

一、开源模型一般去哪里找¶
- Hugging Face:
https://huggingface.co/models - 魔塔社区:
https://modelscope.cn/models
二、部署前先把思路定下来¶
2.1 先确定目标模型¶
例如以 QWQ-32B 为例。
2.2 再反推硬件参数¶
按公式 M = (P * Q) * 1.2 / 8 估算显存需求。
以 32B、FP16 为例:
32 * 16 * 1.2 / 8 = 76.8G
对应的硬件建议可以是:
- GPU:A100 或 H100 这类 80G 显卡。
- 如果只有 24G 的 4090,就更适合部署 INT4 量化版,或者更小参数版本。
- CPU:16 核或更多。
- 内存:不少于 160G,建议 256G。
- 磁盘:4TB SSD。
2.3 最后决定部署方案¶
- 预算充足:直接采购物理 GPU 服务器。
- 前期投入想低一些:选择阿里云、腾讯云、AutoDL 这类按量付费方案。
- 做实验:优先选择性价比最高的云资源,不用时关机。
三、使用阿里云 PAI 部署大模型¶
地址:
https://www.aliyun.com/product/bigdata/learn
3.1 方法一:Model Gallery 直接部署¶
路径可以理解为:
Model Gallery -> 找到目标模型 -> 部署
步骤 1:进入 Model Gallery 并选择模型¶
这里以 DeepSeek-R1-Distill-Qwen-1.5B 为例。
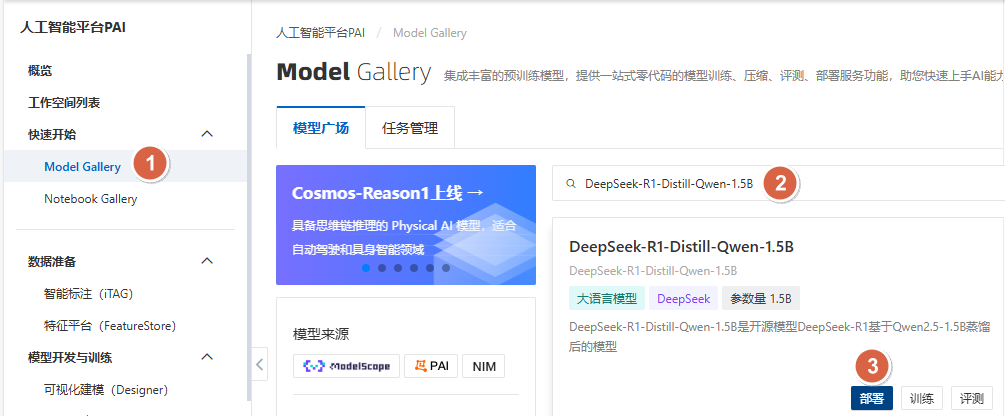
步骤 2:选择部署资源规格¶
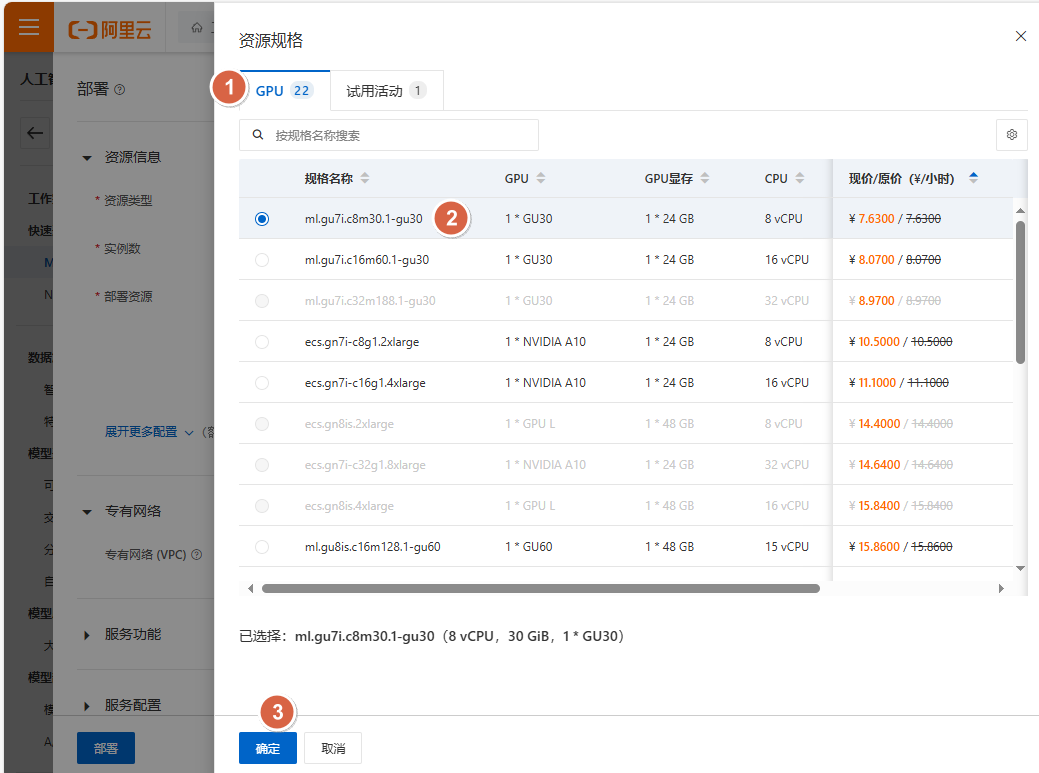
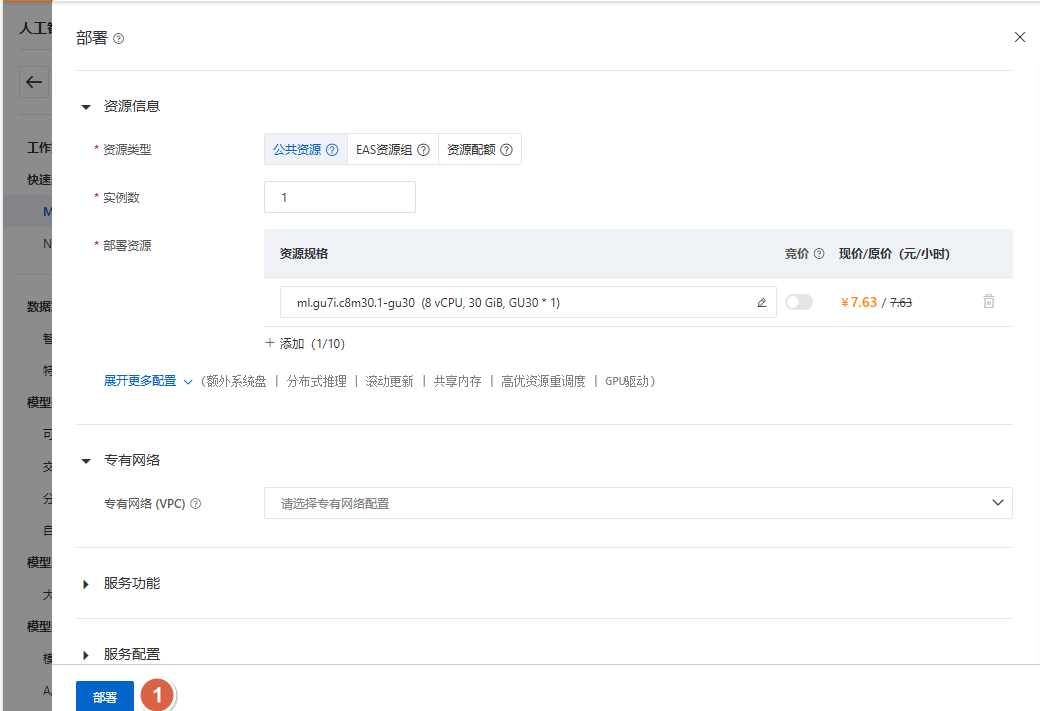
步骤 3:点击部署¶
步骤 4:查看调用信息¶
进入:
模型部署 -> 模型在线服务(EAS)-> 调用信息
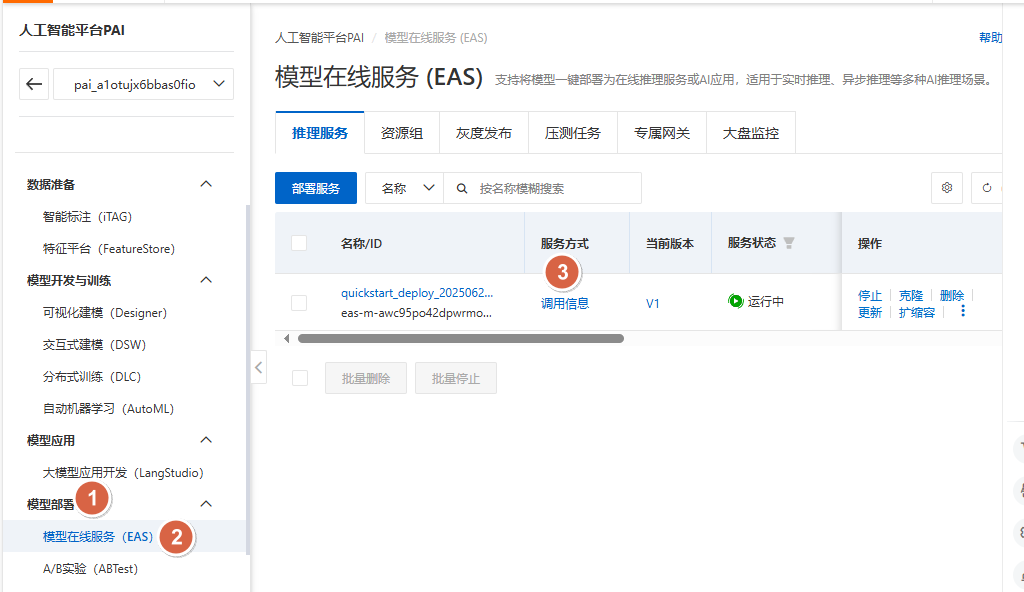
这里要重点记录两类信息:
- 公网调用地址:例如
http://<your-pai-endpoint> - Token:例如
<your-token>
发布博客时,建议不要直接写真实 Token,而是用占位示例。
3.2 用 Chatbox 调用服务¶
下载地址:
https://chatboxai.app/zh
步骤 1:下载并安装 Chatbox¶
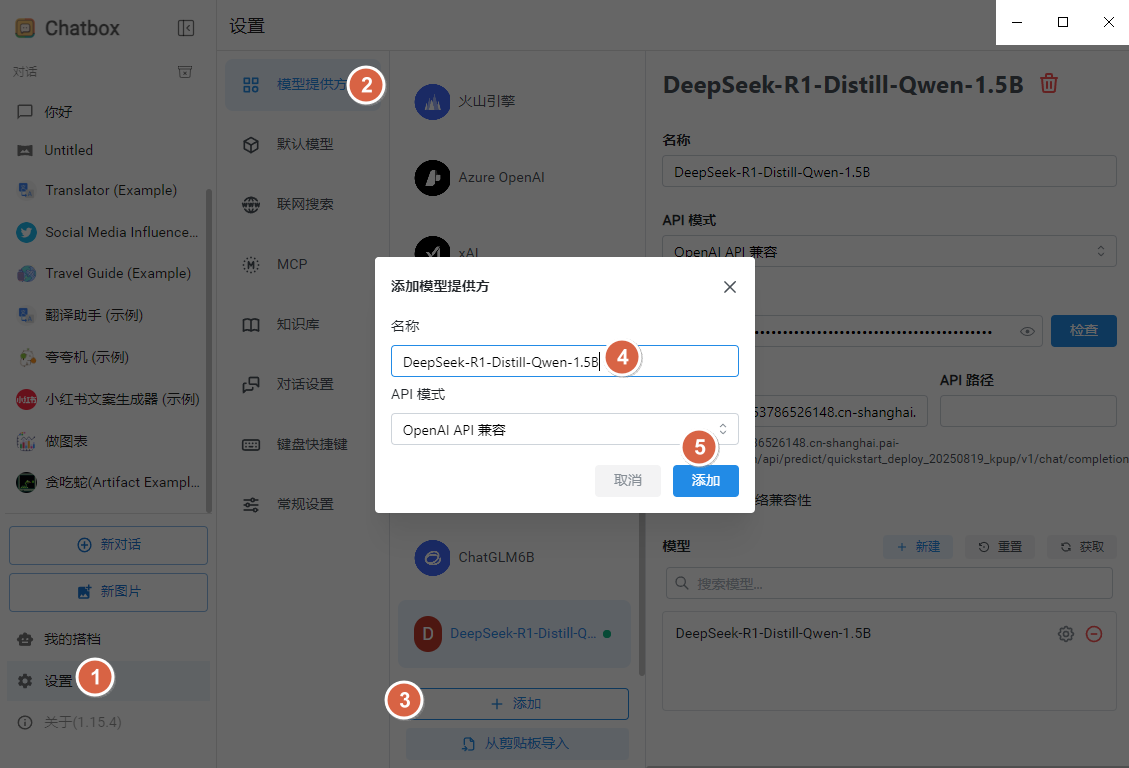
步骤 2:添加模型提供方¶
打开 Chatbox 后,依次进入:
设置 -> 模型提供方 -> 添加
把名称定义为你部署的模型名,例如 DeepSeek-R1-Distill-Qwen-1.5B。
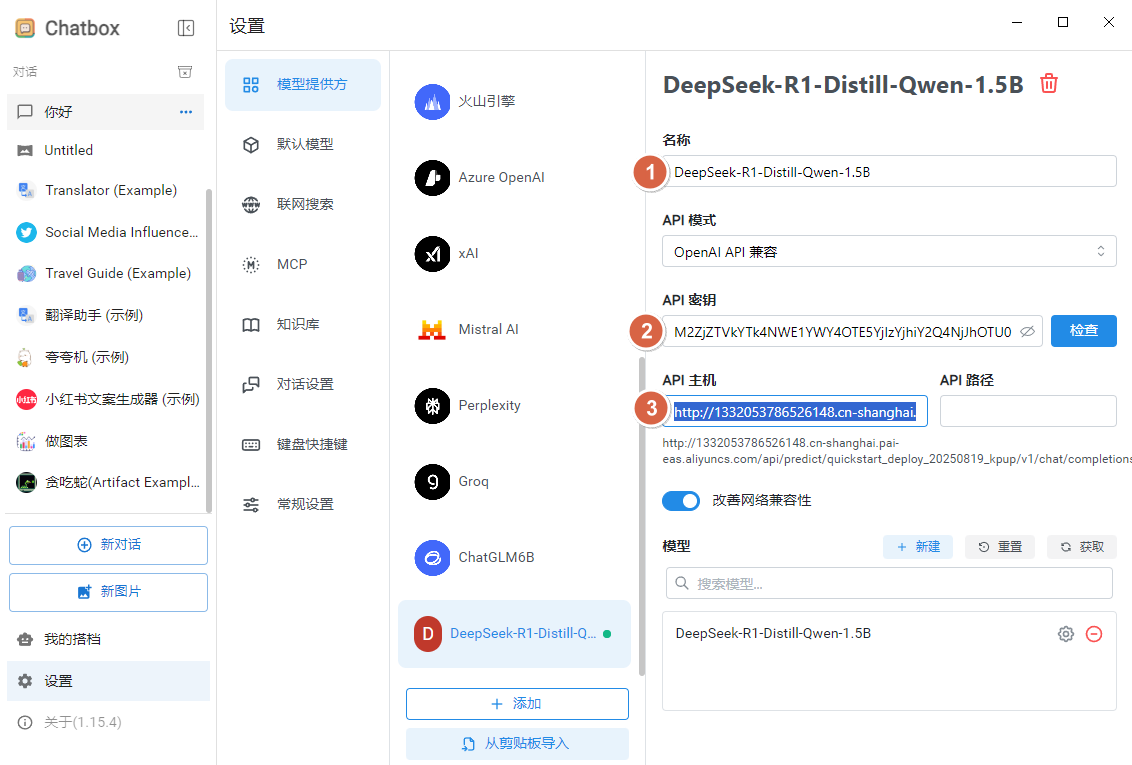
步骤 3:填写 API 信息¶
- API 主机:填写 PAI 提供的公网调用地址。
- API 密钥:填写对应 Token。
步骤 4:编辑模型并测试¶
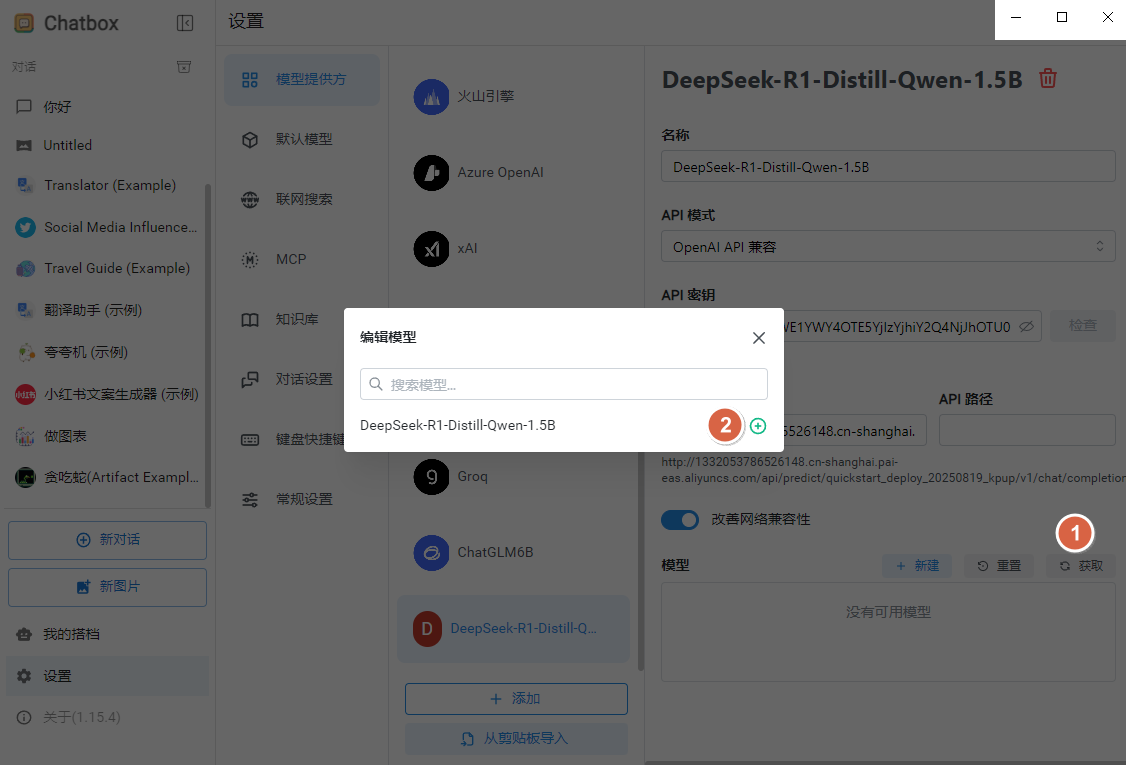
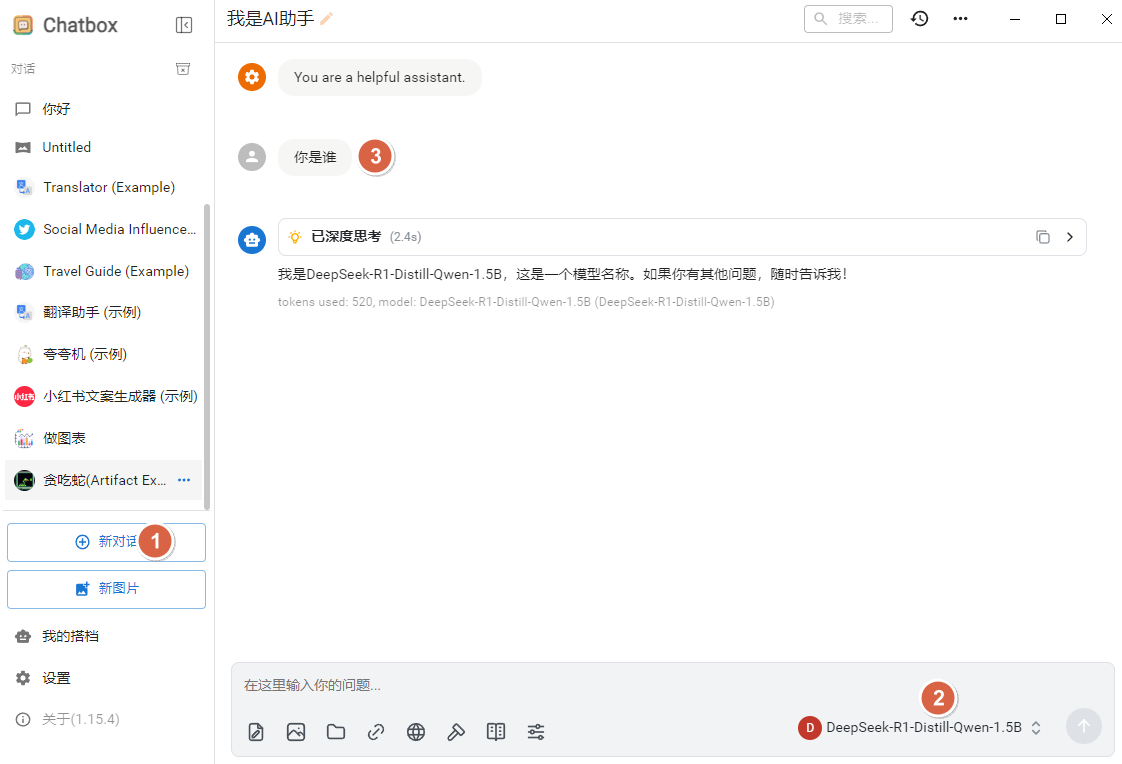
新建对话后,选择该模型,输入一个简单问题,例如“你是谁”,就可以验证服务是否连通。
3.3 方法二:ModelScope 模型部署¶
另一条路径是:
模型部署 -> 模型在线服务 -> ModelScope 模型部署
如果你更习惯在阿里云体系里直接完成模型托管,这种方式也可以作为备选。
四、适合谁先用 PAI 试水¶
如果你的目标是先把模型服务跑起来,再去验证接口调用、前端接入和推理效果,那么阿里云 PAI 这种托管式方案很适合做第一步。它的优势不在于可玩性最高,而在于上手快、试错成本更低。