

一、RAG 的典型架构¶
一个比较完整的 RAG 架构,通常包含三块能力:
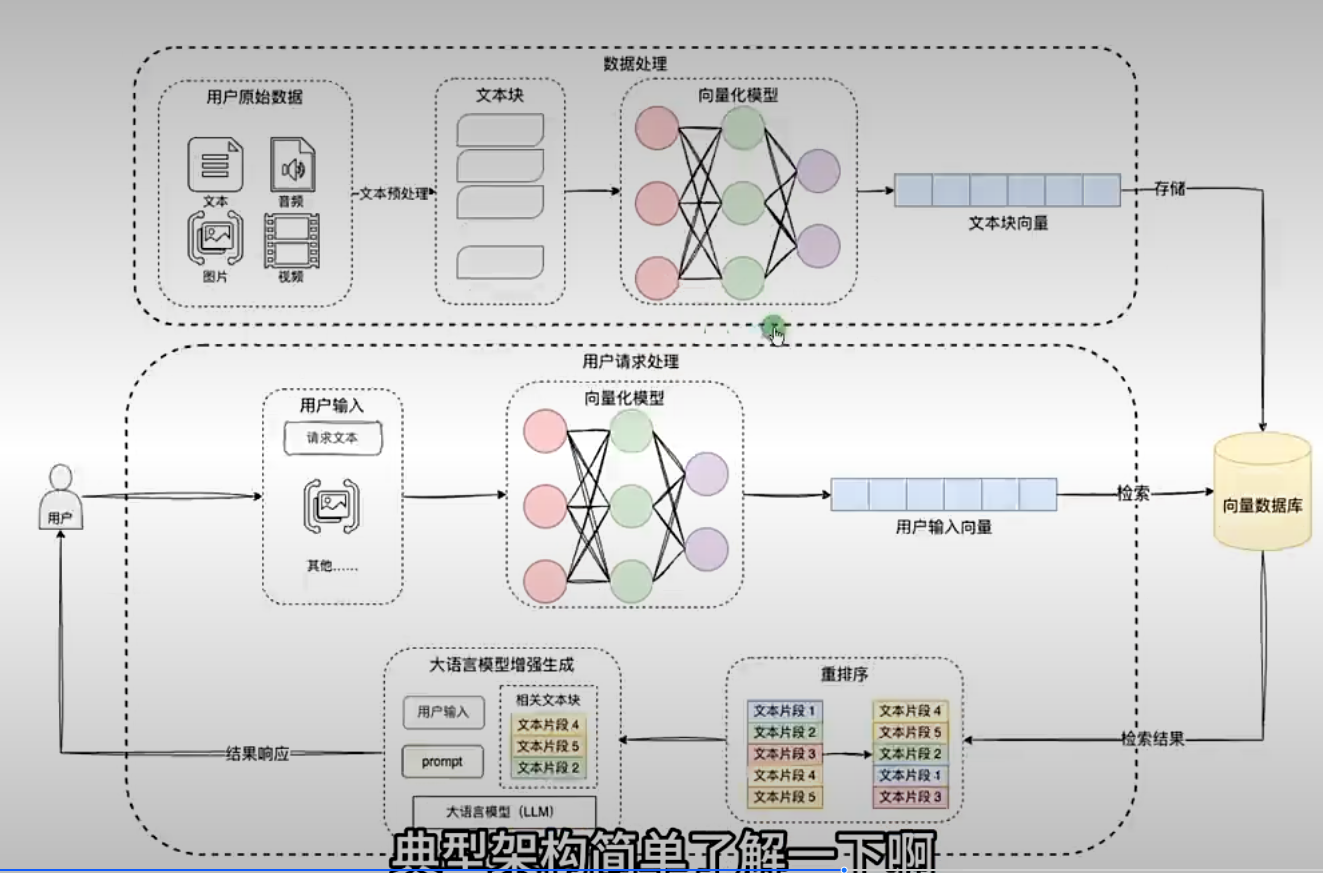
1.1 知识库内容整理¶
文档不会直接原样扔进系统,而是要先切分成适合检索的片段。
常见切分方式包括:
- 固定字数切分;
- 按段落切分;
- 重叠切分;
- 父子片段切分;
- 更高级的语义切分。
切分质量会直接影响后面检索是否精准。
1.2 检索与优化¶
这一步一般由向量数据库负责语义检索,再通过额外机制优化候选结果。
1.3 增强生成¶
最后再把检索片段组织成 Prompt,让大模型在这些上下文基础上生成回答。
二、为什么要做 Rerank¶
RAG 里最容易被低估的一步,就是 Rerank,也就是“重排序”。
它的作用是:在初步检索出一批文档之后,再用更精细的方式把这些结果重新排一遍,把最适合当前问题的内容顶到前面。
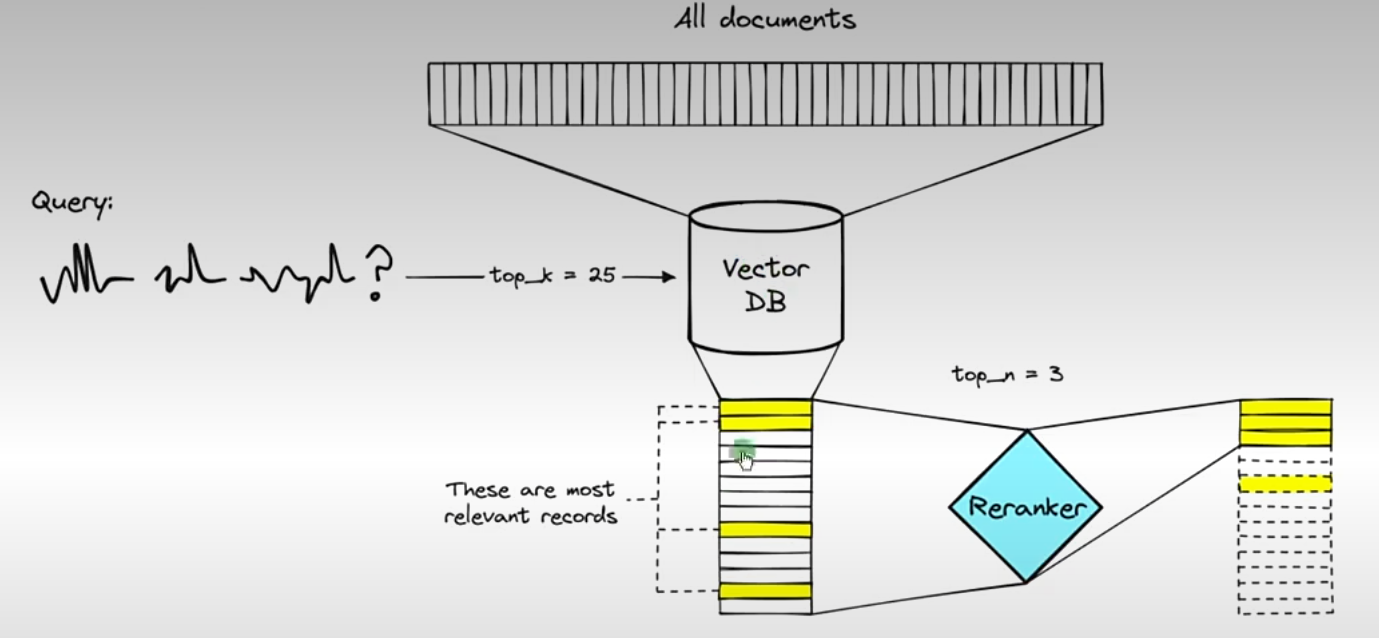
三、如果不做 Rerank,会遇到什么问题¶
初步检索通常有几个常见问题:
- 召回结果相关但不够精准;
- 候选文档里混入噪声;
- 最有用的片段不一定排在最前;
- 大模型对输入顺序很敏感,顺序错了,答案质量也会跟着掉。
Rerank 的价值,就是在生成前再精修一次候选结果。
四、Rerank 为什么常常能明显提升效果¶
研究和工程实践里,加入 Rerank 往往能显著提升回答质量。因为它本质上解决的是“召回够不够精准”的问题,而这个问题恰恰是很多 RAG 误答的主要来源。
一个很直观的比喻是:
开卷考试时,资料翻出来了,但不一定翻到了最相关的那几页。Rerank 就是在正式答题前,再帮你把最有价值的页码排到最前面。
五、常见 Rerank 模型¶
Rerank 往往需要单独的模型,或者通过微调让普通模型具备重排序能力。
| 模型/库名称 | 类型 | 特点 |
|---|---|---|
BAAI/bge-reranker-base/large |
交叉编码器 | 开源常用方案,中英文都比较实用 |
Cohere Rerank API |
交叉编码器 | 商业 API,易用、效果稳定 |
cross-encoder/ms-marco-MiniLM-L-12-v2 |
交叉编码器 | 精度与效率平衡得很好 |
cross-encoder/ms-marco-electra-base |
交叉编码器 | 精度通常更高,但开销更大 |
ColBERT / ColBERTv2 |
后期交互 | 精度高、效率也不错,但存储开销更大 |
SentenceTransformers.CrossEncoder |
框架 | 便于在 Python 中快速接入交叉编码器模型 |
rank_llm / rank_zephyr |
LLM-as-Rerank | 用大模型做排序,灵活但成本更高 |
六、怎么选 Rerank 方案¶
6.1 先看预算和延迟¶
- 预算和延迟都比较紧:
- 先选轻量交叉编码器。
- 更追求效果:
- 可以用更大的 reranker 或 LLM-as-Rerank。
6.2 再看语言和场景¶
- 中英文混合:
- 优先选支持中英文的开源模型。
- 高精度企业问答:
- Rerank 几乎是必做项。
6.3 最后看召回质量¶
如果初步召回本身已经很差,单靠 Rerank 救不了全部问题。这时还得回头优化:
- 切片方式;
- 向量模型;
- 检索 Top-K;
- 知识库质量。
七、一个实用判断¶
RAG 的上限通常不只取决于大模型,而更取决于“检索是否准、上下文是否干净、顺序是否合理”。从这个角度看,Rerank 并不是可有可无的锦上添花,而往往是把系统从“能用”推到“好用”的关键一步。