

一、先配置训练器¶
示例里使用的是 SFTTrainer:
from trl import SFTTrainer
from transformers import TrainingArguments
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False,
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
args=TrainingArguments(
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
warmup_steps=10,
max_steps=80,
learning_rate=5e-5,
fp16=not torch.cuda.is_bf16_supported(),
bf16=torch.cuda.is_bf16_supported(),
logging_steps=5,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
data_collator=data_collator,
)
二、几个关键超参数怎么理解¶
gradient_accumulation_steps:- 用梯度累积模拟更大的 batch。
warmup_steps:- 训练初期逐步升高学习率,让训练更稳定。
logging_steps:- 控制日志记录频率。
optim="adamw_8bit":- 用 8 位优化器节省显存。
weight_decay:- 抑制过拟合。
lr_scheduler_type="linear":- 使用线性学习率衰减。
三、启动训练¶
trainer.train()
如果你想把这套流程写成一个完整脚本,笔记里的核心结构如下:
- 先加载 Qwen3-4B;
- 再配置 LoRA;
- 然后加载并格式化数据集;
- 再用
SFTTrainer启动训练; - 训练完成后保存适配器和合并模型。
四、保存微调结果¶
4.1 保存 LoRA 适配器¶
model.save_pretrained("qwen3_lora_finetuned")
tokenizer.save_pretrained("qwen3_lora_finetuned")
4.2 保存合并后的新模型¶
model.save_pretrained_merged(
"/models/Qwen3-4B-Aminglinux",
tokenizer,
save_method="merged_16bit",
)
五、推理测试¶
笔记里给了一个简单 JSON 文件示例,用来准备多条问答样本:
import json
data = [
{"input": "What's 1+1?", "output": "2"},
{"input": "Define AI.", "output": "AI is the simulation of human intelligence in machines."}
]
with open("qa_dataset.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
这类小样本文件比较适合快速做推理验证。
六、用 vLLM 加载微调后的模型¶
6.1 安装 vLLM¶
pip3 install vllm openai
6.2 启动服务¶
vllm serve /models/Qwen3-4B-Aminglinux/ \
--served-model-name Qwen3-Aminglinux \
--max-model-len 4096 \
--port 8000
如果使用的是 AutoDL,还需要把 8000 端口映射到本地。
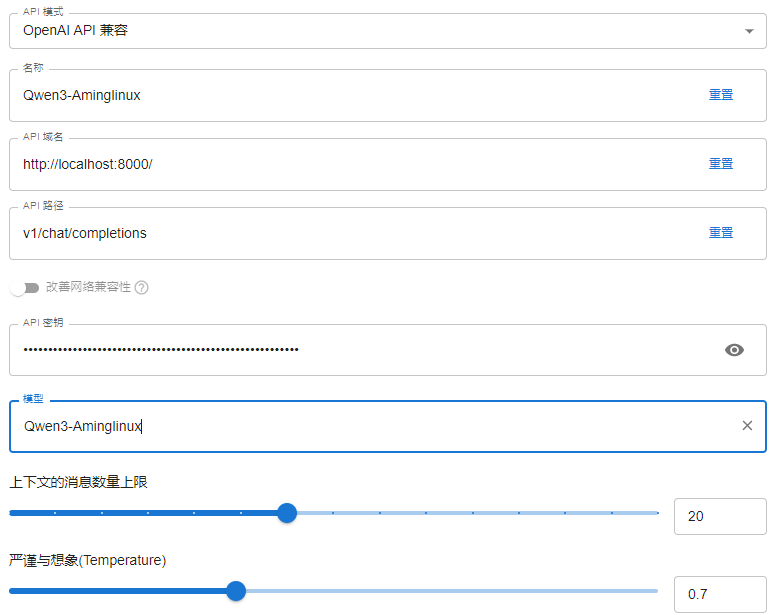
6.3 用 Chatbox 连接服务¶
接好端口映射后,就可以用 Chatbox 连接这个微调后的模型服务。
七、Unsloth 这条路线为什么值得学¶
Unsloth 的价值不只是“省显存”,更重要的是它让单卡环境也能比较顺畅地完成大模型微调。从实验验证到服务化落地,这条路线对个人开发者和中小团队都很友好。