

一、先用命令行工具做最小监控¶
1.1 NVIDIA GPU:nvidia-smi¶
这是最基础也最常用的 NVIDIA GPU 监控工具,前提是已经安装好显卡驱动。
常见用法:
# 实时刷新
nvidia-smi --loop=2
# 查看关键指标
nvidia-smi --query-gpu=timestamp,temperature.gpu,power.draw,memory.used,utilization.gpu --format=csv
# 持续输出到文件
nvidia-smi --query-gpu=index,timestamp,power.draw,clocks,sm,memory.used --format=csv -l 1 > gpu_log.csv
它最适合做:
- 快速排查显存占用;
- 看当前 GPU 利用率;
- 看温度和功耗是否异常。
1.2 AMD GPU:rocm-smi¶
如果是 AMD GPU,常用命令通常是:
rocm-smi --showtemp
rocm-smi --showpower
rocm-smi --showmeminfo
1.3 nvtop¶
如果你希望在命令行里看到更像 top 的实时界面,nvtop 是个很方便的小工具。
apt install -y nvtop
nvtop
二、用 Prometheus 做主机指标采集¶
如果你本来就有 Prometheus 体系,那么把大模型监控接进去会非常自然。
2.1 安装 Prometheus¶
下载并解压:
wget https://github.com/prometheus/prometheus/releases/download/v3.5.0/prometheus-3.5.0.linux-amd64.tar.gz
tar zxf prometheus-3.5.0.linux-amd64.tar.gz -C /opt
cd /opt
ln -s prometheus-3.5.0.linux-amd64 prometheus
再配一个 systemd 服务:
[Unit]
Description=prometheus service
After=network.target
[Service]
User=prometheus
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -QUIT $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
如果某些环境不适合用 systemd,也可以直接命令行启动。
2.2 配置 node_exporter¶
Prometheus 本身负责拉取数据,而 node_exporter 才是暴露主机指标的组件。
安装后,在 Prometheus 的 prometheus.yml 中加入目标:
- job_name: "node"
static_configs:
- targets: ["<node-exporter-host>:9100"]
这里的地址建议都写成占位形式,不要在公开文档里保留真实内网 IP。
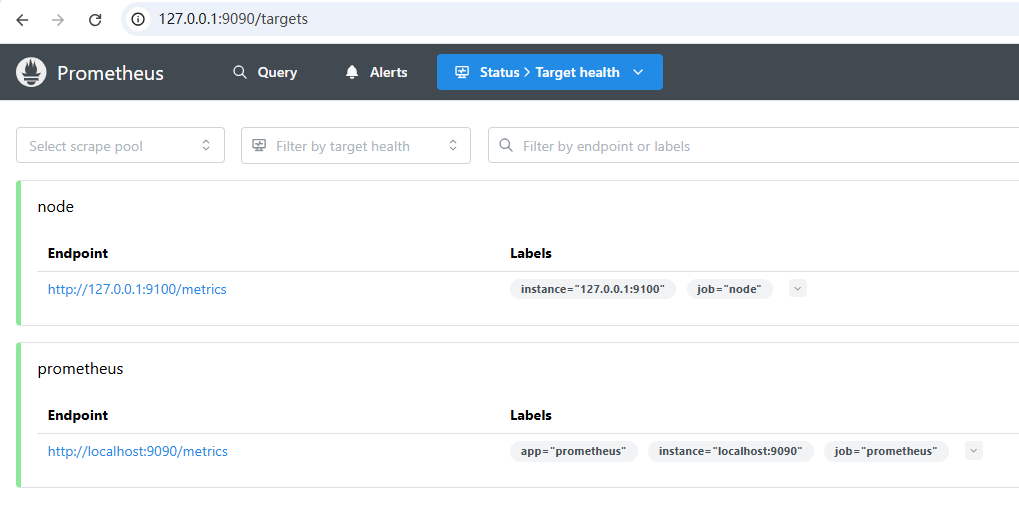
2.3 查看 Targets¶
配置完成后,可以通过:
http://<your-prometheus-host>:9090/targets
检查采集目标是否在线。
三、用 Grafana 做可视化大屏¶
Prometheus 很强,但它自带 UI 对运维来说不够直观。Grafana 的作用,就是把这些指标做成更容易读的图表和大盘。
3.1 安装 Grafana¶
wget https://dl.grafana.com/oss/release/grafana-12.1.0.linux-amd64.tar.gz
tar -zxvf grafana-12.1.0.linux-amd64.tar.gz -C /opt/
cd /opt
ln -s grafana-v12.1.0 grafana
/opt/grafana/bin/grafana server --homepath /opt/grafana >/tmp/grafana.log 2>/tmp/grafana.log &
访问方式:
http://<your-grafana-host>:3000
默认用户名和密码都是 admin,首次登录后应立即修改。
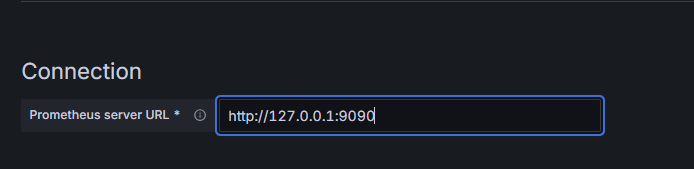
3.2 添加 Prometheus 数据源¶
在 Grafana 中选择 Prometheus 数据源,然后保存并测试。
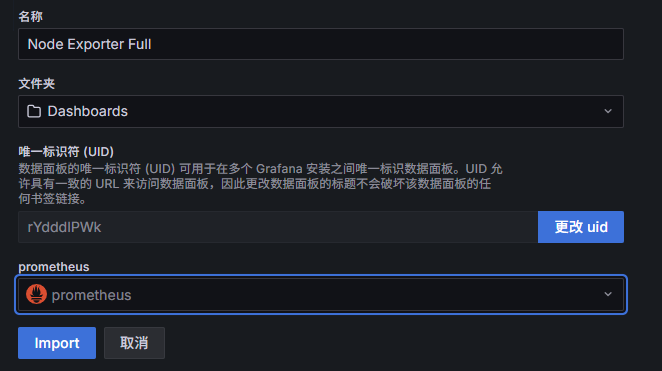
3.3 导入现成仪表盘¶
例如可以直接导入常用的节点监控仪表盘:
- Dashboard ID:
1860
四、为什么这一层监控特别重要¶
大模型平台最容易出问题的,不是“模型有没有部署成功”,而是上线后资源使用到底稳不稳。命令行工具适合排障,Prometheus 适合采集,Grafana 适合长期观察,这三层配合起来才算一个完整的监控起点。