

一、先看硬件和软件要求¶
1.1 硬件要求¶
- GPU:至少 10GB 显存,例如 T4、V100 或更高。
- 内存:至少 16G。
- 存储:建议 50G 以上。
1.2 软件环境¶
- Linux(推荐 Ubuntu)
- Python 3.8 或更高
- 匹配 GPU 的 CUDA 版本
- Anaconda 或 Miniconda
二、可选:开启 Jupyter Notebook¶
如果你想用 Notebook 方式调试和训练,可以先准备 Jupyter。
2.1 创建环境并安装 Jupyter¶
conda create -n unsloth_env python=3.10
conda activate unsloth_env
pip install jupyter
2.2 生成配置文件与密码¶
jupyter notebook --generate-config
jupyter notebook password
然后编辑配置文件,例如:
c.ServerApp.allow_root = True
c.ServerApp.ip = '0.0.0.0'
c.ServerApp.port = '8899'
c.ServerApp.open_browser = False
c.ServerApp.password = '<your-argon2-hash>'
2.3 启动 Jupyter¶
nohup jupyter notebook > jupyter.log 2> jupyter.log &
浏览器访问:
http://ip:8899
如果使用的是 AutoDL,同样需要做自定义服务映射。
三、安装 Unsloth¶
3.1 创建环境¶
如果前面没有准备 Jupyter 环境,这一步仍然要做:
conda create -n unsloth_env python=3.10
conda activate unsloth_env
3.2 安装依赖¶
pip install unsloth
pip install transformers datasets trl peft bitsandbytes
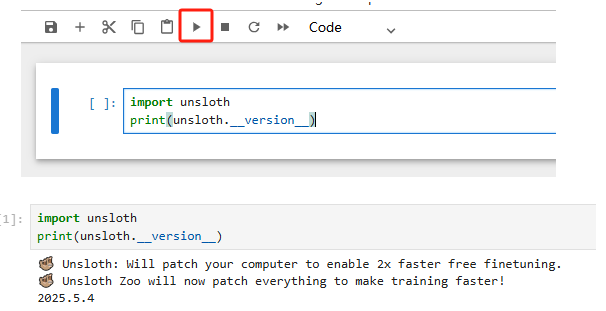
3.3 验证安装¶
在 Jupyter 中运行:
import unsloth
print(unsloth.__version__)
四、下载并加载 Qwen3-4B¶
4.1 下载模型¶
pip install modelscope
mkdir -p /models/
modelscope download --model Qwen/Qwen3-4B --local_dir /models/Qwen3-4B
4.2 加载模型¶
from unsloth import FastLanguageModel
import torch
model_name = "/models/Qwen3-4B"
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
local_files_only=True,
)
关键参数说明¶
max_seq_length=2048:- 适合作为第一次测试的起点。
dtype=None:- 让 Unsloth 自动判断更适合
float16还是bfloat16。 load_in_4bit=True:- 用 4-bit 量化减少显存消耗,更适合快速验证。
4.3 微调前先做原始模型测试¶
FastLanguageModel.for_inference(model)
inputs = tokenizer(
["Instruction: 你是脑筋急转弯专家,请回答我的问题:什么东西力气再大也不愿意扛?"],
return_tensors="pt"
).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
五、配置 LoRA 适配器¶
model = FastLanguageModel.get_peft_model(
model,
r=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha=64,
lora_dropout=0.2,
bias="none",
use_gradient_checkpointing=False,
random_state=3407,
)
5.1 关键参数怎么理解¶
r:- 控制 LoRA 适配器复杂度,越大越强,但资源占用也更高。
lora_alpha:- 通常可以设置成
r * 2。 target_modules:- 指定哪些层参与 LoRA 微调。
lora_dropout:- 防止过拟合,小数据集可以适当调高。
use_gradient_checkpointing:- 用计算换显存。
random_state:- 保证实验可复现。
六、加载并格式化数据集¶
示例里用的是脑筋急转弯数据集:
https://modelscope.cn/datasets/helloworld0/Brain_teasers/files
假设数据集上传到了:
/models/datasets/data.json
先加载:
from datasets import load_dataset
dataset = load_dataset("json", data_files="/models/datasets/data.json", split="train")
再格式化:
train_prompt_style = """下面是一个脑筋急转弯问题,请提供合适的答案,不需要提供思考过程。
### 指令:
你是一个脑筋急转弯专家,请回答以下问题,不需要提供思考过程。
### 问题:
{}
### 回复:
{}"""
def formatting_prompts_func(examples, eos_token):
inputs = examples["instruction"]
outputs = examples["output"]
texts = []
for inputs, outputs in zip(inputs, outputs):
text = train_prompt_style.format(inputs, outputs) + eos_token
texts.append(text)
return {"text": texts}
dataset = dataset.map(
formatting_prompts_func,
batched=True,
fn_kwargs={"eos_token": tokenizer.eos_token},
)
七、为什么这一步很关键¶
Unsloth 的训练效率很大程度上建立在“模型加载正确、LoRA 配置合理、数据格式统一”这三个前提上。前面这几步做稳了,后面的训练和部署才会顺畅。