
一、K8s使用Model资源部署大模型¶
1、在 K8s 上部署大模型,可以直接用 Ollama Operator 的 CRD Model 部署,比如部署一个 phi的模型
# 编写配置文件
cd /home/ubuntu
vim phi.yaml
apiVersion: ollama.ayaka.io/v1
kind: Model
metadata:
name: phi
spec:
image: phi
storageClassName: local-path
replicas: 1
imagePullPolicy: IfNotPresent
# 应用yaml
kubectl create -f phi.yaml
# 验证
kubectl get po
2、首次部署大模型,会先创建一个 store 服务,用于存储 ollama 的模型文件
# 当Store起来后,会创建一个ollama服务,用于启动大模型
kubectl get po
# 如果本地文件并没有当前模型,会先启动一个init容器进行模型的下载
kubectl logs -f ollama-model-phi-6dbf6988fc-5jb7r -c ollama-image-pull
# 下载完成后,模型服务随之启动完成
kubectl get po -n ollama-llms
# 查看下载的模型文件
kubectl exec -ti ollama-models-store-0 -n ollama-llms -- bash
root@ollama-models-store-0:/# ls /root/.ollama/models/
blobs manifests
# 同时也会创建一个SVC,用于调用该模型
root@VM-0-2-ubuntu:/home/ubuntu# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ollama-model-phi ClusterIP 10.103.112.80 <none> 11434/TCP 5m8s
ollama-models-store ClusterIP 10.98.84.255 <none> 11434/TCP 8m3s
# 访问测试
curl http://10.101.107.101:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "phi",
"messages": [
{
"role": "user",
"content": "Hello! 你是什么模型?参数量有多大?"
}
]
}'
# 回复内容
{"id":"chatcmpl-267","object":"chat.completion","created":1739962225,"model":"phi","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":" Hi there! As an NLP model, my components are quite extensive. However, I can perform various functions such as language translation, question answering, sentiment analysis, text summarization, and more. The parameters for each of these functions vary depending on the specific task at hand, but overall, my training process involves numerous layers and models to improve performance over time while using large datasets.\n"},"finish_reason":"stop"}],"usage":{"prompt_tokens":65,"completion_tokens":79,"total_tokens":144}}
3、测试完毕后,可以卸载该模型
# 卸载模型
kubectl delete -f phi.yaml
# 结果验证
root@VM-0-2-ubuntu:/home/ubuntu# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 67m
ollama-models-store ClusterIP 10.105.115.183 <none> 11434/TCP 10m
root@VM-0-2-ubuntu:/home/ubuntu# kubectl get po
NAME READY STATUS RESTARTS AGE
cuda-vectoradd 0/1 Completed 0 61m
ollama-models-store-0 1/1 Running 0 10m
volume-test 1/1 Running 0 56m
说明:store 服务不会卸载,后续在创建其他模型,不会在安装 store 服务。
二、K8s使用Kollama工具部署大模型¶
除了使用自定义资源部署,还可以使用 Kollama 工具进行部署。
1、在 ollama-llms 空间下,部署 phi 大模型
cd /home/ubuntu
./kollama deploy phi --image=phi --storage-class local-path -n ollama-llms
2、查看创建的 Pod(已经下载的模型,不会在重新下载)
kubectl get po -n ollama-llms
3、使用 expose 指令暴露服务
cd /home/ubuntu
root@VM-0-2-ubuntu:/home/ubuntu# ./kollama expose phi -n ollama-llms
🎉 The model has been exposed through a service over 10.224.0.2:30997.
To start a chat with ollama:
OLLAMA_HOST=10.224.0.2:30997 ollama run phi
To integrate with your OpenAI API compatible client:
curl http://10.224.0.2:30997/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "phi",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'.
4、测试
# 测试
curl http://10.224.0.2:30997/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "phi",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'.
# 回复
{"id":"chatcmpl-708","object":"chat.completion","created":1739962460,"model":"phi","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":" Hi there! How can I assist you today?\n"},"finish_reason":"stop"}],"usage":{"prompt_tokens":34,"completion_tokens":13,"total_tokens":47}}
5、测试完毕后,可以卸载该模型
cd /home/ubuntu
./kollama undeploy phi -n ollama-llms
三、K8s一键部署Deepseek R1模型¶
1、定义yaml文件
vim deepseek-r1-1.5b.yaml
apiVersion: ollama.ayaka.io/v1
kind: Model
metadata:
name: deepseek-r1
namespace: ollama-llms
spec:
image: deepseek-r1:1.5b
storageClassName: local-path
replicas: 1
imagePullPolicy: IfNotPresent
2、创建模型
kubectl create -f deepseek-r1-1.5b.yaml -n ollama-llms
3、查看状态
kubectl get po -n ollama-llms
4、查看创建的 svc 并执行测试
root@VM-0-2-ubuntu:/home/ubuntu# kubectl get svc -n ollama-llms
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ollama-model-deepseek-r1 ClusterIP 10.103.67.9 <none> 11434/TCP 5m41s
ollama-models-store ClusterIP 10.98.84.255 <none> 11434/TCP 15m
# 测试
curl http://10.111.125.216:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "Hello! 你是什么模型?参数量有多大?"
}
]
}'
# 回复
四、K8s一键部署任意大模型¶
如果需要部署其他大模型,也可以用同样的方式部署。
1、在 ollama 官网查找需要部署的模型,这里以llama3.3为例
ollama 官网链接:https://ollama.com/search
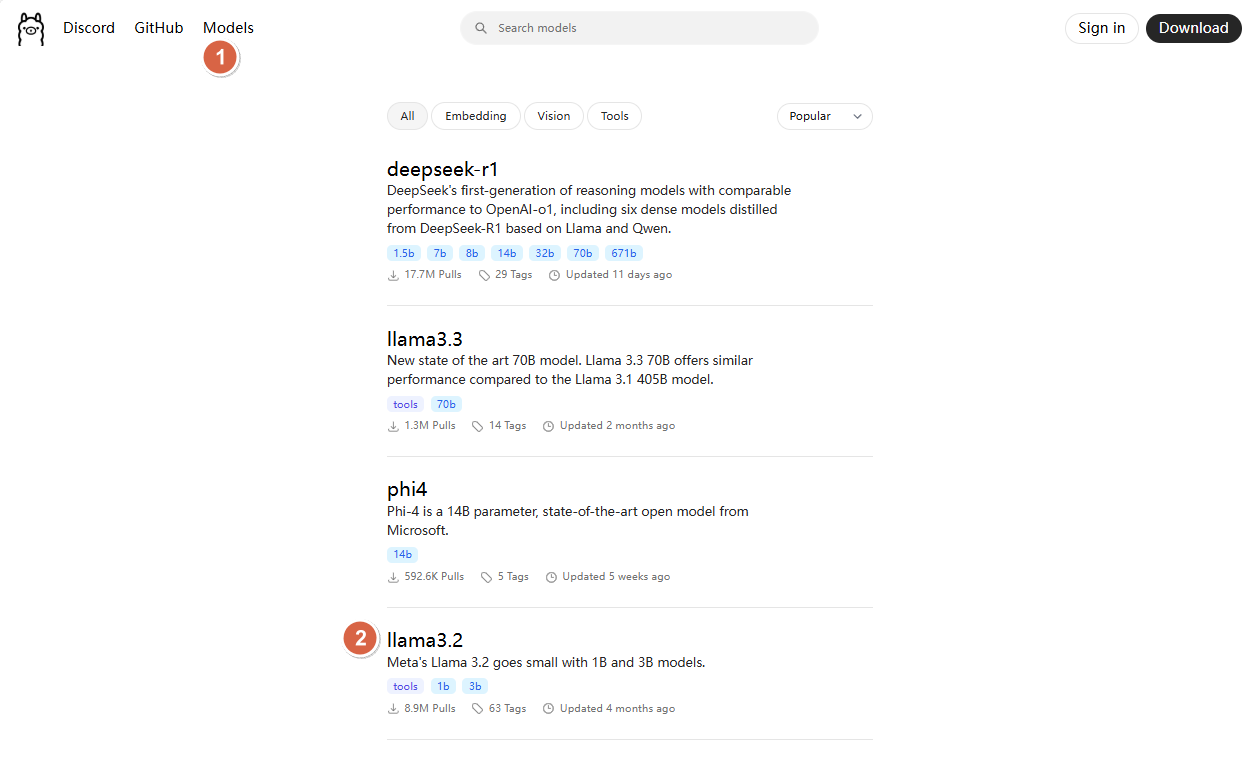
2、找到llama3.2具体的版本
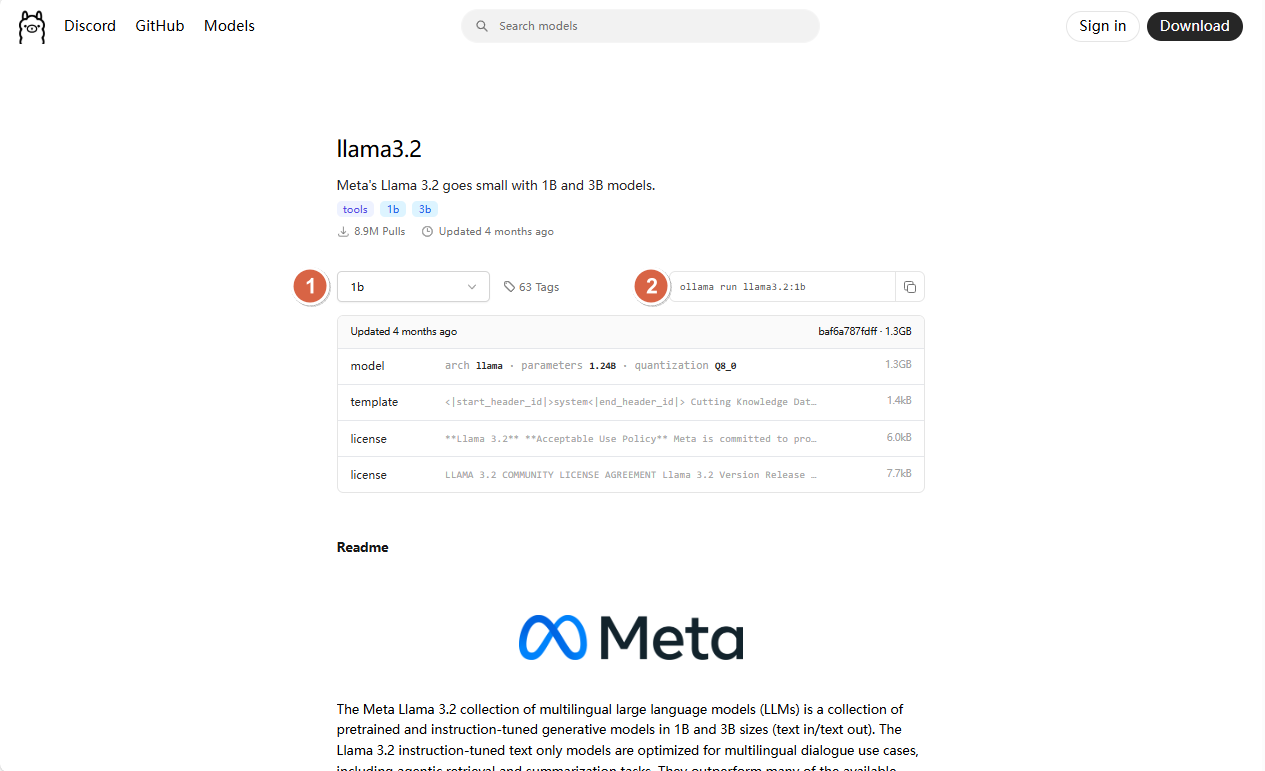
3、创建 Model 资源
# 创建yaml文件
cd /home/ubuntu
vim llama3.2.yaml
apiVersion: ollama.ayaka.io/v1
kind: Model
metadata:
name: llama-3-2-1b
spec:
image: llama3.2:1b
storageClassName: local-path
replicas: 1
imagePullPolicy: IfNotPresent
4、创建模型
kubectl create -f llama3.2.yaml
五、K8s部署Open WebUI¶
1、创建WebUI 的 PVC
cd /home/ubuntu
# 定义yaml文件
vim open-webui-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
app: open-webui
name: open-webui-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
# 应用yaml文件创建pvc
kubectl create -f open-webui-pvc.yaml
2、创建Deployment
cd /home/ubuntu
# 定义yaml文件
vim open-webui-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: open-webui-deployment
spec:
replicas: 1
selector:
matchLabels:
app: open-webui
template:
metadata:
labels:
app: open-webui
spec:
containers:
- name: open-webui
image: registry.cn-beijing.aliyuncs.com/dotbalo/open-webui:main
ports:
- containerPort: 8080
resources:
requests:
cpu: "500m"
memory: "500Mi"
limits:
cpu: "1000m"
memory: "1Gi"
env:
- name: OLLAMA_BASE_URL
value: "http://ollama-models-store:11434"
- name: ENABLE_OPENAI_API
value: "false"
- name: HF_HUB_OFFLINE
value: "1"
tty: true
volumeMounts:
- name: webui-volume
mountPath: /app/backend/data
volumes:
- name: webui-volume
persistentVolumeClaim:
claimName: open-webui-pvc
3、创建 Deployment 并暴露服务
# 创建Deployment
kubectl create -f open-webui-deploy.yaml
# 暴露服务
kubectl expose deploy open-webui-deployment --type NodePort
4、查看服务
root@VM-0-2-ubuntu:/home/ubuntu# kubectl get svc open-webui-deployment
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
open-webui-deployment NodePort 10.103.84.203 <none> 8080:31500/TCP 82s
5、webui 启动完成后,即可通过 IP地址31500 端口访问 webu
六、K8s中指定GPU资源部署大模型¶
在 K8s 中使用 ollama 部署大模型,和虚拟机类似,默认也是使用全部的 GPU 资源进行启动模型服务。
如果需要控制调度的 GPU 资源,可以使用 resources 进行指定,比如当前模型只允许使用 1个 GPU 卡
apiVersion: ollama.ayaka.io/v1
kind: Model
metadata:
name: deepseek-r1
spec:
image: deepseek-r1:1.5b
storageClassName: mdx-local-path
replicas: 2
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 4
memory: 8Gi
nvidia.com/gpu: 1
requests:
cpu: 4
memory: 8Gi
nvidia.com/gpu: 1
七、在 K8s 一键扩容模型服务¶
1、在 K8s 中扩容大模型服务,只需要更改 Model 资源的副本数即可
...
...
replicas: 2
...
...
完整文件如下:
vim deepseek-r1-1.5b.yaml
apiVersion: ollama.ayaka.io/v1
kind: Model
metadata:
name: deepseek-r1
namespace: ollama-llms
spec:
image: deepseek-r1:1.5b
storageClassName: local-path
replicas: 2
imagePullPolicy: IfNotPresent
2、更新 K8s 资源
kubectl replace -f deepseek-r1-1.5b.yaml
3、查看资源
kubectl get po | grep deepseek-r1