

一、什么是 RAG¶
RAG 是 Retrieval-Augmented Generation 的缩写,中文通常翻译为“检索增强生成”。
它的核心思路非常直接:
- 用户先提出问题;
- 系统先去外部知识库里检索相关内容;
- 再把检索结果连同原始问题一起交给大模型;
- 最终让模型基于这些外部证据生成答案。
这意味着,模型回答时不再只依赖训练阶段学到的“固化知识”,而是能借助最新、最具体、最私有的资料来作答。
二、RAG 主要解决了哪些问题¶
2.1 知识过时¶
传统大模型的知识停留在训练数据截止时间点之后,对于后续更新的新闻、产品文档和企业内部资料并不了解。
RAG 通过连接动态知识库,让模型能基于新资料回答问题。
2.2 幻觉和事实错误¶
大模型很容易生成“看起来像真的,但其实是编的”内容。
RAG 的价值在于把回答锚定在检索到的文档片段上,显著提高事实性。
2.3 缺少可追溯性¶
纯大模型回答常常很难解释“答案从哪来”。
RAG 可以把答案和具体文档片段关联起来,更利于验证和审查。
2.4 不懂私有知识¶
企业内部文档、员工手册、客户资料、行业专有知识,通常不会出现在通用预训练语料里。
RAG 可以直接利用这些私有资料,而不需要重新训练整个模型。
2.5 更新成本高¶
如果每次知识更新都靠微调或重训大模型,成本会非常高。
RAG 把知识放在外部知识库里,后续只需要更新知识库,不必频繁改模型参数。
三、RAG 的核心工作流程¶
RAG 一般可以拆成三个核心步骤:
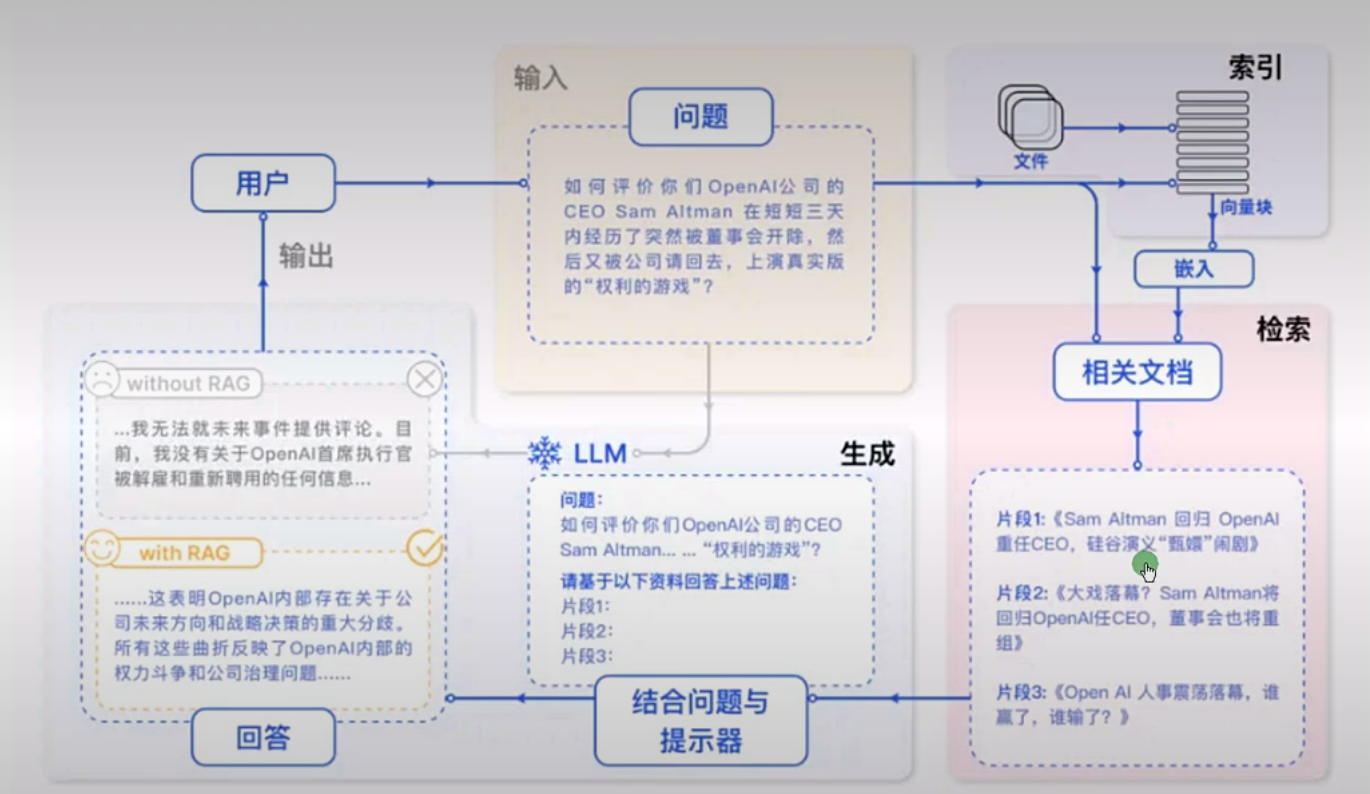
3.1 检索¶
先把用户问题转换成向量,再去知识库里寻找最相关的若干文档片段。
这一步的关键技术包括:
- 向量嵌入模型;
- 向量数据库;
- 相似度计算;
- Top-K 检索。
3.2 增强¶
把检索出来的文档片段和用户问题拼接成一个新的 Prompt,交给大模型。
一个常见模板可以理解为:
基于以下上下文回答问题:
上下文:{检索到的文档片段}
问题:{用户问题}
答案:
3.3 生成¶
大模型读取这个增强后的 Prompt,再结合上下文生成最终答案。
也就是说,模型负责“理解与表达”,而知识库负责“提供证据”。
四、为什么 RAG 比单纯聊天更适合企业场景¶
因为企业真正需要的通常不是泛泛而谈,而是:
- 基于自己的文档回答;
- 基于最新资料回答;
- 能引用来源;
- 能随着知识更新快速调整。
这些恰好都是 RAG 的强项。
五、一个实用理解¶
如果把纯大模型看成一个“知识固定但表达能力很强的专家”,那 RAG 就像是给这个专家配上了一套可以实时翻阅资料的工作台。它不一定改变专家本身,但会明显提高答题时的可靠性。