
一、为什么声明式 API 是云原生的重要基础
声明式 API 是一种比较流行且先进的编程范式,它强调通过声明的方式表达目标状态,而不是手工描述每一步操作过程。
这种模式的关键价值在于把“我想要什么结果”和“系统怎么执行”分离开来:
- 技术人员只需要描述期望状态。
- 平台负责根据声明去完成构建、部署和管理动作。
- 工程师不必反复处理大量低层细节。
这正是云原生平台能够实现自动化、自愈和持续交付的重要前提。
二、如何理解声明式 API 的工作方式
声明式 API 的核心不是“少写命令”,而是“把意图标准化”。
例如在 Kubernetes 中,我们不会手工一步步创建进程、分配资源、拉起副本,而是把目标状态写成清晰的 YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: account
namespace: kube-system
spec:
replicas: 4
template:
spec:
containers:
- name: account
image: account:v1
resources:
limits:
memory: 2048Mi
cpu: "2"
requests:
memory: 1024Mi
cpu: "1"
env:
- name: MYSQL_HOST
value: "1.1.1.1"
从这个例子可以看出,工程师只需要表达:
- 要运行什么工作负载
- 需要几个副本
- 每个容器用什么镜像
- 需要多少 CPU 和内存
- 依赖哪些环境变量
至于怎么调度、怎么维持副本数量、怎么恢复异常实例,交给平台处理即可。
三、什么是 Serverless
Serverless 是一种无服务器架构,它让技术人员不必直接管理服务器和大部分底层基础设施。
它带来的直接变化包括:
- 平台负责更多运行时管理工作。
- 应用能够更快构建和发布。
- 弹性能力更强,资源成本更容易按需控制。
从使用体验上看,Serverless 并不是“没有服务器”,而是“服务器管理细节被平台屏蔽掉了”。
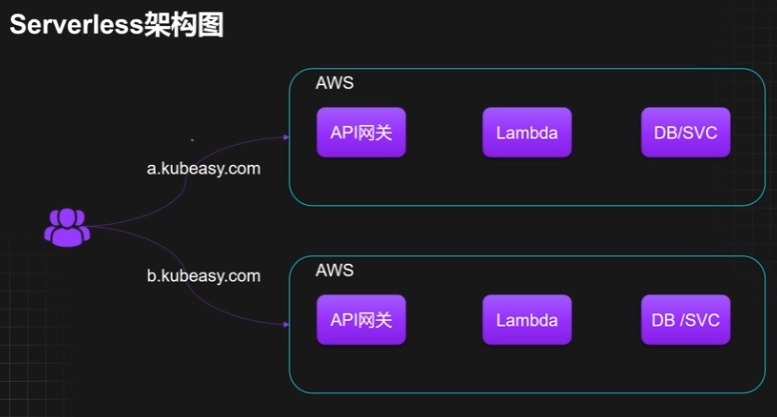
四、Serverless 的典型架构链路
在很多场景里,Serverless 会围绕事件触发和托管服务来组织架构。
例如一个典型链路可以是:
用户访问域名 -> API Gateway -> Lambda(逻辑处理) -> NLP 服务(如 AWS Lex) -> 数据库
下面这张图就是对应的 Serverless 架构示意:
这类架构的特点是:
- 入口清晰,通常由网关接收请求。
- 计算逻辑由函数或短生命周期任务承载。
- 数据和 AI 能力通常由托管服务补齐。
- 应用更容易基于事件与按需触发来运行。
五、Serverless 在不同场景下怎么落地
Serverless 的优势主要体现在“弹性明显、任务触发明确、业务波动较大”的场景。
5.1 聊天机器人
核心需求是实时响应、高并发处理和自然语言理解。
典型链路可以是:
用户消息 -> API Gateway -> Lambda -> NLP 服务 -> DynamoDB
这种模式适合:
- 自动应对瞬时高峰流量
- 管理临时会话状态
- 统一处理来自微信、Web、APP 等多渠道请求
在优化时,还可以通过预置并发降低冷启动影响,并使用 Step Functions 管理多轮对话流程。
5.2 大模型与 AI 推理
核心需求是低成本弹性推理、异步任务调度和按需使用 GPU 资源。
常见做法包括:
- 用 Lambda 加载轻量化模型处理简单请求,如文本分类。
- 用对象存储事件触发函数,再调用 SageMaker 端点完成识别与推理。
- 使用 AWS Batch 或 Lambda 配合 Fargate 动态启停资源,处理更重的批量任务。
这种模式特别适合请求波动明显、对成本敏感的 AI 场景。
5.3 视频、图片与语音处理
核心需求是高性能转码、实时处理和分布式任务拆分。
典型链路可以是:
文件上传至 S3 -> 触发 Lambda -> 调用 FFmpeg 转码 -> 结果回写 S3 -> 刷新 CDN
扩展场景还包括:
- 通过 Rekognition 做视频内容分析
- 通过 Transcribe 做语音转写
- 大文件处理时由 Lambda 负责拆分任务,再交给 ECS 或 EC2 Spot 实例做重计算
5.4 ETL 数据处理
核心需求是定时任务、数据清洗和流式处理。
常见落地方式包括:
- 通过 CloudWatch Events 定时触发 Lambda,读取 RDS 数据后写入 Redshift
- 使用
Kinesis -> Lambda -> Elasticsearch形成流式 ETL 管道 - 配置死信队列捕获失败数据,并借助
S3 + Athena做重放与分析
六、如何理解声明式 API 与 Serverless 的关系
这两类能力虽然关注点不同,但本质上都在做同一件事:把复杂的基础设施细节隐藏到平台后面。
- 声明式 API 让我们用目标状态管理系统。
- Serverless 让我们用事件和函数驱动应用。
- 两者都强调自动化、标准化和更高层级的抽象。
对学习 Kubernetes 和云原生平台的人来说,理解这两种思想非常重要。因为未来很多平台能力,看起来是在学某个产品,实际上是在学“如何把复杂系统交给平台治理”。





暂无评论内容