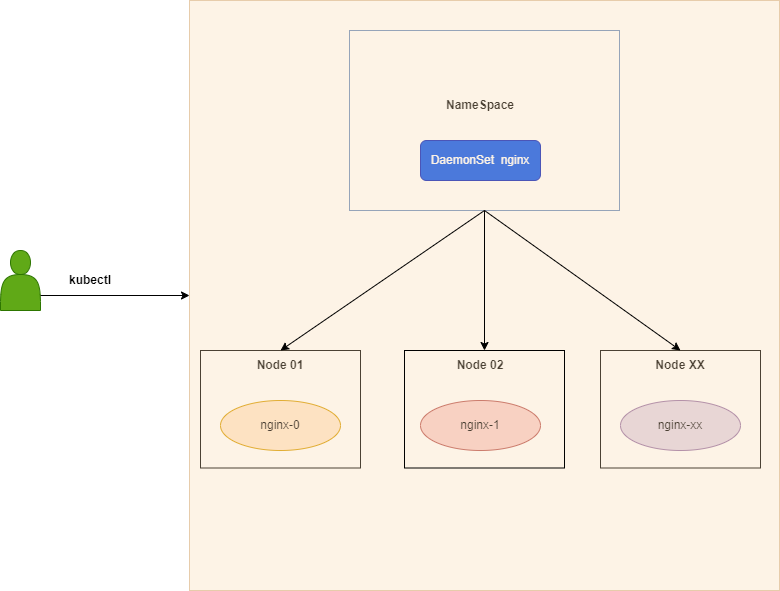
一、先理解 Pod 常见状态
日常最常见的 Pod 状态包括:
PendingRunningSucceededFailedUnknownImagePullBackOff/ErrImagePullCrashLoopBackOffOOMKilledTerminatingSysctlForbiddenCompletedContainerCreating
虽然状态很多,但真正排查时,抓住“调度、镜像、启动、资源、删除”这几个方向就够了。
二、Kubernetes 官方 phase 只有五种
严格来说,Pod 的 status.phase 只有五种:
PendingRunningSucceededFailedUnknown
而像 ImagePullBackOff、CrashLoopBackOff、ContainerCreating 这些更常见的显示值,通常是更细粒度的容器状态或等待原因。
所以排查时不要只盯着列表里的字面值,更要继续往下看 describe 和日志。
三、最常见的异常状态怎么排查
3.1 Pending
含义:Pod 已被系统接受,但一个或多个容器还没有成功创建。
优先排查:
kubectl describe po xxx -n xxx
最常见原因通常是:
- 调度不到合适节点
- 镜像尚未拉取完成
- PVC、配额或节点资源有问题
3.2 Running
含义:Pod 已经运行,但这不一定代表业务一定正常。
尤其要注意:Running 不等于真正可用,还要继续看 READY 是否为 N/N。
排查日志:
kubectl logs xxx -n xxx
3.3 Succeeded / Completed
这类状态常见于一次性任务,比如 Job。它表示容器执行成功并正常退出。
需要复盘执行结果时,直接看日志:
kubectl logs xxx -n xxx
3.4 Failed
表示 Pod 中至少有一个容器以失败方式结束。
常用排查方式:
kubectl logs xxx -n xxx
kubectl describe po xxx -n xxx
3.5 ImagePullBackOff / ErrImagePull
这通常表示镜像拉取失败。
常见原因包括:
- 镜像地址错误
- 镜像不存在
- 网络不通
- 私有仓库认证失败
优先查看:
kubectl describe po xxx -n xxx
3.6 CrashLoopBackOff
这是最典型也最常见的异常状态之一,表示容器启动后很快退出,并不断重启。
常见原因:
- 启动命令写错
- 主进程启动失败
- 健康检查不通过
- 配置缺失
先看日志:
kubectl logs xxx -n xxx
kubectl logs xxx -n xxx --previous
3.7 OOMKilled
表示容器因为内存不足被系统杀掉。
常见原因:
limits.memory设置过小- 程序自身出现内存泄漏或异常占用
排查日志:
kubectl logs xxx -n xxx
3.8 Terminating
表示 Pod 正在被删除。
如果长时间停留在这里,可以继续看:
kubectl describe po xxx -n xxx
常见原因通常和终止流程、挂载资源释放、finalizer 或节点状态有关。
3.9 SysctlForbidden
表示 Pod 自定义了内核参数,但节点上的 kubelet 没有允许相关配置,或者参数本身不受支持。
优先还是看:
kubectl describe po xxx -n xxx
3.10 ContainerCreating
表示 Pod 正在创建中。
如果持续时间过长,常见原因通常有:
- 镜像下载慢或拉取失败
- 卷挂载异常
- CNI 网络初始化有问题
同样先看:
kubectl describe po xxx -n xxx
四、排查 Pod 的一套通用思路
如果你不想在每次故障时都临场猜,可以固定按下面这套顺序排查:
4.1 先看状态和节点
kubectl get po -o wide
确认 Pod 在哪个节点、当前状态是什么、是否已经分配 IP。
4.2 再看详细事件
kubectl describe po xxx -n xxx
这一步通常能直接看到调度失败、镜像拉取失败、挂载失败、探针失败等关键信息。
4.3 再看当前和上一次日志
kubectl logs xxx -n xxx
kubectl logs xxx -n xxx --previous
特别是 CrashLoopBackOff 场景,--previous 很有价值。
4.4 最后再回到配置本身
重点检查:
- 镜像地址是否正确
- 启动命令和参数是否正确
- 探针配置是否合理
- 资源限制是否过紧
- Secret、ConfigMap、Volume 是否挂载成功
五、学会看状态,本质上是在学会看系统信号
Pod 排障的核心并不是背熟所有状态名,而是建立一种系统化判断方式:
- 调度问题先看
describe - 启动问题先看
logs - 重启问题结合
--previous - 资源问题重点看
OOMKilled - 删除卡住重点看终止流程和对象依赖
当你把 Pod 状态看作系统给出的信号,而不是一串英文单词时,排障效率会提升很多。





暂无评论内容