

一、先明确整体思路¶
这套流程的目标是:在 AutoDL 云服务器上安装 LLaMA-Factory,然后对 Qwen3-4B 做微调。
二、环境准备¶
2.1 购买云主机¶
笔记里建议使用 AutoDL,选择 3090 显卡即可。如果你本地已经有 GPU 机器,也可以直接用本地环境。

2.2 准备 Conda 环境¶
AutoDL 默认已经带有 Miniconda3,可以直接创建环境:
conda create -n llama_factory python=3.10
conda activate llama_factory
# 如果上面这句有问题
source activate llama_factory
2.3 Git 与 CUDA¶
- Git:AutoDL 一般已安装,没有的话自行安装。
- CUDA:AutoDL 通常也已准备好。
三、下载并安装 LLaMA-Factory¶
3.1 克隆仓库¶
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
3.2 安装依赖¶
pip install -e .[metrics]
如果要使用 GPU,还要确认 PyTorch 与 CUDA 版本匹配:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
说明:具体的 cu118、cu117 需要按你的 CUDA 版本调整。
四、下载 Qwen3-4B 模型¶
4.1 安装 ModelScope¶
pip install modelscope
4.2 下载模型¶
mkdir -p /models/
modelscope download --model Qwen/Qwen3-4B --local_dir /models/Qwen3-4B
五、准备数据集¶
5.1 把数据文件放到 data 目录¶
例如:
LLaMA-Factory/data/my_data.json
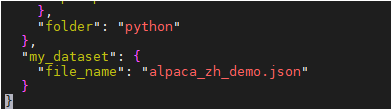
5.2 编辑 dataset_info.json¶
在 data/dataset_info.json 中增加配置,例如:
{
"my_dataset": {
"file_name": "alpaca_zh_demo.json"
}
}
说明:alpaca_zh_demo.json 是框架内置的测试数据集名称,你也可以替换成自己的数据文件。
六、微调前先做模型测试¶
先别急着训练,先验证模型是否能正常加载。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /models/Qwen3-4B \
--template qwen
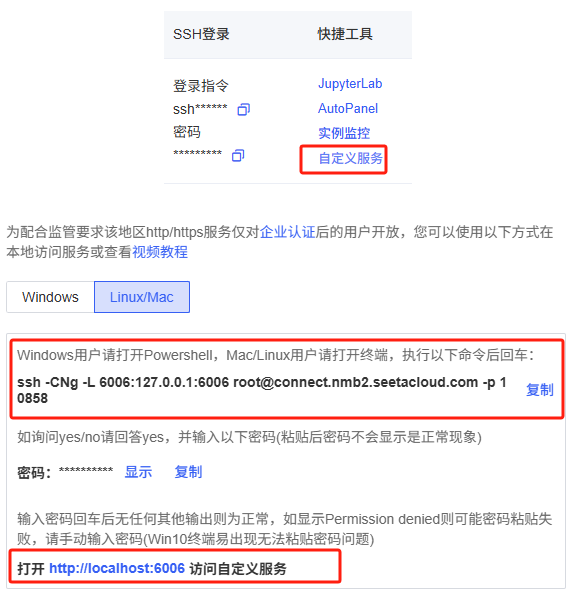
这条命令会监听 7860 端口。
如果你使用的是 AutoDL,还需要配置自定义服务,把端口映射出来。
七、为什么这一步不能省¶
环境、模型、数据配置任何一个环节出错,都会让后面的训练白跑。先把“模型能加载、端口能访问、数据能识别”这三件事确认好,再进入正式训练,效率会高很多。